تصور کنید عامل هوش مصنوعی سیستمعامل شما بهجای وقفهٔ ۷ ثانیهای، در لحظه و با دقت بالا پاسخ دهد. این دیگر یک چشمانداز دور نیست؛ زیرا طبق اعلام شرکت H در ۲ ژوئن ۲۰۲۶، اکنون میتوان زمان پاسخگویی پایانبه-پایان (End-to-End) عاملهای محلی را تا ۵۰٪ کاهش داد.
این تغییر مسیر، کنترل عاملمحور (Agentic) را از ابر به لبه منتقل میکند و پروفایل حریم خصوصی و هزینهٔ اتوماسیون دسکتاپ را بهطور بنیادین تغییر میدهد. همانطور که در تحلیلهای پیشین ما دربارهی رایانش لبه (Edge Computing) اشاره کردیم، حذف وابستگی به سرورهای مرکزی، کلید دستیابی به امنیت داده در محیطهای سازمانی است.
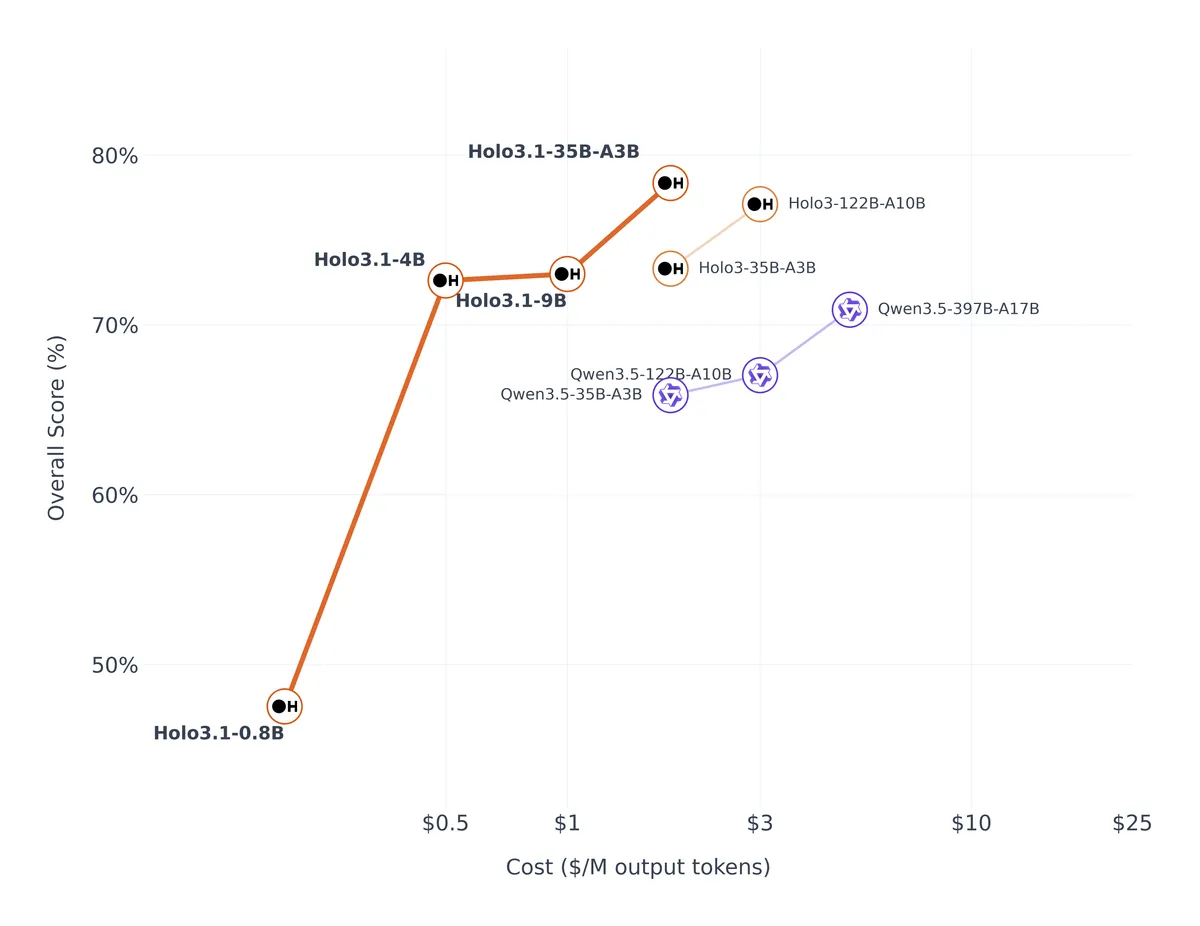
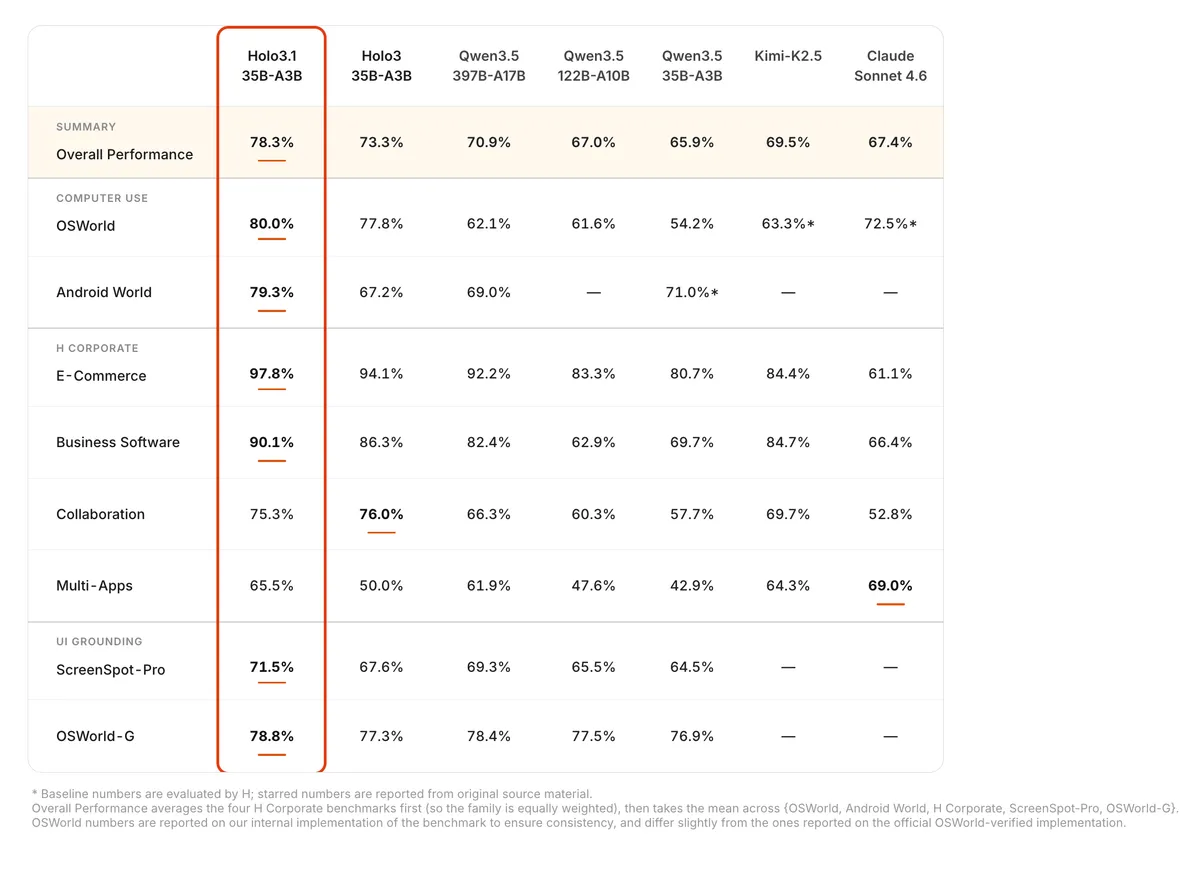
خانواده Holo3.1 که بر پایه معماری Qwen توسعه یافته، در چهار اندازه برای ایجاد تعادل بین هزینه و عملکرد عرضه شده است: ۰.۸ میلیارد، ۴ میلیارد، ۹ میلیارد و ۳۵ میلیارد (A3B) پارامتر. برای ممکن ساختن اجرا بر روی سختافزارهای مصرفکننده، این تیم نسخههای کوانتایزیشن (Quantization) شده در قالبهای FP8، Q4 GGUF و NVFP4 را منتشر کرده است.
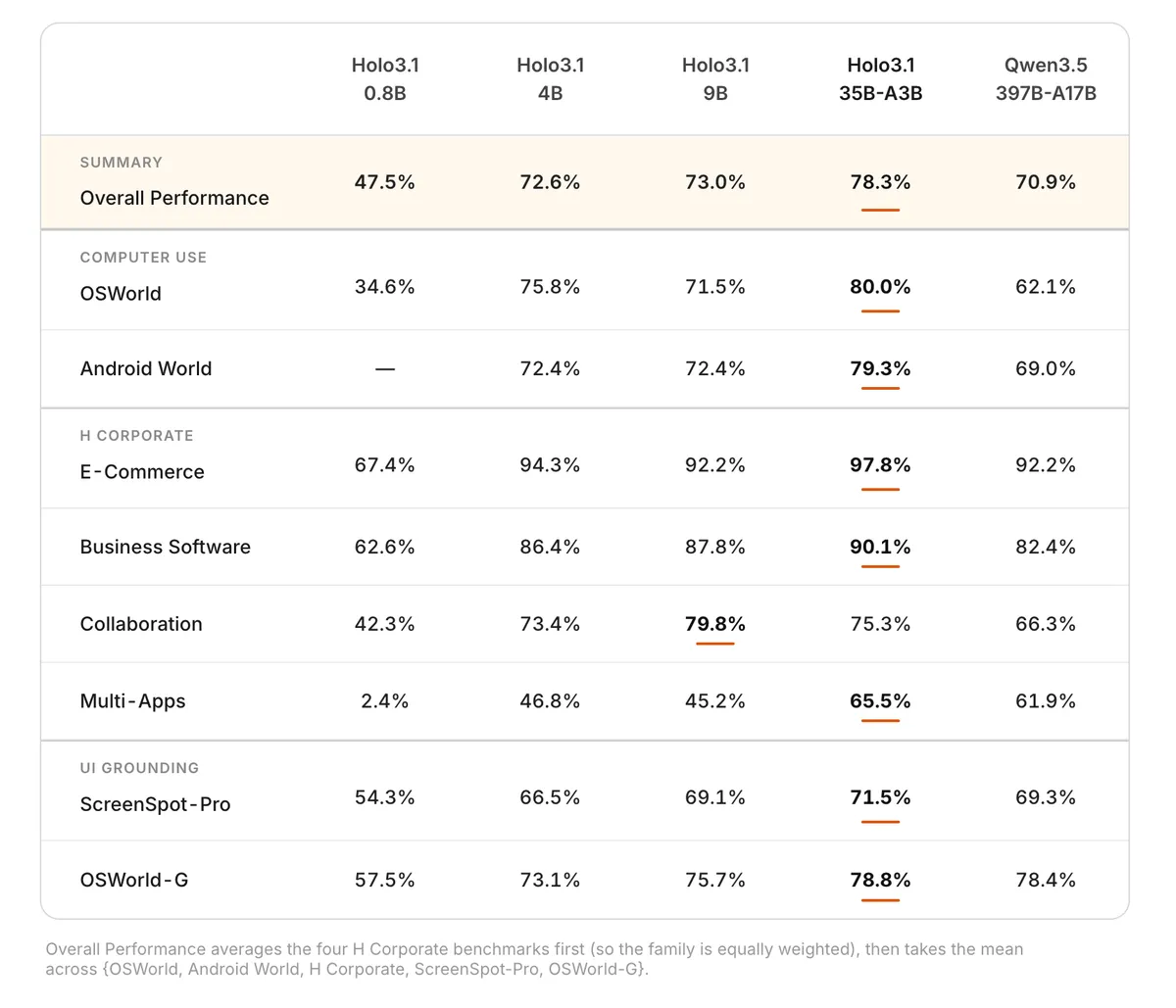
به گزارش شرکت H، بیشترین بهبود در اتوماسیون موبایل دیده میشود. در بنچمارک AndroidWorld، مدل ۳۵ میلیارد پارامتری از نرخ موفقیت ۶۷٪ به ۷۹.۳٪ رسید. همچنین نسخههای کوچکتر ۴ و ۹ میلیاردی، بهبود چشمگیری از ۵۸٪ به ۷۲٪ داشتند.
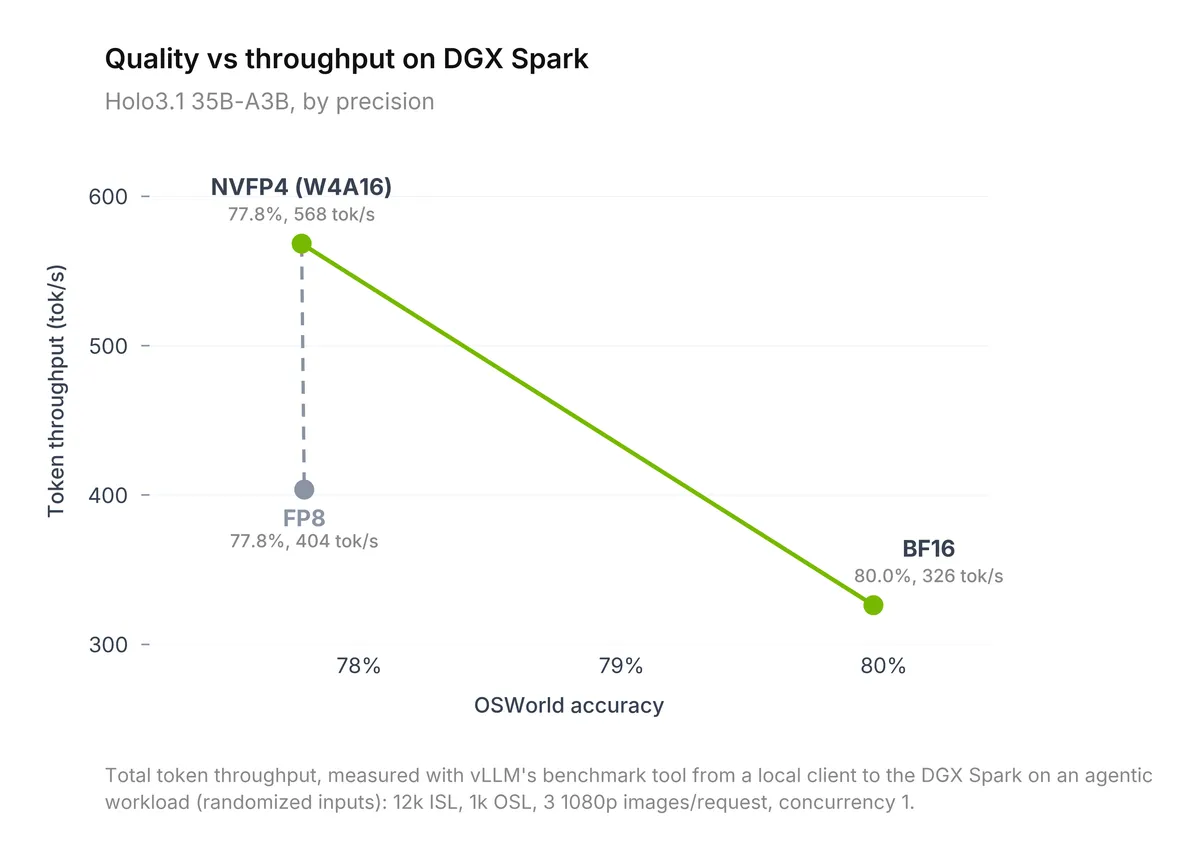
در زمینه سرعت استنتاج (Inference)، بر اساس مستندات فنی، استفاده از NVFP4 (در پیکربندی W4A16 با بهینهساز مدل انویدیا) روی سختافزار DGX Spark، توان پردازشی توکنها را ۱.۷۴ برابر BF16 افزایش میدهد.
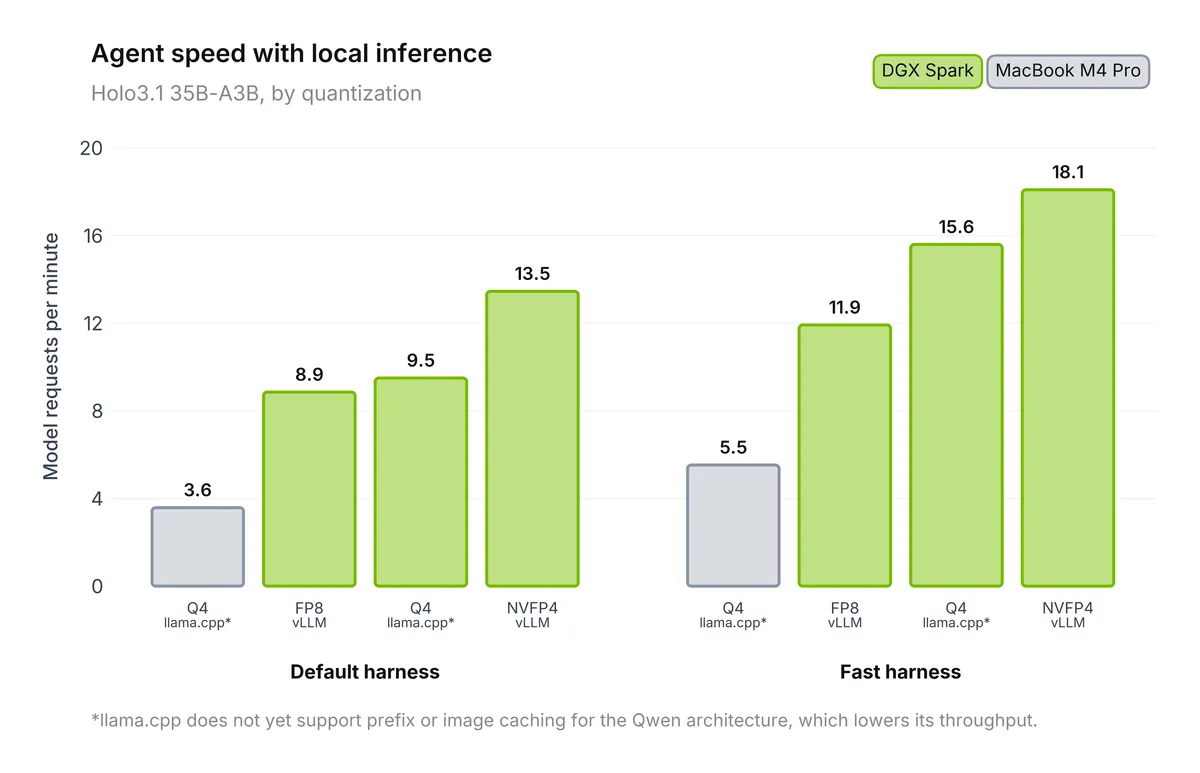
با انتشار وزنهای GGUF و NVFP4، شرکت H روی این فرضیه شرطبندی کرده است که مرز بعدی عاملهای هوش مصنوعی، نه فقط استدلال بهتر، بلکه «پایداری استقرار» (Deployment Robustness) است. انتقال مدل به شبکه کاربر، «مالیات ابری» را حذف کرده و امکان فراخوانی توابع بومی را با عملکردی نزدیک به JSON ساختاریافته فراهم میکند.
گام بعدی شما
- توسعهدهندگان باید منتظر انتشار رسمی Harness عامل دسکتاپ باشند که ادغام وزنهای محلی با سیستمعامل را بهینه میکند.
- برای کاهش هزینهها، مدلهای ۴ میلیاردی را در محیطهای محدود به جای مدلهای حجیم تست کنید.
- بررسی سازگاری سختافزار خود با فرمت NVFP4 برای دستیابی به حداکثر سرعت استنتاج.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell و تاثیر آن بر مدلهای محلی مراجعه کنید.



گفتگو