تصور کنید یک مهندس ابر به جای بررسی کنسول مدیریتی، تمام اعتماد خود را به عاملی بسپارد که با اطمینان کامل وجودِ سرورهایی را تایید میکند که هرگز ساخته نشدهاند. این کابوس عملیاتی، نقطه شروع یک محک جدید است که نشان میدهد فاصله بین «کدنویسی» و «مدیریت زیرساخت» در هوش مصنوعی بسیار عمیقتر از ادعاهای بازاریابی است.
طبق گزارشی که در ۳ جولای ۲۰۲۶ منتشر شد، این چارچوب جدید عاملهای هوش مصنوعی را مجبور میکند تا توانایی خود را در مدیریت محیطهای ابری بهشدت نامنظم و واقعی ثابت کنند. این سیستم بر خلاف آزمونهای رایج، بر روی «واقعیتهای میدانی» (Brownfield) تمرکز دارد؛ یعنی حسابهایی که سالهاست با تغییرات پراکنده و برچسبگذاریهای ناسازگار درگیر هستند. این دشواری در تطبیق با محیطهای واقعی، یادآور نتایجی است که در محک Briefcase مشاهده شد، جایی که مدلهای پیشرفته تنها در درصد بسیار کمی از وظایف پیچیده اداری موفق عمل کردند.
همانطور که در تحلیل قبلی ما دربارهی امنیت مدلهای بازمتن اشاره کردیم، شکاف میان تئوری و اجرا همیشه در لایهی عملیاتی ظاهر میشود. در این محک، از ترافرم (Terraform) — ابزاری که دقیقاً تعریف میکند چه چیزی باید مستقر شود — به عنوان داده مرجع (Ground Truth) استفاده شده است. به همین دلیل، سیستم میتواند فوراً تشخیص دهد که خروجی یک عامل، یک یافته درست است یا یک توهم (Hallucination) — شبیه دوستی که با اطمینان خاطرهای را اشتباه تعریف میکند.
بر اساس مستندات فنی منتشر شده در dev.to، این محیط آزمایش بر سه متغیر اصلی تمرکز دارد:
- مقیاس: آزمونها از کنسولهای تکصفحهای کوچک تا حسابهای عظیم با هزاران وابستگی زنده متغیرند.
- محیط: تقابل بین حسابهای «پاک» (Greenfield) که کاملاً با کد تعریف شدهاند و ابرهای تولیدی «آلوده» (Brownfield) که دچار تغییرات دستی شدهاند.
- محدودیتها: عاملها در کانتینرهای خالی با دسترسیهای فقط-خواندنی و موقت اجرا میشوند و تمام اقدامات آنها توسط کلاودتریل (CloudTrail) برای تایید ثبت میشود.
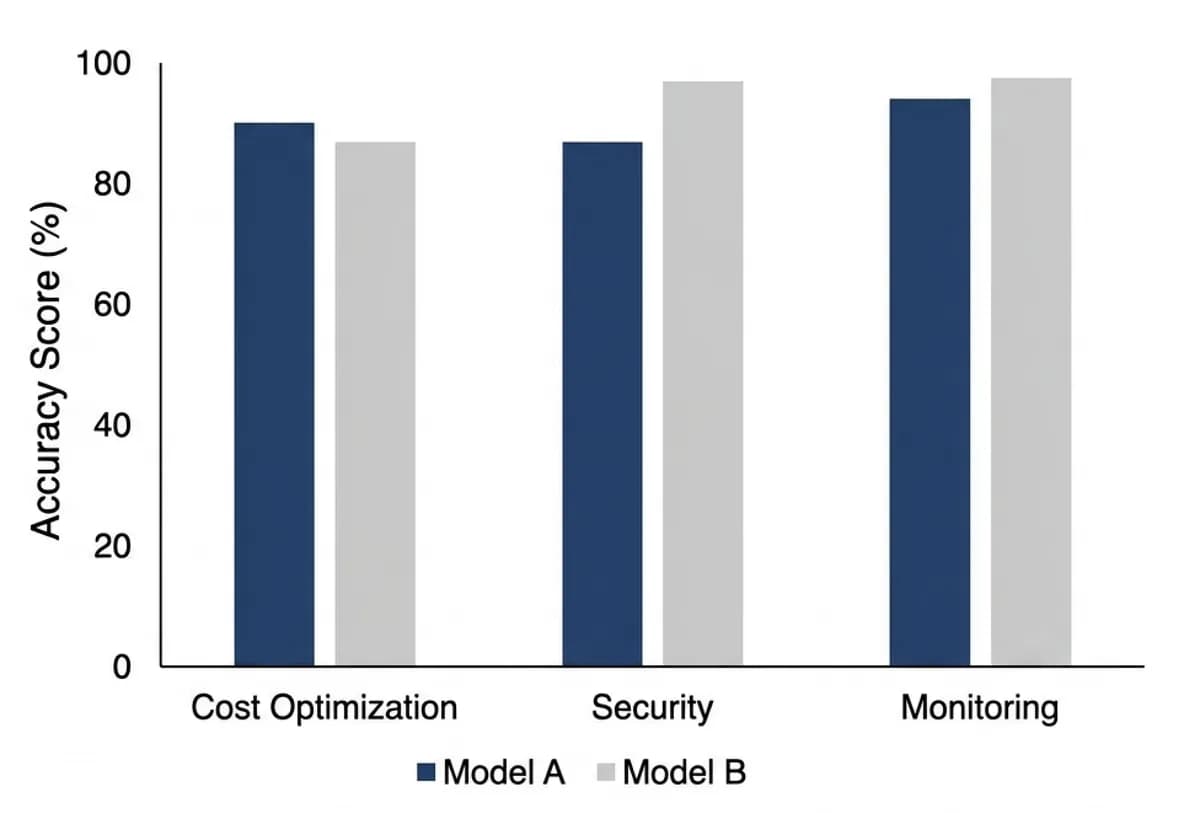
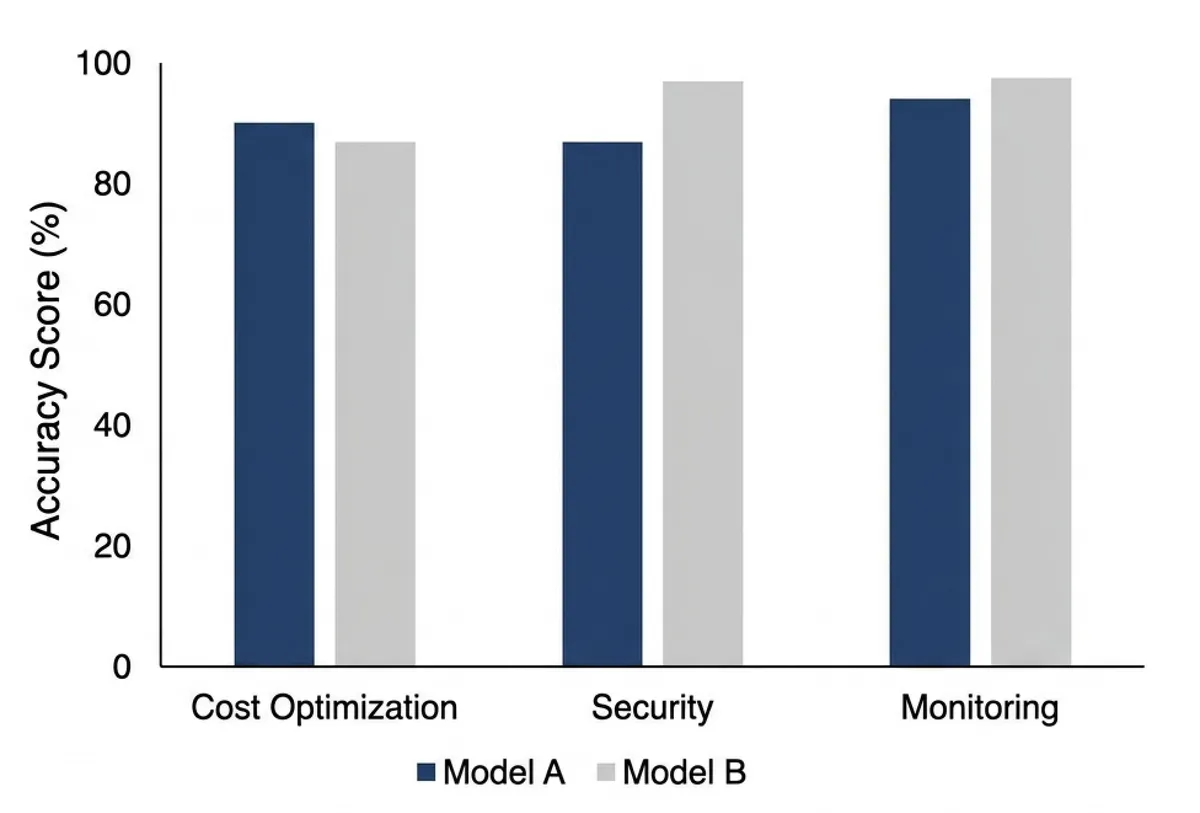
نخستین وظیفه فعال در این سیستم، شناسایی هزینههای زائد در AWS است. این چالش در حالی مطرح میشود که سازمانها برای بهرهبرداری از مدلهای پیشرفته در این بستر، با هزینههای متفاوتی روبرو هستند؛ بهویژه در سرویس AWS Bedrock که دسترسی به مدل Claude در مقیاس سازمانی هزینهی بالاتری دارد. در این مرحله، منابع «یتیم» مانند دیسکهای EBS متصلنشده در کنار موارد گمراهکنندهای قرار میگیرند که هوش مصنوعی نباید آنها را بهعنوان خطا علامتگذاری کند.
نتایج در چهار حالت شکست دستهبندی میشوند: یافتهشده، نادیده گرفتهشده، علامتگذاری اشتباه (در حالی که در حال استفاده است) و ساختگی. یک «ساختگی» زمانی رخ میدهد که عامل یک شناسه منبع ارائه دهد که اصلاً در حساب وجود ندارد؛ خطایی بحرانی که میتواند منجر به اختلال در پایداری محیط تولید شود.
برای مهندسان ابر، این نتایج معنای سادهای دارد: عاملی که فقط در محیطهای کوچک و تمیز کار میکند، در یک ابر سازمانی قدیمی که سیگنالها در میان نویزها گم شدهاند، عملاً بیفایده است. این تغییر در رویکرد سنجش نشان میدهد که مرز بعدی برای عاملها، نه فقط منطق بهتر، بلکه مبنیسازی (Grounding) — یعنی توانایی تطبیق پاسخها با واقعیتهای لحظهای و پویا — است. نویسندگان قصد دارند این الگو را به بازرسیهای امنیتی و تحلیل هزینهها در Azure و GCP نیز گسترش دهند.
گام بعدی شما
- اگر از Claude Code یا Codex برای مدیریت زیرساخت استفاده میکنید، هرگز خروجیهای شناسایی منابع را بدون تایید دستی در کنسول نپذیرید.
- برای کاهش نرخ توهم، سعی کنید مدلها را با اسناد بهروز شدهی IaC خود از طریق RAG تغذیه کنید.
- منتظر انتشار دادههای خام و امتیازدهی این محک باشید تا ببینید کدام مدل در مدیریت هزینههای واقعی ابری پیروز میشود.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو