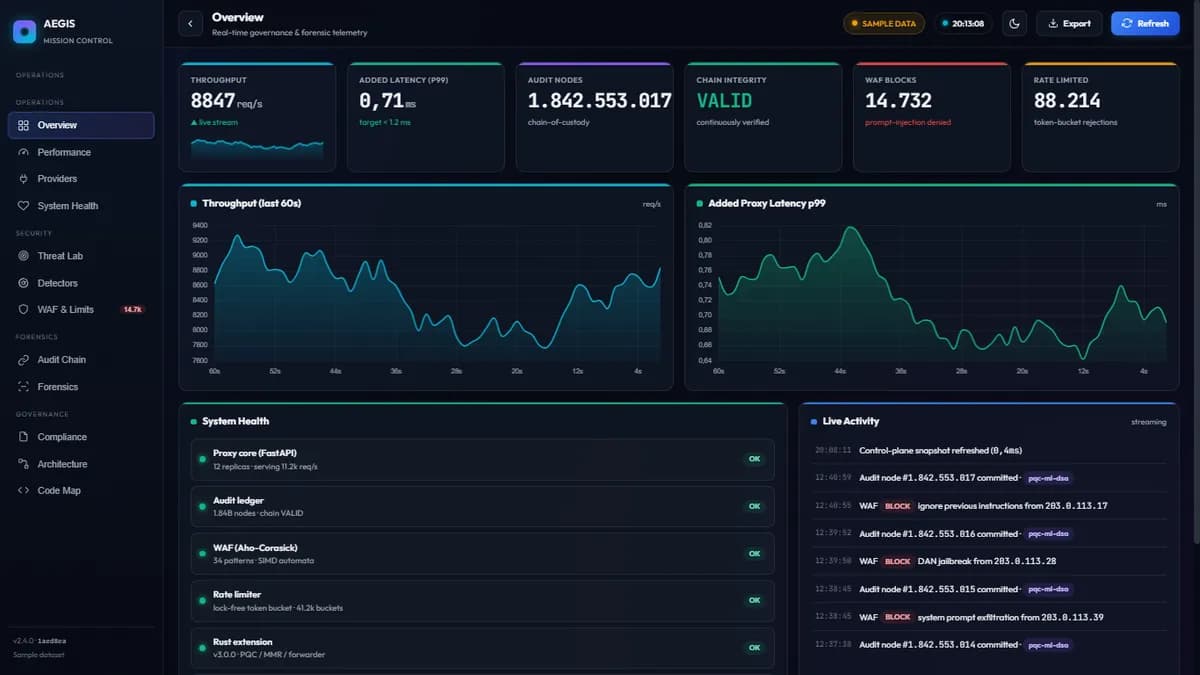
اگر برای استقرار مدلهای زبانی در محیطهای حساس و نظارتی برنامهریزی میکنید، تأخیر در لایهی گیتوی میتواند تفاوت بین یک سیستم پاسخگو و یک شکست عملیاتی باشد. Aegis توانسته است تأخیر مسیر بحرانی (Hot-path) خود را به عدد خیرهکنندهی ۲.۴۳ میکروثانیه (p50) برساند. این پروکسی حاکمیتی که با OpenAI سازگار است و به صورت متنباز عرضه شده، این رقم را از طریق جداسازی پردازش درخواستها به دو جریان مجزا به دست آورده است تا ترافیک کاربر بهطور مؤثر از وظایف سنگین حسابرسی جدا شود. این رویکرد در مدیریت ترافیک، یادآور راهکارهای بهینهسازی هزینهها در لایههای مسیریابی است؛ مشابه آنچه در بررسی کاهش هزینههای CrewAI با استفاده از لایهی مسیریابی Lynkr مشاهده شد.
زمینهی معماری
ساخت یک پروکسی امن نیازمند ایجاد توازن بین سرعت توسعه و عملکرد خام است. در حالی که فریمورک FastAPI در پایتون (ASGI) امکان انطباق سریع APIها را فراهم میکند، عملیاتهای با عملکرد بالا مانند «محدوده کوهستانی مرکل» (MMR) و «ثبت پیشنویس» (WAL) به زبانهای کامپایلشده نیاز دارند. برای حل این چالش، تیم توسعه بخشهای رمزنگاری و ثبت لاگ را به یک افزونه کامپایلشده با زبان Rust به نام aegis_rust_v2 منتقل کردند و برای ایجاد پیوند (Binding) بین این دو، از PyO3 و Maturin استفاده نمودند.
این تنش معماری یادآور نیاز به دقت در مدلهای کوچکتر است؛ مشابه آنچه در پوششهای قبلی ما دربارهی چگونگی افزایش دقت مدلهای بسیار کوچک مانند Qwen 3 0.6B از طریق Fine-tuning ذکر شد.
بر اساس گزارش فنی، Aegis از یک «مدل اجرای دومسیره» (Two-Path Execution Model) استفاده میکند. مسیر سریع (Hot Path) چرخه فوری درخواست را مدیریت میکند: این مسیر شامل گاردها (Smuggling guards)، احراز هویت، دیوار آتش وب (WAF)، محدودیت نرخ (Rate-limiting)، آداپتور و هدایتکننده (Forwarder) است تا در نهایت درخواست را به LLM بالادستی ارسال کند.
بهطور همزمان، سیستم تابع _spawn_background() را برای فعالسازی مسیر پسزمینه از طریق asyncio.create_task اجرا میکند. این مسیر وظیفهی پردازش ResponseAnalyzer، دفتر کل حسابرسی رمزنگاری (CryptographicAuditLedger)، MMR و Write-Ahead Log را بر عهده دارد. در یک محیط بنچمارک (پردازنده Intel Xeon با فرکانس ۲.۸۰ گیگاهرتز و ۴ هسته)، این بلوک زمانبندی — که شامل ردیابی مجموعهی پسزمینه و بهروزرسانی شاخصهای Prometheus است — تنها ۲.۴۳ میکروثانیه در p50 و ۶.۷۸ میکروثانیه در p99 هزینه دارد.
جزئیات فنی Rust MMR
برای شتاببخشی به مسیر حسابرسی، تیم توسعه لایهی Rust را برای مدیریت تجمعکنندهی MMR طراحی کرد. برخلاف درختهای مرکل باینری کلاسیک و متوازن، MMR یک تجمعکنندهی لگاریتمی «فقط-افزودنی» (Append-only) است که اثباتهای شمول و سازگاری را بدون نیاز به هزینههای سنگین بازتعادلسازی (Rebalancing) ارائه میدهد.
در پایتون خالص، عملیات هش کردن برگها در مقیاس بالا باعث ایجاد فشار قابلاندازهگیری روی مدیریت حافظه (GC) میشود، زیرا ادغام قلهها (Merging peaks) مستلزم تخصیص تعداد زیادی شیء کوچک از نوع bytes است. پیادهسازی Rust این مشکل را از طریق MmrAccumulator حل میکند که از SHA-256 بومی برای ادغام قلهها بدون تخصیص حافظه (Zero-allocation) استفاده میکند. لایهی شتابدهندهی Rust سرعت پایداری بین ۳.۰۱ تا ۳.۳۴ برابر نسبت به خط مبنای پایتون خالص ایجاد کرد:
- ۱۰۰ برگ: ۲.۸۸ برابر سریعتر (۹۵۸,۵۱۰ برگ در ثانیه در مقابل ۳۳۲,۴۶۰ در پایتون)
- ۱,۰۰۰ برگ: ۲.۷۹ برابر سریعتر (۸۱۴,۰۰۰ برگ در ثانیه در مقابل ۲۹۲,۰۵۰ در پایتون)
- ۱۰,۰۰۰ برگ: ۳.۰۳ برابر سریعتر (۷۶۰,۲۶۰ برگ در ثانیه در مقابل ۲۵۰,۶۵۰ در پایتون)
- ۱۰۰,۰۰۰ برگ: ۳.۳۴ برابر سریعتر (۷۰۹,۲۴۰ برگ در ثانیه در مقابل ۲۱۲,۱۸۰ در پایتون)
دیوار تصادم GIL
با وجود این شتابها، تیم توسعه در جریان بررسیهای عملکردی حلقهبسته (Loopback) برای درخواستهای /health با سدی به نام «دیوار تصادم GIL» مواجه شد. آنها روند متناقضی را مشاهده کردند که در آن با افزایش همزمانی (Concurrency)، توان عملیاتی (Throughput) افت میکرد، در حالی که استفاده از CPU در واقع کاهش مییافت:
- همزمانی ۱: ۶۵۰ RPS | تأخیر ۱.۴۹ میلیثانیه p50 | ۳۵.۷٪ CPU
- همزمانی ۴: ۹۰۲ RPS | تأخیر ۴.۰۵ میلیثانیه p50 | ۴۳.۱٪ CPU
- همزمانی ۳۲: ۳۳۹ RPS | تأخیر ۶۵.۲ میلیثانیه p50 | ۱۸.۷٪ CPU
- همزمانی ۱۲۸: ۲۴۶ RPS | تأخیر ۲۹۷.۶ میلیثانیه p50 | ۱۳.۸٪ CPU
این فروپاشی به این دلیل رخ میدهد که هرگاه رشتههای Rust — که استخر Tokio پسزمینه یا فراخوانیهای رمزنگاری PyO3 را اجرا میکنند — قفل سراسری مفسر (GIL) را در اختیار بگیرند، حلقهی ASGI پایتون متوقف میشود. هزینه دریافت و آزادسازی GIL از طریق رابط FFI با افزایش همزمانی مقیاس مییابد و باعث ایجاد مسدودشدگی ابتدای صف (Head-of-line blocking) در حلقه رویداد میشود.
برای توسعهدهندگان، این بدان معناست که بهینهترین راه برای مقیاسبندی سیستمهای ترکیبی پایتون و Rust، مقیاسدهی افقی (Scale-out) است و نه عمودی (Scale-up). استراتژی استقرار توصیه شده برای Aegis این است که یک فرآیند Worker یوویکورن (Uvicorn) به ازای هر هسته فیزیکی اجرا شود و محدودیتهای CPU کانتینر دقیقاً با تعداد Workerها تطبیق یابد تا از throttling توسط CFS جلوگیری شود. قرار دادن یک Load Balancer (مانند NGINX، HAProxy یا AWS ALB) با استفاده از هشینگ نزدیکی مستاجر (Tenant-affinity hashing) در مقابل این سیستم، باعث میشود حلقه رویداد از تصادمهای FFI پاک بماند. این نوع بهینهسازی زیرساختی برای اجرای بهینه مدلها، در راستای روندی است که در تحلیل ابزارهای اجرای محلی عاملهای هوش مصنوعی بدون نیاز به سختافزارهای صنعتی نیز مورد بحث قرار گرفت.
اگر در حال استقرار هوش مصنوعی مولد در بخشهای تحت نظارت هستید، باید کدهای Aegis تحت لایسنس AGPLv3 را دنبال کنید تا ببینید چگونه این گلوگاههای رشتهای (Threading) مدیریت میشوند.
گام بعدی شما
- اگر در بخشهای نظارتی فعالیت میکنید، کدهای Aegis را در لایهی AGPLv3 بررسی کنید تا با مدیریت گلوگاههای Threading آشنا شوید.
- معماری دومسیره را برای جداسازی منطق تجاری از لایههای حسابرسی در گیتویهای خود پیاده کنید.
- در استقرار مدلهای ترکیبی، به جای افزایش CPU یک کانتینر، تعداد Workerها را با تعداد هستههای فیزیکی تطبیق دهید.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو