تصور کنید یک عامل هوش مصنوعی برای رفع یک خطای کوچک، کل خوشه سرورهای عملیاتی شما را به دلیل یک اشتباه در استنتاج پایین بیاورد؛ کابوسی که هر مهندس SRE (مهندس قابلیت اعتماد سایت) از آن واهمه دارد. برای حل این چالش، پروژه متنباز agent-runbook که در گیتهاب (github.com/KnoxOps/agent-runbook) منتشر شده است، با معرفی قراردادهای اعلامی (Declarative Contracts)، دوران «امیدواری و پرامپتنویسی» را به پایان رسانده و رفتار دقیق عاملها را در وظایف عملیاتی قفل میکند.
همانطور که در تحلیل قبلی ما دربارهی این موضوع که آیا مهندسی حلقه (Loop Engineering) در حال جایگزینی پرامپتنویسی دستی است اشاره کردیم، این رویکرد نقش انسان را از یک راننده به یک معمار تغییر میدهد. در واقع، این گذار از دستورات متنی به ساختارهای حلقوی، گامی کلیدی برای دستیابی به خودکارسازی کامل عاملهاست. به نقل از پیتر استاینبرگر، بنیانگذار OpenClaw، این تحول را چنین توصیف میکند: «شما دیگر نباید برای عاملهای کدنویس پرامپت بنویسید، بلکه باید حلقههایی طراحی کنید که عاملهای شما را پرامپت کنند.»
این بدان معناست که شما دیگر شخصی نیستید که عامل را گامبهگام و به صورت دستی هدایت میکند. در عوض، سیستمی میسازید که خودش اجرا کند، بازرسی نماید، اصلاح کند و ثبت نماید. شما از کسی که آچار میچرخاند به کسی تبدیل میشوید که خط تولید را طراحی کرده است. این تغییر در عملیات (Operations) حیاتی است، زیرا هزینه یک اشتباه در اینجا نه با یک خط کد دارای باگ، بلکه با زمان توقف سرویس (Downtime) سنجیده میشود. در عملیات، ایمنی همه چیز است؛ بدون حفاظها (Guardrails) و حضور انسان در حلقه (Human-in-the-loop)، یک چرخه خودکار میتواند خسارات واقعی به بار آورد. من طرفدار حلقههای عملیاتی «کاملاً خودکار» نیستم و این چارچوب دقیقاً نشان میدهد چرا یک رویکرد گیتدار (Gated Approach) برتر است.
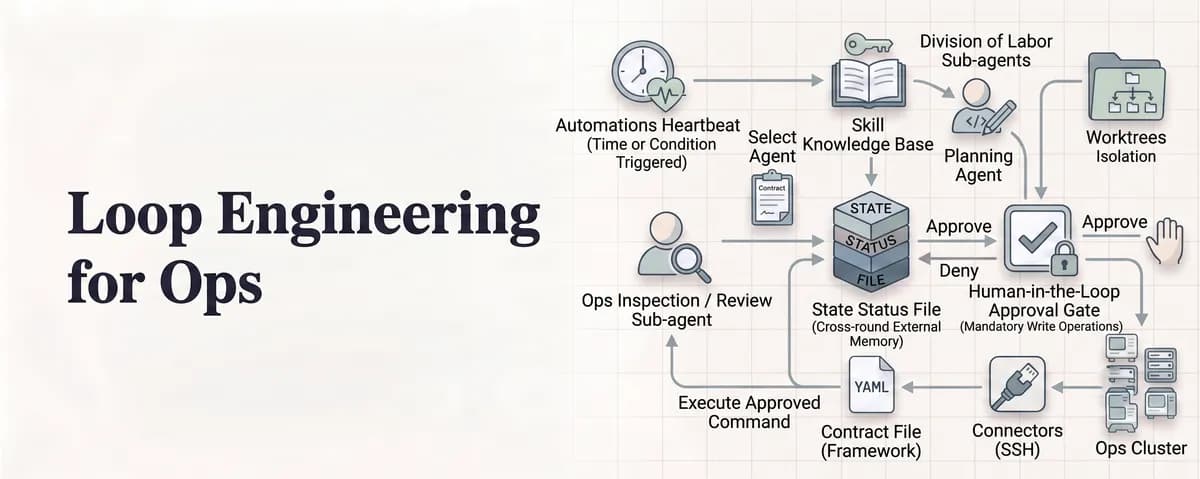
شش ستون مهندسی حلقه
مهندسی حلقه (Loop Engineering) — که شبیه طراحی یک نقشه راه دقیق برای ربات است تا هرگز از مسیر خارج نشود — پس از مراحل پرامپت (Prompt)، زمینه (Context) و harnessing قرار میگیرد و هماهنگی عاملها را یک گام جلو میبرد. بر اساس یک چارچوب فنی (که توسط ادی عثمانی از گوگل نیز صورتبندی شده است)، برای عبور از پرامپتنویسی ساده و رسیدن به مهندسی حلقه مؤثر، شش المان متمایز ضروری است:
- اتوماسیونها (Automations): محرکهای زمانبندی شده یا شرطی هستند. اینها به حلقه اجازه میدهند تا بدون نیاز به فرمان شروع توسط انسان، خودش اجرا شود.
- درختهای کاری (Worktrees): استفاده از چندین عامل که به صورت موازی و در محیطهای ایزوله (Isolated Checkouts) کار میکنند تا اطمینان حاصل شود که اقدامات آنها با یکدیگر تداخل ایجاد نمیکند.
- مهارتها (Skills): دانش پروژه که به صورت مستندات مکتوب شده است تا عامل در هر جلسه (Session) جدید نیاز به دریافت توضیحات تکراری نداشته باشد.
- اتصالدهندهها (Connectors): قلابهایی (Hooks) به سیستمهای واقعی — مانند SSH، APIها و پایگاههای داده — که به عامل اجازه میدهد تغییرات را واقعاً اجرا کند.
- عاملهای فرعی (Sub-agents): تفکیک ساختاری نقشها؛ بهویژه جداسازی «سازنده» (Builder) از «بازبین» (Reviewer). این کار از سوگیریهایی جلوگیری میکند که در آن عاملی که کد را نوشته است، هنگام نمره دادن به کار خودش «بیش از حد مهربان» باشد.
- وضعیت (State): مکانیزمی برای به خاطر سپردن وقایع در طول اجراهای مختلف. از آنجایی که عاملها معمولاً حافظه کوتاهمدت دارند و فراموش میکنند، سیستم بر روی فایلهایی تکیه میکند که فراموش نمیکنند.
ابزارهایی مثل Claude Code و Codex بسیاری از این قابلیتها را به طور بومی ارائه میدهند، اما نمیتوانند محدودیتهای ساختاری حلقه را برای شما تعریف کنند. یک دستور تکمرحلهای، مانند /goal در Claude Code، شکافهای خطرناکی ایجاد میکند. چنین دستوری کاربر را مجبور نمیکند تعریف کند که در هر دور چند گام طی شود، گامها چگونه به یکدیگر تحویل داده شوند، سیستم از کجا بفهمد کار تمام شده است، یا چه چیزی از خروج فرآیند از مسیر جلوگیری میکند. هیچکس شما را مجبور به فکر کردن به این مسائل نمیکند و میتوانید به سادگی از آنها بگذرد.
مکانیزم اولویت با قرارداد
پروژه agent-runbook این خلأها را با اجبار توسعهدهندگان به نوشتن یک فایل YAML پر میکند که گامهای حلقه، فرمت خروجیها، وابستگیها و حفاظها را اعلام میکند. فلسفه اصلی این است که عاملها با قراردادها مهار شوند، نه با پرامپت و امید. این فایل به جای یک پرامپت فرار که تایپ میکنید و فراموش میروید، به عنوان قراردادی عمل میکند که در مخزن کد (Repository) ثبت میشود. اجرای بعدی، توسط شخصی دیگر، با همان فایل و نتیجهای یکسان خواهد بود.
طبق گزارشهای فنی، این سیستم از چندین لایه حفاظتی کلیدی بهره میبرد:
- اعتبارسنجی زمان ساخت (Build-time Validation): پروژه از یک کامپایلر استفاده میکند تا فایل YAML را پیش از تولید فایل مهارت (Skill file) اعتبارسنجی کند. این کامپایلر نقص در اسکیماها، وابستگیهای چرخشی و ارجاعات به خروجیهای موجود نیست را شناسایی میکند تا هیچچیز در میانه اجرا منفجر نشود. این رویکرد سختگیرانه در اعتبارسنجی، مشابه متدهای مورد استفاده در شرکت Atomic است که برای جلوگیری از توهمات عاملهای کدنویس از جریانهای کاری مبتنی بر TypeScript بهره میبرد.
- گرههای سخت تأیید انسانی (Hard HITL Nodes): در محیط عملیاتی، تمامی عملیات نوشتن (Write operations) پشت یک گیت انسانی اجباری هستند. عامل میتواند از طریق SSH وارد شود، بررسی کند و یک برنامه — شامل لیستی از دستورات خاص — پیشنویس کند، اما انسان تصمیم میگیرد که آیا آن دستورات واقعاً اجرا شوند یا خیر. این یک گره سخت در ساختار گامهاست؛ اگر تأیید نشود، حلقه پیش نمیرود.
- حافظه خارجی (External Memory): سیستم متنی داخلی عامل را که پس از هر نوبت (Turn) ریست میشود، نادیده میگیرد. در عوض، حلقه تمام خروجیهای هر دور و تاریخچه تکرارها را در فایلها ذخیره میکند. یک فایل وضعیت (Status file) گامهای تکمیل شده را ردیابی میکند و یک لاگ تکرار (Iteration log) دقیقاً ثبت میکند که در هر دور چه چیزی اصلاح شده است.
- ارتباطات مبتنی بر اسکیما (Schema-Enforced Communication): برای جلوگیری از فساد خاموش دادهها (Silent Data Corruption)، خروجی هر گام از یک JSON Schema سختگیرانه پیروی میکند. گام بعدی هنگام خواندن دادهها، آن را اعتبارسنجی میکند؛ هرگونه عدم تطابق در فیلدها باعث توقف فوری فرآیند میشود. نباید روی حافظه عامل برای یادآوری گفتههای گام قبلی حساب کرد؛ اجازه دهید فایلها این کار را انجام دهند.
- قطعکنندههای مدار (Circuit Breakers): هر حلقه باید یک سقف تکرار سخت (مثلاً ۱۰ دور) اعلام کند. این امر تضمین میکند که حلقه برای همیشه اجرا نمیشود و در صورتی که مشکلی قابل حل نباشد، به عنوان یک ترمز ایمنی عمل میکند.
- حفاظهای اجباری (Mandatory Guardrails): برخلاف درخواستهای مبتنی بر پرامپت (مثلاً «به تنظیمات دست نزن»)، اینها بررسیهای اجباری هستند. بعد از هر دور، یک بازبینی مستقل تأیید میکند که عامل دستوراتی خارج از برنامه اجرا نکرده یا فایلهای ممنوعه را تغییر نداده است. اگر چنین اتفاقی بیفتد، آن دور به عنوان تکمیل شده حساب نمیشود.
مطالعه موردی: بررسی سلامت میزبان
برای نمایش این موضوع در یک سناریوی واقعی، این چارچوب روی سه ماشین bare-metal با استفاده از یک بررسی سلامت مبتنی بر Ansible تست شد. هدف این بود که مشکلات از طریق Ansible کشف شوند، یکی یکی اصلاح گردند و این روند تکرار شود تا زمانی که تمامی میزبانها سالم باشند. فرآیند کلی یک حلقه است: شناسایی توسط Ansible $\rightarrow$ اصلاح تکبهتک (با تأیید انسانی) $\rightarrow$ بازرسی مجدد $\rightarrow$ تکرار $\rightarrow$ تولید گزارش.
منطق حلقه
هر دور از این حلقه شامل پنج گام متمایز است. پیادهسازی فنی از شناسههای YAML خاص برای قفل کردن جابجاییها استفاده میکند:
۱. بازرسی (Inspect) با نوع script: یک اسکریپت، یک Playbook آنسیبل را برای بازرسی تمامی میزبانها اجرا کرده و فایل host_issues.json را تولید میکند. دستور مورد استفاده ansible-playbook -i {inventory} {playbook} 2>&1 است که سپس نتیجه را به فایل مذکور منتقل میکند. این گام، خط مبنای مشکلات فعلی را ایجاد میکند.
۲. انتخاب (Select) با نوع inline: یک پرامپت داخلی، مشکلات را میخواند و تک-حیاتیترین مشکل را بر اساس یک ترتیب اولویت سختگیرانه انتخاب میکند:
* دیسک بحرانی (بالاترین اولویت)
* سرویس بحرانی متوقف شده
* حافظه بحرانی
* بار (Load) بحرانی
* هشدار دیسک
* هشدار سرویس متوقف شده
* هشدار حافظه
* هشدار بار (پایینترین اولویت)
اگر total_issues برابر با ۰ باشد، عامل عبارت {"done": true} را مینویسد تا تکمیل عملیات را علامتگذاری کند.
۳. برنامهریزی (Plan) با نوع agent: یک عامل یک فرآیند دو مرحلهای را طی میکند. اول، باید از طریق SSH به میزبان هدف متصل شده و علت ریشهای را بررسی کند تا از حدس زدن اجتناب شود. دوم، یک برنامه اصلاحی ملموس را بر اساس یک اسکیمای خاص در pending_action.json مینویسد. اجرای هرگونه دستور در این مرحله صریحاً ممنوع است.
۴. تأیید (Approve) با نوع inline: یک گیت تأیید انسانی، میزبان، مشکل، سطح ریسک و دستورات را نمایش میدهد. انسان باید عبارت "approve" را برای اجرا یا "reject" را برای رد کردن تایپ کند. در صورت تأیید، فایل pending_action.json به approved_action.json کپی میشود. در صورت رد، فایلی به نام skip_action.json حاوی دلیل تصمیم انسان نوشته میشود.
۵. اجرا و تأیید (Execute & Verify) با نوع agent: عامل دقیقاً دستورات موجود در برنامه را اجرا میکند. قوانین سخت هستند: بداههپردازی نکن، در صورت شکست دستور دوباره تلاش نکن و بلافاصله بعد از اجرا نتیجه را تأیید کن. یک quality_check با وضعیت blocking: true تأیید میکند که هیچ دستور تخریبی به صورت بداهه اجرا نشده و تأییدیه انجام شده است.
نتایج اجرا
در یک تست زنده، بازرسی اولیه مشکلات متعددی را در سه ماشین یافت. در دور اول، عامل به eval-bare-vm-3 رسید، جایی که دیسک ریشه ۹۳٪ اشغال شده بود (فقط ۱.۴ گیگابایت باقی مانده بود). بررسیها مقصران خاص را شناسایی کرد: یک لاگ JSON داکر ۵.۴ گیگابایتی، ۴.۵ گیگابایت فایل موقت در /tmp، ۲۱۵ مگابایت لاگهای اپلیکیشن و حدود ۸۰۰ مگابایت کش کانتینر.
پس از تأیید انسان، عامل لاگ داکر را کوتاه کرد (Truncate)، پوشه /tmp را پاک کرد، کش apt را تمیز نمود و journald را به ۵۰ مگابایت کاهش داد. این اقدامات حدود ۱۰ گیگابایت فضا آزاد کرد و میزان استفاده از دیسک را از ۹۳٪ به ۳۸٪ رساند. دورهای بعدی، سرویسهای Nginx و Docker را که به صورت دستی متوقف شده و هرگز بازگردانده نشده بودند، مدیریت کردند. پس از مجموعاً پنج دور، حلقه به هدف خود یعنی ۰ مشکل رسید و به طور خودکار متوقف شد.
در نهایت، عامل یک گزارش داشبورد HTML حرفهای با تم تیره تولید کرد. این گزارش شامل موارد زیر است:
- وضعیت کلی سلامت (همگی پاک ALL CLEAR یا مشکلات باقیمانده)
- آمار کلی میزبانهای بررسی شده و مشکلات حل شده
- یک خطزمانی کامل از اصلاحات به همراه یافتههای بررسی و مقایسههای قبل و بعد
- طراحی با CSS grid/flexbox با استایلهای داخلی (inline) برای اینکه فایل مستقل باشد و در موبایل نیز به صورت حرفهای نمایش داده شود.
تحلیل میدانی: طراحی حلقههای عملیاتی مؤثر
این تغییر نشاندهنده حرکتی به سمت «عاملمحوری قطعی» (Deterministic Agency) است. برای مهندسانی که حلقههای خود را میسازند، این چارچوب چندین اصل طراحی را پیشنهاد میکند:
انتخاب وظایف مناسب
حلقههای عملیاتی خوب نیاز به سیگنالهای بازخورد عینی دارند. کاندیداهای ایدهآل عبارتند از:
- اسکن انقضای گواهینامهها (Certificates)
- حلقههای ریاستارت پادهای K8s یا بررسی سلامت گرهها
- طبقهبندی طوفانهای هشدار Prometheus
- تطبیق الگوهای ناهنجاری در لاگها
- تأیید بکآپهای پایگاه داده
- بررسی انطباق پیکربندی میانافزارها (Middleware)
وظایفی که نیاز به قضاوت کلی دارند، مانند برنامهریزی ظرفیت (Capacity Planning) یا تغییرات معماری، نباید در حلقه قرار گیرند زیرا فاقد سیگنال باینری «اصلاح شده/اصلاح نشده» هستند.
تعریف وضعیت «پایان»
شرایط پایان باید توسط ماشین قابل تصمیمگیری باشد. «لیست مشکلات خالی است» (جایی که total_issues == 0) یک شرط معتبر است زیرا یک اسکریپت میتواند آن را در یک خط تشخیص دهد. اما «خوشه سالم است» بیش از حد مبهم است. اگر یک اسکریپت نتواند وضعیت را در یک خط تشخیص دهد، احتمالاً یک عامل هوش مصنوعی نیز نمیتواند.
مدیریت ایمنی در محیط عملیاتی
در حالی که محیطهای Stage میتوانند کاملاً خودکار باشند، محیط Production نمیتواند. گام تأیید، شیر اطمینان ضروری است. با ثبت این گام در قرارداد YAML، این مورد صدها برابر قابلاعتمادتر از یک پیشنهاد مبتنی بر پرامپت میشود. علاوه بر این، سقف تکرارهای حداکثری باید به عنوان یک قطعکننده مدار دیده شود؛ یک حلقه سالم باید بسیار پایینتر از آن حد متوقف شود. اگر به سقف تکرار برسید، احتمالاً مشکل غیرقابل حل است یا بازرسی شما هشدار غلط (False-flagging) میدهد.
نتیجهگیری
پروژه agent-runbook تعمداً سبک طراحی شده است. این پروژه تلاش نمیکند یک پیادهسازی کامل از مهندسی حلقه باشد، بلکه بر نوشتن ساختارهای حلقه به صورت فایلهای اعلامی تمرکز دارد. کاربران میتوانند YAML را بنویسند، آن را با یک دستور ساده کامپایل کنند (python3 -m agent_runbook generate runbook.yaml -o output/) و فایل SKILL.md حاصل (که حدود ۲۵۰ خط است) را در Claude Code یا Codex قرار دهند.
نگاشت فنی SKILL.md
فایل SKILL.md تولید شده، جریان اجرا را برای تضمین سازگاری به طور صریح نگاشت میکند و موارد زیر را مدیریت میکند:
- زمینه وظیفه (Task Context): مقداردهی اولیه
task_context.jsonبرای ردیابی وضعیت هر گام، که اجازه میدهد سیستم در صورت کرش کردن در میانه اجرا، از آخرین گام تکمیل شده ادامه دهد. - ارزیابی حلقه: بررسی هدف پس از هر دور. اگر هدف محقق شده باشد، تکمیل را علامت میزند؛ در غیر این صورت، بررسی میکند که آیا تکراری باقی مانده است یا خیر.
- ثبت تاریخچه: الحاق نتایج به
iteration_historyبعد از هر دور برای حفظ یک رکورد دائمی.
این رویکرد، مهارتهای لازم برای AI Ops را از «پرامپت کامل» به توانایی نگاشت جریانهای عملیاتی به ماشینهای وضعیت (State Machines) با شرایط خروج واضح منتقل میکند. اگر در حال حاضر روزهای خود را با SSH به سرورها برای بررسیها و اصلاحات تکراری میگذرانید، منضبطترین راه پیشرو این است که آن جریان را به صورت یک اعلان (Declaration) نگاشت کنید و اجازه دهید ابزار آن را اجرا کند. این ابزار از شما منضبطتر خواهد بود.
گفتگو