
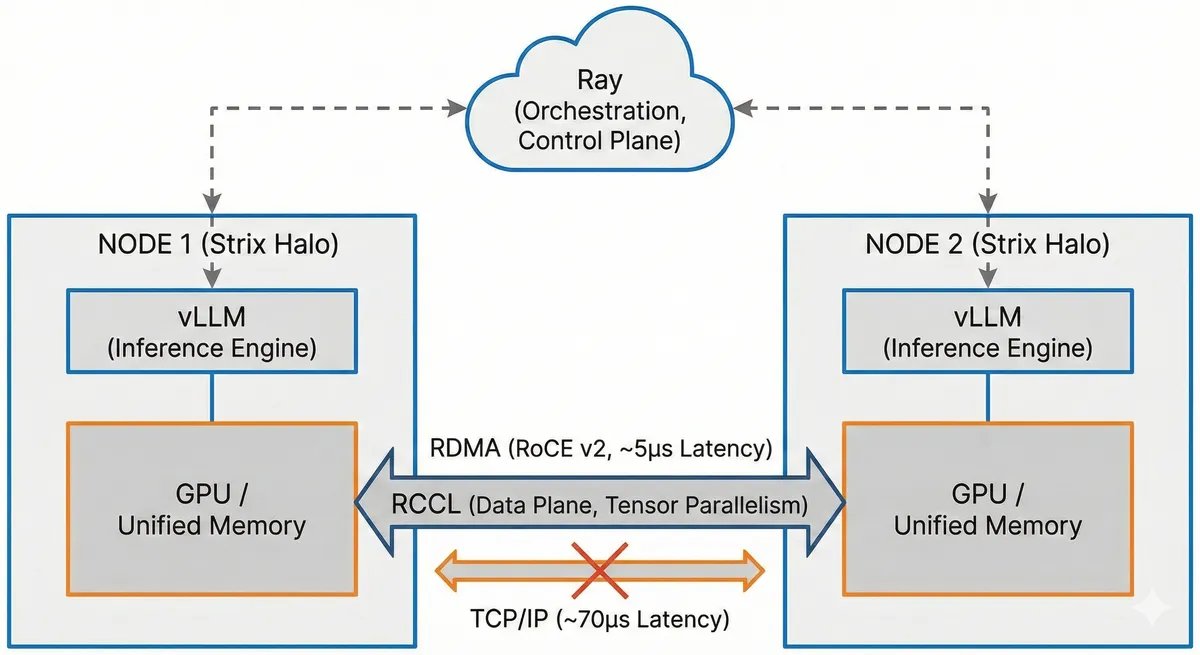
تصور کنید میخواهید یک مدل زبانی غولآسا را روی سختافزاری اجرا کنید که برای مصرفکننده طراحی شده، اما با سرعت سرورهای دیتاسنتر پاسخ بگیرید. این دقیقاً همان چیزی است که با ایجاد خوشهای از دو گره پردازنده AMD Ryzen AI MAX+ «Strix Halo» رخ میدهد تا تأخیر همگامسازی به رکورد خیرهکننده ۵.۲۳ میکروثانیه برسد. این جهش عملکردی، دو ماشین مجزا را به یک موتور استنتاج (Inference) واحد و یکپارچه تبدیل میکند.
به نقل از مستندات فنی منتشر شده، این موفقیت از طریق پیادهسازی RoCE v2 (RDMA over Converged Ethernet) حاصل شده است. در استنتاج توزیعشده، معمولاً یک «مالیات ارتباطی» (Communication Tax) وجود دارد؛ یعنی زمانی که برای جابهجایی داده بین GPUها صرف میشود، سرعت تولید توکن (Token) — یا همان تکههای کوچک متن که مدل مثل برشهای کیک میخورد — را نابود میکند. طبق گزارشهای فنی، اکثر سیستمهای خانگی از پروتکل استاندارد TCP/IP استفاده میکنند که سربار پردازشی بسیار زیادی ایجاد میکند. اما با استفاده از RDMA، دادهها مستقیماً از حافظه یک گره به گره دیگر نوشته میشوند و CPU و هسته سیستمعامل (Kernel) را بهطور کامل دور میزنند.
همانطور که در تحلیلهای پیشین ما دربارهی بهینهسازیهای سختافزاری مدلهای بازمتن اشاره کردیم، گلوگاه اصلی همیشه پهنای باند حافظه بوده است. این ساختار جدید بر پایه معماری قدرتمند Strix Halo، مدلهایی را هدف قرار میدهد که برای حافظه یک پردازنده تنها (Single APU) بیش از حد بزرگ هستند. این سیستم از موازات تانسوری (Tensor Parallelism یا TP) برای تقسیم بار استفاده میکند؛ به این معنا که گرهها باید هزاران بار در هر ثانیه نتایج جزئی شبکه عصبی (Neural Network) — شبکهای از سلولهای کوچک شبیه نقشه مترو — را مبادله کنند تا سرعت تعاملی و پاسخگویی مدل حفظ شود.
لایه سختافزاری
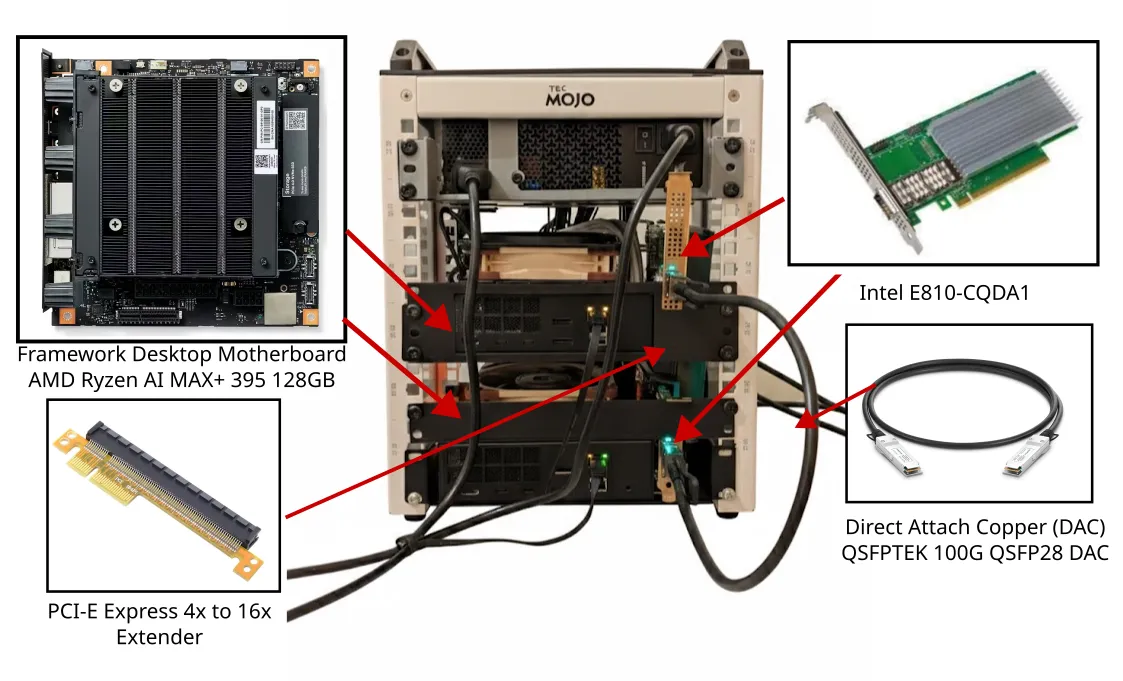
بر اساس مستندات، این چیدمان از دو مادربرد Framework Desktop استفاده میکند که هر کدام به ۱۲۸ گیگابایت حافظه یکپارچه (Unified Memory) مجهز شدهاند. برای مدیریت لایه داده، راهنمای فنی کارتهای شبکهای Intel Ethernet Controller E810-CQDA1 (یا مدلهای مشابه ۱۰۰ گیگابیت QSFP28) را توصیه میکند که از طریق کابلهای Direct Attach Copper (DAC)، مانند کابلهای شرکت QSFPTEK، متصل شدهاند. نکته مهم این است که در یک ساختار دو گرهای، هیچ نیازی به خرید یا استفاده از سوئیچ خارجی نیست و اتصال مستقیم برقرار میشود.
بهدلیل اینکه اسلات PCIe مادربرد Framework به صورت فیزیکی x4 است، استفاده از یک رایزر (Riser) برای جایگذاری کارتهای x16 ضروری است. راهنمای فنی مدل CY PCI-E Express 4x to 16x Extender را پیشنهاد میدهد. اگرچه برخی کاربران برای پذیرش مستقیم کارتهای x16، اسلاتهای PCIe را با استفاده از تیغه اولتراسونیک برش داده و اصلاح کردهاند، اما این کار برای کاربران عادی توصیه نمیشود. رایزرها راهکاری ارزانتر، ایمنتر و سادهتر هستند که عملکردی کاملاً یکسان با پهنای باند حدود ۵۰ گیگابیت بر ثانیه و تأخیر حدود ۵ میکروثانیه ارائه میدهند.
تنظیمات هسته و نرمافزاری
طبق اعلام توسعهدهندگان، سیستمعامل میزبان Fedora 43 است. هستههای (Kernel) تأییدشده برای این پیکربندی، نسخه 6.18.5-200.fc43.x86_64 برای گره اول (Node 1) و نسخه 6.18.6-200.fc43.x86_64 برای گره دوم (Node 2) میباشد. شبکه در یک زیردامنه (Subnet) با آدرس 192.168.100.0/30 پیکربندی شده است، به طوری که گره اول به عنوان Head (آدرس 192.168.100.1) و گره دوم به عنوان Worker (آدرس 192.168.100.2) عمل میکند.
برای رسیدن به این سطح از عملکرد، چندین پارامتر حیاتی هسته باید در فایل /etc/default/grub و در بخش GRUB_CMDLINE_LINUX اضافه شوند:
iommu=pt: حالت IOMMU را روی Pass-Through قرار میدهد. این کار سربار پردازشی را هم برای کارت شبکه RDMA و هم برای دسترسی به حافظه یکپارچه iGPU کاهش میدهد.pci=realloc: باز تخصیص PCI BARها را انجام میدهد. این مورد در پلتفرمهای مصرفکننده برای نقشهبرداری صحیح فضاهای آدرسی بزرگ برای کارت E810 یا Strix Halo ضروری است.pcie_aspm=off: مدیریت توان فعال (Active State Power Management) در PCIe را غیرفعال میکند تا از جهشهای ناگهانی تأخیر (Latency Spikes) و مشکلات مذاکره لینک در اتصال ۱۰۰ گیگابیتی جلوگیری شود.amdgpu.gttsize=126976: اندازه GTT گرافیکی را به حدود ۱۲۴ گیگابایت (126976 مگابایت) محدود میکند. این پارامتر تعیین میکند که GPU چه مقدار از رم سیستمی را میتواند به عنوان VRAM اختصاصی خود شناسایی کند.ttm.pages_limit=32505856: مدیریت جدول ترجمه (Translation Table Manager) را به حدود ۱۲۴ گیگابایت (در صفحات ۴ کیلوبایتی) محدود میکند تا با اندازه GTT مطابقت داشته باشد.
برای نهایی کردن این تغییرات، کاربران باید دستور sudo grub2-mkconfig -o /boot/grub2/grub.cfg را اجرا کرده و سیستم را ریبوت کنند. همچنین برای اطمینان از تخصیص پایدار حافظه، در تنظیمات BIOS باید مقدار iGPU Memory Allocation روی کمترین مقدار ممکن یعنی ۵۱۲ مگابایت قرار گیرد. این تنظیم باعث میشود سیستم مجبور شود از جدول ترجمه گرافیکی (GTT) برای تخصیص پویا و دینامیک حافظه سیستمی به عنوان «حافظه یکپار analogue» برای GPU استفاده کند.
پیکربندی شبکه و دیوار آتش
تنظیم دقیق شبکه برای RoCE v2 حیاتی است. در این چیدمان از درایور Ethernet مدل ice و درایور irdma (که درایور یکپارچه برای RoCE v2 و iWARP است) استفاده میشود. کاربران باید ابزارهای فضای کاربری RDMA را از طریق dnf با دستور sudo dnf install rdma-core libibverbs-utils perftest نصب کنند.
بستههای کلیدی نصب شده عبارتاند از:
rdma-core: اجزای فضای کاربری برای زیرسیستم RDMA، شامل کتابخانهها، دیمونها و ابزارهای پیکربندی را فراهم میکند.libibverbs-utils: ابزارهای ضروری برای پرسوجو از دستگاههای RDMA، مانند دستورibv_devinfoرا شامل میشود.perftest: مجموعهای از بنچمارکها شاملib_write_bwوib_send_latبرای تأیید پهنای باند و تأخیر RDMA است.
این فرآیند شامل اختصاص IPهای استاتیک و فعالسازی Jumbo Frames برای کاهش سربار CPU است. کاربران باید با استفاده از nmcli اتصال شبکه (مثلاً "rdma0") را به MTU 9000 تغییر دهند. تأیید نهایی اتصال با دستور rdma link انجام میشود که باید وضعیت ACTIVE و حالت فیزیکی LINK_UP را نشان دهد.
از آنجایی که برنامههایی مانند Ray و NCCL از پورتهای تصادفی بالا استفاده میکنند، دیوار آتش (Firewall) باید رابط داخلی RDMA را به عنوان مورد اعتماد شناسایی کند. این کار با افزودن رابط (مثلاً enp194s0np0) به منطقه trusted به صورت دائمی با دستور sudo firewall-cmd --permanent --zone=trusted --add-interface=enp194s0np0 و سپس اجرای sudo firewall-cmd --reload محقق میشود.
عبور از محدودیتهای بالادستی
یک مانع بزرگ در این پروژه این است که بستههای اصلی (Upstream) ROCm در حال حاضر از معماری gfx1151 (Strix Halo) در بخش RDMA پشتیبانی نمیکنند. برای حل این مشکل، پروژه از یک وصله (Patch) سفارشی برای librccl.so استفاده میکند که بر اساس کدهای مخزن rocm-systems/gfx1151-rccl ساخته شده است.
کتابخانه RCCL (ROCm Collective Communication Library) معادل AMD برای NCCL شرکت انویدیا است و همگامسازی سریع دادههای تانسوری را مدیریت میکند. وقتی موازات تانسوری (TP=2) فعال است، گرهها هزاران بار در ثانیه نتایج را مبادله میکنند. این پروژه از یک GitHub Action به نام build-rccl برای کامپایل خودکار و تولید این آرتیفکت استفاده میکند.
جزئیات نصب Toolbox
کانتینر ابزار (kyuz0/vllm-therock-gfx1151) از طریق اسکریپت refresh_toolbox.sh نصب میشود. این اسکریپت مراحل خودکار زیر را طی میکند:
- دریافت ایمیج (Image Pull): آخرین نسخه تصویر
kyuz0/vllm-therock-gfx1151را دریافت میکند. - تشخیص سختافزار: وجود مسیر
/dev/infinibandرا در سیستم میزبان بررسی میکند. - نگاشت منابع (Resource Mapping): کانتینر را با فلگهای خاص ایجاد میکند تا دسترسیهای زیر فراهم شود:
- دسترسی iGPU: مسیرهای
/dev/driو/dev/kfd(ضروری برای ROCm). - دسترسی RDMA: دسترسی به
/dev/infiniband. - پین کردن حافظه: تنظیم
--ulimit memlock=-1که برای دسترسی مستقیم به حافظه (DMA) ضروری است تا از Swap شدن حافظه به دیسک جلوگیری شود.
- دسترسی iGPU: مسیرهای
اجرای خوشه vLLM
مدیریت ارکستراسیون توسط Ray انجام میشود که فرآیندهای Worker را در سراسر گرهها مدیریت میکند. vLLM از Ray برای مدیریت لایه کنترل (Control Plane) و از RCCL برای مدیریت لایه داده (Data Plane) استفاده میکند. برای تسهیل اجرا، از یک ابزار رابط کاربری متنی (TUI) به نام start-vllm-cluster استفاده میشود.
پیش از لانچ، کاربر باید SSH بدون رمز عبور (Passwordless SSH) را بین گرهها برای کاربر root یا کاربری با دسترسی sudo برقرار کند. این مورد را میتوان با اجرای دستور ssh <other-node-ip> date از هر دو گره تأیید کرد؛ در صورت موفقیت، تاریخ باید بدون درخواست رمز عبور چاپ شود.
گردشکار راهاندازی خوشه
در ابزار TUI start-vllm-cluster مراحل به این ترتیب است:
۱. پیکربندی IP: با استفاده از گزینه ۱، IP گره Head را روی ۱۹۲.۱۶۸.۱۰۰.۱ و IP گره Worker را روی ۱۹۲.۱۶۸.۱۰۰.۲ تنظیم کنید.
۲. راه اندازی Ray: با گزینه ۲، ابتدا گره Head را اجرا کنید (گزینه "Head" را انتخاب کنید). سپس در گره ۲، گزینه "Worker" را انتخاب نمایید. اسکریپت دستور ray start --head --node-ip-address=192.168.100.1 را در هد و ray start --address=192.168.100.1:6379 را در ورکر اجرا کرده و همزمان متغیر NCCL_SOCKET_IFNAME را برای رابط RDMA صادر (export) میکند.
۳. تأییدیه: با گزینه ۳، وضعیت را بررسی کنید تا مطمئن شوید ۲ گره و ۲.۰ GPU شناسایی شدهاند.
برای مدلهایی مانند Meta-Llama-3.1-8B-Instruct، تنظیم موازات تانسوری روی TP=2 توصیه میشود. یک نکته پیکربندی حیاتی، فعال کردن «Force Eager Mode» است. از آنجایی که CUDA Graphs در خوشههای APU توزیعشده میتوانند ناپایدار باشند و باعث بنبست (Deadlock) شوند، حالت Eager ایمنتر است. اگرچه غیرفعال کردن آن ممکن است ۱ تا ۳ درصد عملکرد را افزایش دهد، اما ریسک ناپایداری سیستم را بالا میبرد.
نکات عملیاتی و عیبیابی
در هنگام اجرای خوشه، کاربران باید به موارد زیر توجه کنند:
- دانلود وزنها: در اولین اجرا، هر گره در خوشه باید وزنهای مدل را بهطور مستقل دانلود کند. بسته به سرعت اینترنت، این فرآیند میتواند بسیار زمانبر باشد.
- مدلهای محدودشده (Gated Models): برای مدلهایی مانند
google/gemma-2-27b-itباید ابتدا در Hugging Face درخواست دسترسی بدهید. باید توکن خود را از طریقexport HF_TOKEN=your_token_hereتعریف کنید، در غیر این صورت دانلود مدل شکست میخورد. - بنبستهای vLLM: اگر سیستم دچار هنگ یا توقف شد، حالت Force Eager Mode را در منوی شروع فعال کنید تا از Captureهای ناپایدار CUDA Graph عبور کنید.
- مشکلات Firmware: اگر مشکلات لینک (اتصال) ادامه داشت، فیرمور Intel E810 را با دستور
ethtool -i <iface>بررسی کنید. نسخه ۴.۹۱ (0x800214b5 1.3909.0) یا جدیدتر توصیه میشود. در صورت قدیمی بودن، از ابزار Intel® Ethernet NVM Update Tool برای بروزرسانی استفاده کنید.
جایگزین تاندربولت (Thunderbolt)
برای کاربرانی که کارتهای شبکه ۱۰۰ گیگابیتی در اختیار ندارند، راهنمای فنی یک راهکار جایگزین از طریق کابلهای Thunderbolt 4 یا USB4 ارائه میدهد. این اتصال یک رابط شبکه thunderbolt0 ایجاد میکند. اگرچه این روش فاقد تأخیرهای فوقکم در سطح میکروپردازنده (مانند RDMA) است، اما پهنای باند بسیار بیشتری نسبت به اترنتهای استاندارد ۱ یا ۵ گیگابیت فراهم میکند.
مراحل پیکربندی تاندربولت
۱. اتصال فیزیکی: گرهها را مستقیماً با یک کابل تایید شده Thunderbolt 4 یا USB4 متصل کرده و لینک را با دستور ip link show thunderbolt0 بررسی کنید.
۲. تخصیص IP: با استفاده از nmcli IPهای استاتیک را اختصاص دهید. برای مثال، Head (گره ۱) از 192.168.2.1/24 و Worker (گره ۲) از 192.168.2.2/24 استفاده میکند.
۳. Jumbo Frames: از طریق nmcli connection modify مقدار MTU را روی ۹۰۰۰ تنظیم کنید تا سربار CPU کاهش یابد (هرچند ذکر شده که این مورد ممکن است در برخی کنترلرهای میزبان پشتیبانی نشود).
۴. دیوار آتش: رابط thunderbolt0 را به صورت دائمی به منطقه trusted اضافه کرده و با sudo firewall-cmd --reload اعمال نمایید.
اجرای vLLM روی تاندربولت
اسکریپتهای خوشه بر اساس IPهای وارد شده در TUI، این رابط را بهطور دینامیک شناسایی میکنند. کاربر با ورود به toolbox enter vllm و اجرای start-vllm-cluster و تنظیم IPها روی ۱۹۲.۱۶۸.۲.۱ و ۱۹۲.۱۶۸.۲.۲، سیستم را راهاندازی میکند. اسکریپت بهطور خودکار thunderbolt0 را به عنوان بستر ارکستراسیون Ray و همگامسازی GPU شناسایی و استفاده میکند و نیازی به تنظیم دستی متغیرهای محیطی نیست.
مقایسه عملکرد
تفاوت در سرعت انتقال داده بسیار چشمگیر است. با استفاده از اسکریپت /opt/compare_eth_vs_rdma.sh (که از فلگ -t برای تاندربولت، -e برای اترنت و -r برای RDMA پشتیبانی میکند)، نتایج به شرح زیر به دست آمد:
- اترنت (LAN 1G): تأخیر ۰.۰۷۴ میلیثانیه / پهنای باند ۰.۹۴ گیگابیت بر ثانیه
- اترنت (RoCE NIC): تأخیر ۰.۰۶۸ میلیثانیه / پهنای باند ۵۵.۷۰ گیگابیت بر ثانیه
- RDMA (RoCE): تأخیر ۵.۲۳ میکروثانیه / پهنای باند ۵۰.۶۴ گیگابیت بر ثانیه
کاهش شدید تأخیر از سطح میلیثانیه (سربار TCP/IP) به میکروثانیه (RDMA)، تولید توکنها با سرعت بالا را تضمین میکند. این تغییر در زیرساخت، سختافزارهای مصرفکننده با حافظه بالا را به یک جایگزین واقعی برای اجرای مدلهای وزنهای باز (Open-Weights) — مدلهایی که ساختارشان علنی است — تبدیل میکند، بدون آنکه نیازی به خوشههای تجاری و گرانقیمت H100 باشد.
گام بعدی شما
- اگر به سختافزارهای APU دسترسی دارید، بررسی کنید آیا مادربرد شما از PCIe Gen4 با پهنای باند بالا پشتیبانی میکند یا نیاز به رایزر دارید.
- برای کاهش تأخیر در استنتاجات توزیعشده، تنظیمات
iommu=ptوpcie_aspm=offرا در GRUB فعال کنید. - در صورت مشاهده ناپایداری در مدلهای بزرگ، حتماً حالت Force Eager Mode را در vLLM فعال نمایید.
اما تأثیر این متد بر کاهش هزینههای عملیاتی در مقیاس صنعتی حتی جذابتر است؛ به تحلیل ما دربارهی اقتصاد استنتاج در مدلهای لبه مراجعه کنید.



گفتگو