
اگر در حال استقرار مدلهای هوش مصنوعی در محیطهای کلینیکی هستید، توازن میان دقت و تأخیر (Latency) بهشدت تغییر کرده است. تصور کنید مدلی با ظرفیت ۱.۳ تریلیون پارامتر، در هر لحظه تنها بخش کوچکی از مغز خود را به کار بگیرد تا پاسخی با دقت تخصصهای پزشکی اما با سرعت خیرهکننده ارائه دهد.
به نقل از گزارش Marktechpost، مدل AntAngelMed موفق شده است در حالی که تنها ۶.۱ میلیارد پارامتر را در هر مرحله از استنتاج (Inference) فعال میکند، به عملکرد یک مدل متراکم (Dense) ۴۰ میلیاردی دست یابد. این بهینهسازی باعث شده تا مدل روی سختافزار H20 به سرعت بیش از ۲۰۰ توکن در ثانیه برسد که تقریباً ۳ برابر سریعتر از مدلهای متراکم ۳۶ میلیاردی است.
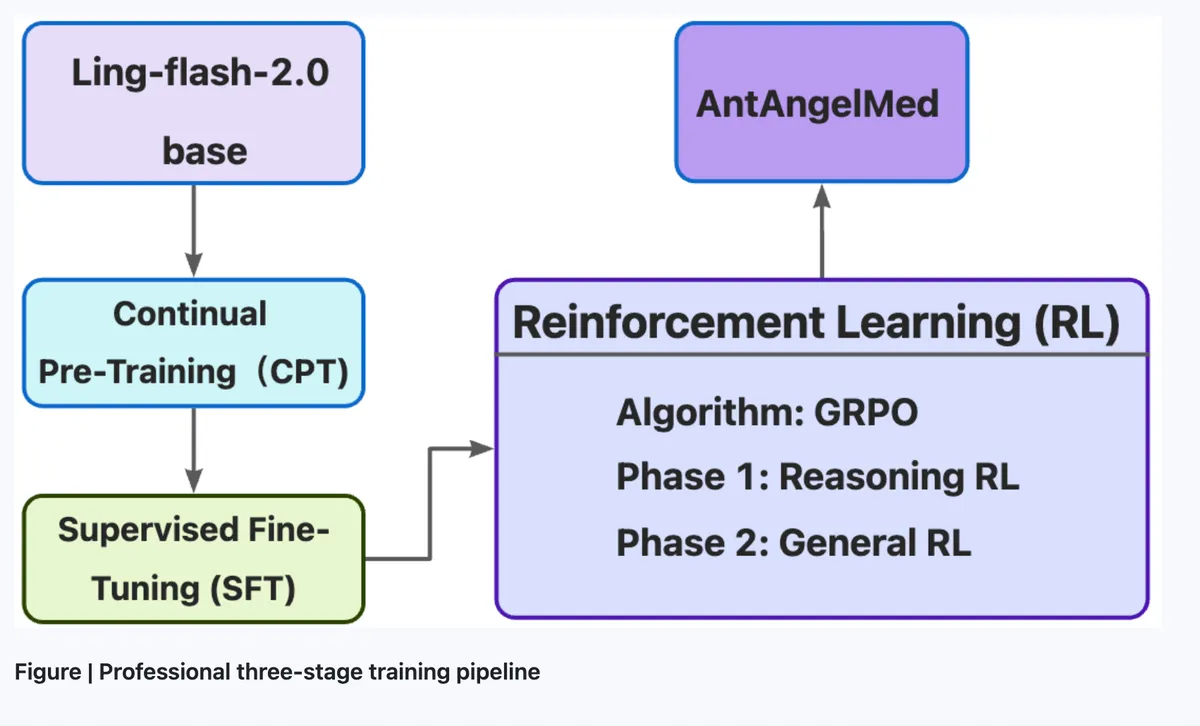
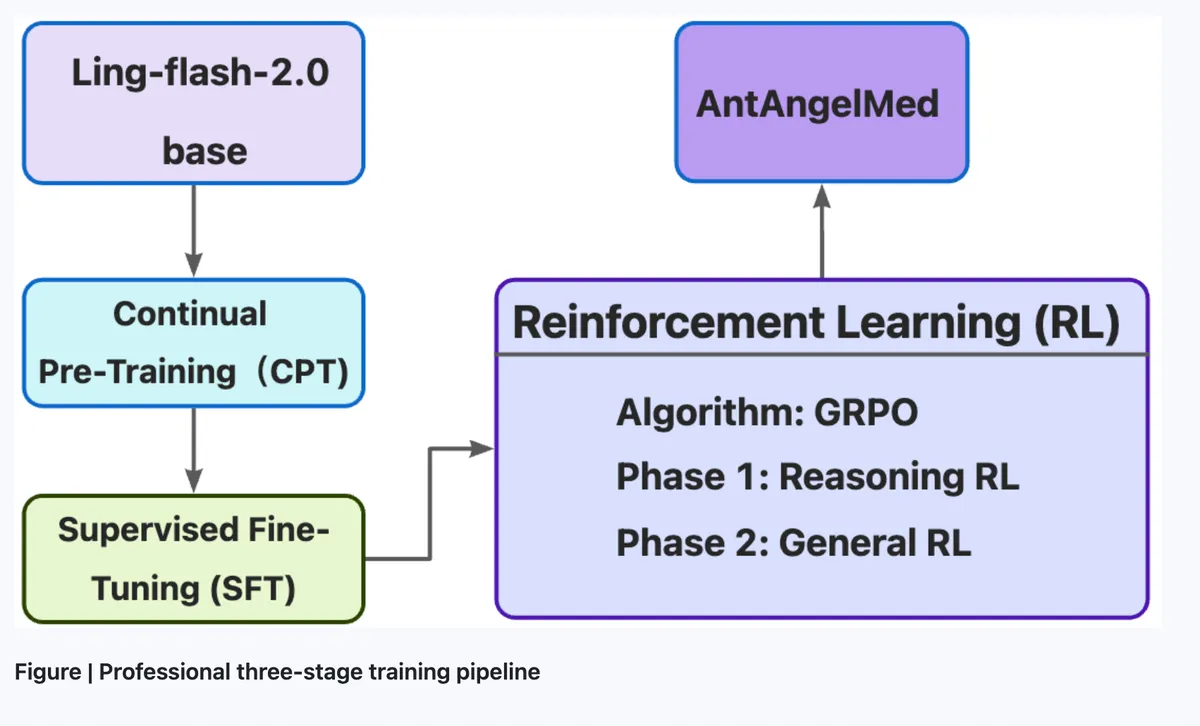
همانطور که در تحلیلهای پیشین ما دربارهی بهینهسازی مدلهای تخصصی اشاره کردیم، چالش اصلی صنعت، حفظ دانش عمیق در عین کاهش هزینههای عملیاتی است. این رویکرد بهینهسازی یادآور دستاوردهای اخیر در حوزهی آموزش مدلهاست، جایی که کاهش چشمگیر قدرت محاسباتی در مدل Moonlight به نتایجی خیرهکننده منجر شد. AntAngelMed که بر پایه مدل Ling-flash-2.0 و قوانین مقیاسپذیری (Scaling Laws) ساخته شده، از معماری ترکیبی خبرهها (Mixture-of-Experts یا MoE) استفاده میکند تا در هر پرسوجو، تنها زیرشبکههای «خبره» مرتبط فعال شوند.
بر اساس مستندات فنی، این مدل از چندین لایه بهینهسازی بهره میبرد:
- ساختار: نسبت فعالسازی ۱/۳۲، لایه پیشبینی چند-توکنی (MTP)، تکنیک QK-Norm و Partial-RoPE.
- پنجره متنی: پشتیبانی از ۱۲۸ هزار توکن از طریق برونیابی YaRN که پردازش کامل پروندههای پزشکی را ممکن میکند.
- فرآیند آموزش: یک خط لوله سهمرحلهای شامل پیشآموزش مستمر روی متون پزشکی، تنظیم دقیق (Fine-tuning) نظارتشده برای ایجاد زنجیره تفکر (Chain-of-Thought) و یادگیری تقویتشده با الگوریتم GRPO برای کاهش توهم (Hallucination).
در آزمونهای معیار، AntAngelMed رتبه اول مدلهای بازمتن را در HealthBench کسب کرده و حتی از مدلهای تجاری در بخشهای دشوار پیشی گرفته است. همچنین این مدل در MedAIBench و MedBench، بهویژه در حوزههای اخلاق پزشکی و ایمنی، در صدر جدول قرار دارد. اگرچه تاریخ دقیق انتشار عمومی اعلام نشده، اما نسخه کوانتیزه FP8 این مدل در ترکیب با رمزگشایی گمانهزن EAGLE3، توان عملیاتی را در بنچمارک Math-500 تا ۹۴٪ افزایش داده است.
برای جامعه فنی، این دستاورد ثابت میکند که «ناپیوستگی شدید» (Extreme Sparsity) در معماری، لزوماً به معنای افت دقت در حوزههای تخصصی نیست. استفاده از GRPO — که نسخهای سبکتر از PPO است — نشان داد که میتوان بدون نیاز به یک مدل «منتقد» (Critic) مجزا، مدل را برای همدلی و استدلال مبتنی بر شواهد بهینه کرد. این موضوع سد سختافزاری برای استقرار دستیارهای پزشکی پیشرفته در محیطهای محلی را بهشدت پایین میآورد.
گام بعدی شما
- بررسی وزنهای مدل تحت لایسنس Apache 2.0 و مخزن کد در MIT برای استقرار محلی.
- آزمایش نسخه FP8 در ترکیب با EAGLE3 برای دستیابی به حداکثر سرعت استنتاج.
- تحلیل عملکرد این معماری در محیطهای واقعی کلینیکی، فراتر از بنچمارکهای شبیهسازیشده.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو