
اگر امروز برای پردازش حجم انبوهی از اسناد در ابریهای هوش مصنوعی هزینه میکنید، احتمالاً بخش بزرگی از بودجه شما صرف توکنهایی میشود که هیچ ارزش افزودهای خلق نمیکنند. شرکت Autowired.ai ثابت کرد که با تغییر جایگاه مدل زبانی در خط لوله تولید، میتوان بدون کاهش دقت، هزینهها را بهطور چشمگیر پایین آورد. طبق تحلیل فنی این شرکت که در ۵ ژوئیه ۲۰۲۶ منتشر شد، با توقف ارسال هر قطعه از دادهها بهطور مستقیم به مدلهای زبانی بزرگ (LLM) و اولویتبندی OCR تخصصی پیش از فراخوانی هوش مصنوعی زاینده، امکان کاهش ۴۰ درصدی هزینههای Amazon Bedrock فراهم شده است. Autowired.ai با این روش یک SaaS استخراج سند مقیاسپذیر توسعه داده است که پردازش با ظرفیت بالا را با کنترل سختگیرانه هزینهها متعادل میکند.
بسیاری از استارتاپهای هوش مصنوعی با LLMها مانند یک چاقوی سوئیسی برخورد میکنند و از آنها هم برای استخراج متن و هم برای ساختاربندی دادهها استفاده میکنند. این رویکرد منجر به اتلاف عظیم توکنها و تأخیر (Latency) بالا میشود. Autowired.ai این مشکل را با تغییر نقش LLM حل کرده است؛ در این معماری، مدل زبانی به جای اینکه استخراجکننده اصلی باشد، به عنوان یک «پرکننده شکاف» (Gap-filler) و اعتبارسنج عمل میکند. این رویکرد در واقع نوعی کنترل دقیق بر عملیات مدل است؛ مشابه آنچه در چارچوب کریستوفر کُک برای کاهش ریسک عاملهای AI مطرح شد، محدود کردن دامنه اثر هوش مصنوعی میتواند منجر به نتایجی قابلپیشبینیتر و بهینهتر شود. در این سیستم، کاربران طرحهای استخراج (Extraction Schemas) را تعریف کرده و دستههای سند را ارسال میکنند و در نهایت دادههای ساختاریافته را در یک زیرساخت چندمستأجری (Multi-tenant) دریافت میکنند، جایی که استنتاج هوش مصنوعی و OCR محرکهای اصلی هزینه هستند.
با تکیه بر بررسیهای عمیق قبلی این شرکت در زمینه خط لولههای رویداد-محور (Event-driven) و طراحی DynamoDB، معماری کامل این سیستم نشاندهنده ساختاری است که برای پردازش دستهای نامتقارن (Asynchronous Batch Processing) طراحی شده است. از آنجا که دستههای سند میتوانند شامل صدها فایل باشند و اجرای آنها دقایقی زمان ببرد، سیستم بهطور عمدی مسیر ارسال (Submission Path) را از مسیر پردازش (Processing Path) جدا کرده است.
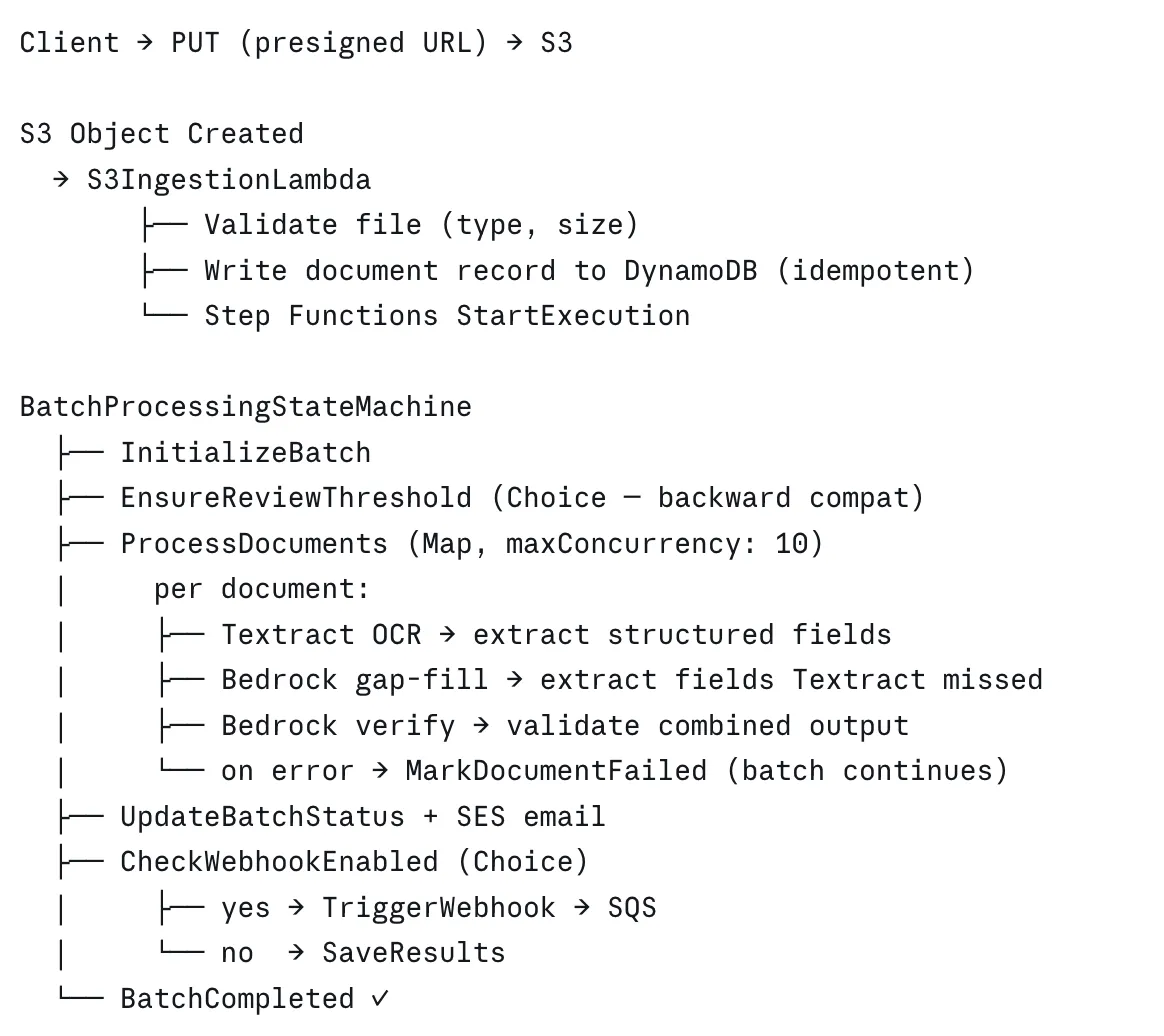
جریان درخواست (Request Flow)
این سیستم از دو جریان متمایز برای تضمین پایداری استفاده میکند. مسیر ارسال بهصورت همگام (Synchronous) است و بلافاصله پاسخ میدهد؛ تنها وظیفه هندلر API این است که درخواست را بپذیرد، رکوردهای اولیه را بنویسد و وضعیت ۲۰۲ (Accepted) را برگرداند. در مقابل، مسیر پردازش بهطور کامل نامتقارن است و توسط S3 فعال (Trigger) میشود.
انتخاب یک Trigger از S3 بهجای فراخوانی مستقیم Step Functions از طریق API، یک اقدام ایمنی عمدی است. اگر Step Functions در حین آپلود دچار یک مشکل گذرا (Transient Issue) شود، رویداد S3 بهطور خودکار در صف قرار گرفته و دوباره تلاش میکند، بدون اینکه کلاینت هرگز متوجه این موضوع شود یا اهمیتی بدهد.
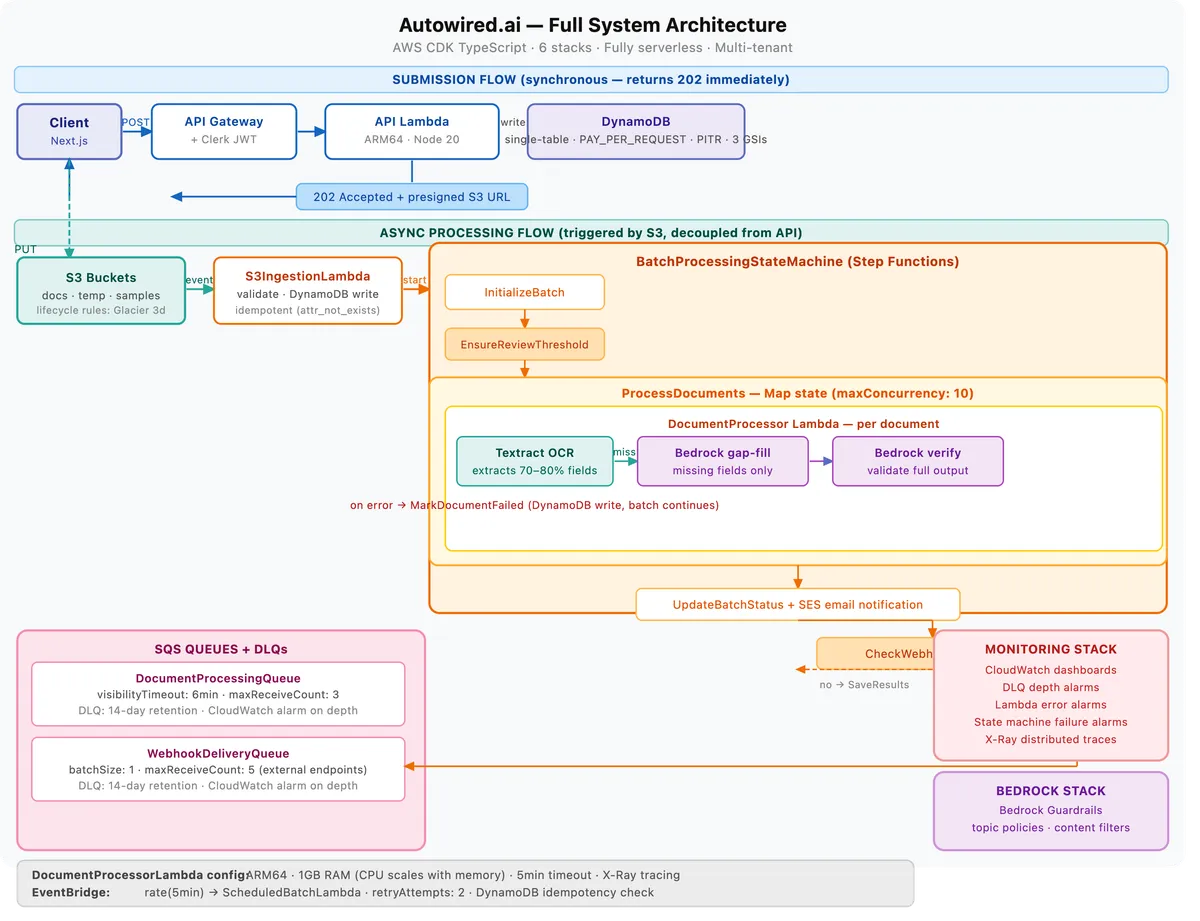
زیرساخت ششلایه (The Six-Stack Infrastructure)
تیم مهندسی برای جلوگیری از تلهی «پشته یکپارچه» (Monolithic Stack) در AWS CDK، زیرساخت خود را به ۶ پشته با اهداف مجزا تقسیم کرده است. این یک انتخاب عملیاتی است: بهروزرسانی خط لوله پردازش نباید باعث ایجاد تغییرات CloudFormation در پایگاه داده یا API Gateway شود. این ساختار واحدهای استقرار مستقل و مجموعههای تغییر ایزوله فراهم میکند، هرچند پیچیدگی مدیریت وابستگیهای متقاطع بین پشتهها را افزایش میدهد.

- DatabaseStack: مدیریت طراحی تکجدولی (Single-table design) در DynamoDB، تعاریف شاخصهای ثانویه جهانی (GSI)، بازیابی نقطه-در-زمان (PITR) و زمان انقضای دادهها (TTL).
- StorageStack: مدیریت باکتهای S3، قوانین چرخه حیات (Lifecycle Rules) و اعلانهای رویداد S3.
- ProcessingStack: شامل ماشین وضعیت Step Functions، تابع DocumentProcessorLambda، صفهای SQS به همراه صفهای پیامهای ناموفق (DLQ) و تابع ScheduledBatchLambda.
- BedrockStack: مدیریت حفاظهای Bedrock (Guardrails)، شامل پالیسیهای موضوعی و فیلترهای محتوایی.
- APIStack: میزبان API Gateway و تمامی هندلرهای Lambda برای API که از احراز هویت Clerk JWT استفاده میکنند.
- MonitoringStack: مدیریت داشبوردهای CloudWatch و هشدارها برای عمق DLQ، خطاهای Lambda و شکستهای ماشین وضعیت.
برای حل مشکل وابستگی چرخشی (Circular Dependency) — جایی که StorageStack به ARN پشته پردازش نیاز دارد و بالعکس — تیم تصمیم گرفت ARN ماشین وضعیت را بهجای استفاده از خروجیهای متقاطع (Cross-stack exports)، بهصورت تعیینگر (Deterministic) و بر اساس یک قرارداد نامگذاری محاسبه کند: const stateMachineArn = arn:aws:states:${region}:${account}:stateMachine:autowire-batch-processing-${stage};. این امر باعث میشود قرارداد نامگذاری به یک «زیرساخت تحملکننده» تبدیل شود، به این معنا که هرگونه تغییر نام مستلزم بهروزرسانی در هر دو پشته است.

خط لوله پردازش اسناد (The Document Processing Pipeline)
پردازش در سه مرحله متوالی در یک وضعیت Map در Step Functions انجام میشود:
۱. استخراج با Textract: ابزار Amazon Textract فیلدهای ساختاریافته را استخراج میکند. برای صورتحسابها و فرمهای استاندارد، این ابزار بهطور قابل اعتمادی ۷۰ تا ۸۰ درصد از فیلدهای هدف را با اطمینان بالا شناسایی میکند.
۲. پر کردن شکاف با Bedrock: مدل Bedrock فیلدهایی را که Textractพลาด کرده است، استخراج میکند. در این مرحله، تنها بخشهای OCR مربوط به فیلدهای گمشده به Bedrock ارسال میشوند، نه کل سند.
۳. تأیید توسط Bedrock: مدل Bedrock خروجی ترکیبی (نتایج Textract + پر کردن شکاف) را اعتبارسنجی کرده، امتیازات نهایی اطمینان را اختصاص میدهد و فیلدهایی را که نیاز به بازبینی انسانی دارند، علامتگذاری میکند.
این رویکرد لایهای، محرک اصلی کاهش هزینههای Bedrock است. با محدود کردن دامنه اثر LLM به پر کردن شکافها و تأیید نهایی، سیستم از هزینههای بالای توکنهای ناشی از ارسال کل اسناد به یک مدل بنیادی اجتناب میکند.
بهینهسازی برای مقیاس و هزینه
عملکرد و هزینه از طریق محدودیتهای سختافزاری و همزمانی خاص مدیریت میشوند:
- ARM64 (Graviton2): تمام توابع Lambda روی Graviton2 اجرا میشوند که بهطور متوسط ۲۰ درصد ارزانتر از پردازندههای x86 در هر گیگابایت-ثانیه هستند. در بارهای کاری محدود به I/O، تأخیر مشابه یا حتی بهتری مشاهده میشود.
- ۱ گیگابایت رم: تخصیص CPU در Lambda متناسب با حافظه است. این مقدار حافظه، تجزیه سریع JSONهای حجیم خروجی Textract را تضمین میکند که گلوگاه اصلی سیستم است.
- مهلت ۵ دقیقهای (Timeout): پردازش PDFهای چندصفحهای در Textract به همراه دو فراخوانی Bedrock میتواند در مسیرهای Cold Path نزدیک به ۳۰ ثانیه برای هر سند زمان ببرد؛ مهلت ۵ دقیقهای فضای لازم را برای این عملیات فراهم میکند.
- ردیابی X-Ray: استفاده از این ابزار برای شناسایی دقیق نقاط کند در زمانی که یک دسته پردازش ۳ برابر کندتر از حد انتظار اجرا میشود، غیرقابل چشمپوشی است.
- محدودیتهای همزمانی (Concurrency): وضعیت Map روی
maxConcurrency: 10محدود شده است. این یک قرارداد بر اساس سهمیههای سرویس AWS برای Textract و Bedrock است. اجرای ۵۰ پردازش همزمان منجر به خطاهای ۴۲۹ (Throttling) شده و به دلیل تکرار تلاشها با تأخیر (Retry Backoff)، زمان کلی دسته را افزایش میدهد.
در حالت ۱۰ کارگر همزمان و حدود ۱۵ ثانیه برای هر سند، یک دسته ۱۰۰ تایی حدود ۱۵۰ ثانیه و یک دسته ۵۰۰ تایی حدود ۷۵۰ ثانیه (تقریباً ۱۲ دقیقه) زمان میبرد که برای پردازش پسزمینه کاملاً قابل قبول است.
جداسازی ساختاری مستأجران (Structural Tenant Isolation)
امنیت در لایه داده اعمال میشود، نه در لایه اپلیکیشن. همه دادهها در یک جدول واحد DynamoDB قرار دارند که در آن tenantId در هر کلید پارتیشن (Partition Key) گنجانده شده است. این طراحی تضمین میکند که یک کوئری بهطور فیزیکی نمیتواند دادههای مستأجر دیگر را بازگرداند و ریسک لایههای میانی (Middleware) 잘못 پیکربندی شده یا فیلترهای فراموش شده را حذف میکند.

سه شاخص ثانویه جهانی (GSI) برای مدیریت الگوهای دسترسی خاص استفاده میشوند:
- GSI1: جستوجوی کاربر بر اساس ایمیل و لیست گردشهای کاری مرتب شده بر اساس تاریخ.
- GSI2: یک شاخص پراکنده (Sparse Index) برای فیلتر کردن بر اساس وضعیت. تنها وضعیتهای پردازش فعال در ویژگیهای GSI مینویسند که باعث کاهش هزینههای ذخیرهسازی و تقویت نوشتن (Write Amplification) میشود.
- GSI3: جستوجوی مستقیم دستهها تنها با
batchIdکه Step Functions را از ساختار کلید اصلی جدول جدا میکند.
مهندسی شکست (Failure Engineering)
معماری سیستم «اول-شکست» (Failure-first) طراحی شده و مسیرهای بازیابی پیش از مسیرهای موفقیت تعریف شدهاند:
- شکستهای در سطح سند: دستور
addCatchشکستها را به مرحلهMarkDocumentFailedهدایت میکند. یک PDF خراب تنها وضعیت خودش را در DynamoDB به FAILED تغییر میدهد و اجازه میدهد وضعیت Map برای بقیه دسته ادامه یابد. - شکستهای وبهوک: این موارد در یک صف SQS مجزا با
maxReceiveCount: 5(بیشتر از ۳ در صف سند) وbatchSize: 1ایزوله شدهاند تا تلاشهای مجدد برای نقاط انتهایی خارجی ناپایدار بهصورت مستقل انجام شود. - تحویل حداقل-یکبار S3: تابع
S3IngestionLambdaدر هر نوشتن از شرطattribute_not_exists(PK)استفاده میکند تا تحویلهای دوم اثر گذاشته نشوند و بهطور خاموش شکست بخورند. - محرکهای زمانبندی شده: EventBridge با
retryAttempts: 2پیکربندی شده تا از نادیده گرفته شدن اجراها به دلیل Cold Startهای Lambda جلوگیری شود. - مهلت ماشین وضعیت: یک محدودیت ۲۴ ساعته تضمین میکند که اجراهای متوقف شده در نهایت خاتمه یابند.
- نظارت بر DLQ: هر دو صف DLQ پیامها را تا ۱۴ روز نگه میدارند و یک هشدار CloudWatch روی عمق DLQ > 0 باعث بررسی فوری تیم میشود.
تصمیمات بلندمدت هزینه و منطق
چندین انتخاب معماری، هزینههای جاری را به حداقل میرساند:
- DynamoDB PAY_PER_REQUEST: برای مدیریت ارسالهای دستهای bursty بدون پرداخت هزینه برای ظرفیتهای رزرو شده و بیکار.
- قواعد چرخه حیات S3: اسناد بعد از ۳ روز به Glacier منتقل شده و بعد از ۶ ماه منقضی میشوند. مصنوعات موقت پردازش برای جلوگیری از انباشت ابدی، بعد از ۲۴ ساعت حذف میشوند.
- منطق اول-Textract: با استفاده از Bedrock تنها برای وظایف تخصصی، مصرف توکنها را بهطور چشمگیر کاهش میدهد.
در بازبینی نهایی، تیم سه مورد را برای تکرارهای آینده شناسایی کرد: پیادهسازی پالیسی RETAIN در DynamoDB از روز اول برای جلوگیری از دست رفتن تصادفی دادهها حین تستها، مستندسازی صریح قرارداد نامگذاری ARN ماشین وضعیت برای توضیح trade-off وابستگی چرخشی، و ابزارگذاری الگوهای کوئری DynamoDB در مراحل زودتر برای شناسایی سریعتر مشکلات طراحی GSI.
این رویکرد، شیوه ساخت SaaSهای هوش مصنوعی را تغییر میدهد و ثابت میکند که کارآمدترین پیادهسازی LLM اغلب آن است که از LLM کمتر استفاده کند. با تبدیل مدل بنیادی به یک ابزار دقیق برای تأیید بهجای یک موتور استخراج خشن، توسعهدهندگان میتوانند هزینه هر سند را بهشدت کاهش داده و در عین حال قابلیت اطمینان را افزایش دهند.



گفتگو