
آیا سیستمی وجود دارد که بتواند دهها صفحه سند را در یک مرحله پردازش کند بدون آنکه حافظهٔ سختافزاری را به کام بگیرد؟ سامانه جدید Unlimited OCR محصول شرکت Baidu ثابت کرد که این امر ممکن است.
این مدل با تقلید از شیوهٔ کپیبرداری انسانها — تمرکز بر پنجرهای کوچک از پیشرفت فعلی و اجازه دادن به محو شدن دادههای قدیمی — رشد خطی حافظه را که معمولاً سرعت تولید متن در اسناد طولانی را کاهش میدهد، حذف کرده است.
مشکل حافظه در سیستمهای سنتی
به نقل از مستندات فنی این پروژه، سیستمهای سنتی نویسهخوانی نوری (OCR) سرانه-به-سرانده از مدلهای زبانی به عنوان رمزگشدا استفاده میکنند. این یعنی با هر خط متن جدید، بافر حافظه یا همان KV Cache (حافظهٔ کلید-مقدار) رشد میکند و در نتیجه مصرف حافظه بالا رفته و سرعت تولید متن بهتدریج کاهش مییابد. برای جلوگیری از این اتفاق، اکثر سیستمها مجبورند اسناد را صفحه به صفحه پردازش کنند و در هر مرحله حافظه را بازنشانی کنند. این چالش با تلاشهای گسترده برای بهینهسازی زیرساختی، مانند آنچه در پروژه ارکایو برای کاهش ۹۰ درصدی فشار حافظه KV دیدیم، همسو است.
رویکرد Baidu که در ۵ ژوئیه ۲۰۲۶ منتشر شد، این چرخه با یک صف با طول ثابت جایگزین کرد. تیم توسعه این مشکل را با یک مثال انسانی تعریف میکنند: کسی که در حال کپی کردن یک کتاب است، تمام آنچه را که قبلاً نوشته بازخوانی نمیکند؛ بلکه فقط چشمش به منبع، چند نویسهٔ آخر و نویسهٔ بعدی است و بخشهای قدیمیتر بهصورت تدریجی از طریق نوعی «فراموشی نرم» محو میشوند. این مفهوم «فراموشی» در یادگیری ماشین، ما را به یاد تکنیکهای مقابله با تداخل گرادین برای توقف فراموشی مدلها میاندازد که بر حفظ اطلاعات کلیدی متمرکز بود.
همانطور که در تحلیلهای پیشین ما دربارهی بهینهسازی حافظه در ترنسفورمرها اشاره کردیم، مدیریت بهینهٔ بافرها کلید دستیابی به مقیاسپذیری در مدلهای زبانی است.
سازوکار توجه پنجرهٔ لغزان مرجع
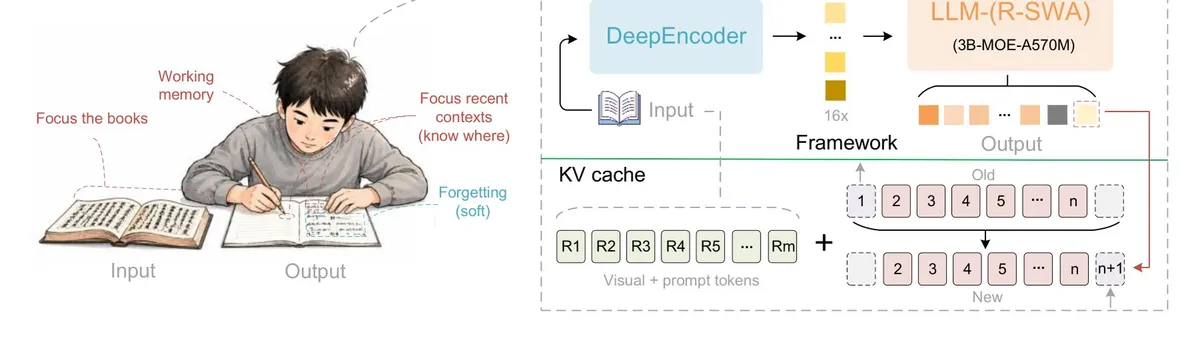
مکانیسم اصلی این سیستم توجه پنجرهٔ لغزان مرجع (Reference Sliding Window Attention یا R-SWA) نام دارد. در این معماری، هر توکن (Token) تولید شده همچنان میتواند تمام توکنهای مرجع، شامل توکنهای تصویری و پرامپت اولیه را ببیند. با این حال، هنگام بررسی خروجیهای قبلی، مدل تنها به ۱۲۸ توکن آخر نگاه میکند. این سازوکار تضمین میکند که حجم KV Cache بدون توجه به طول خروجی، ثابت بماند.
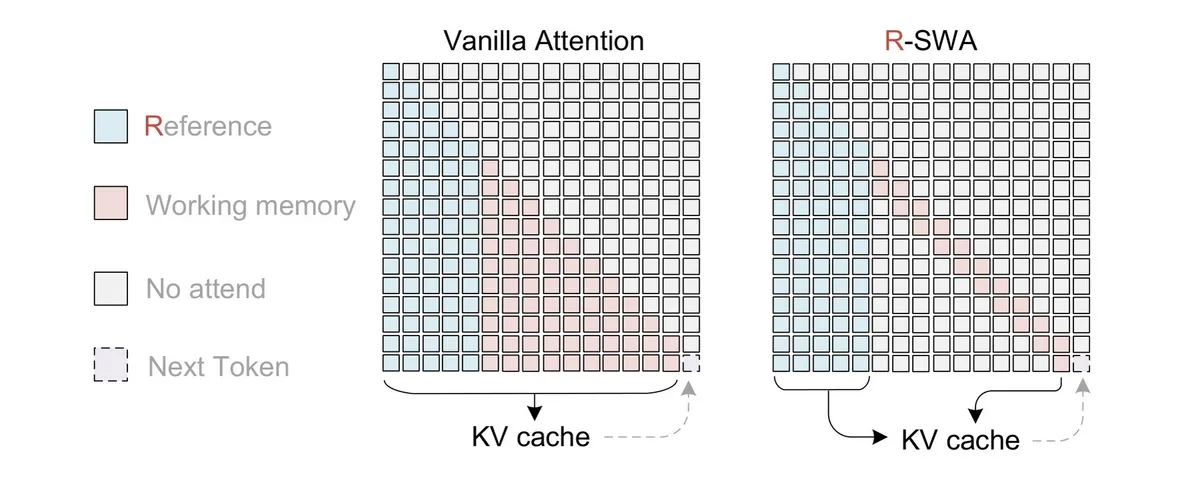
در روشهای استاندارد، توجه پنجره لغزان معمولاً توکنهای بصری را نیز در معرض تغییرات وضعیت قرار میدهد که باعث محو شدن تدریجی ویژگیهای تصویر و در نهایت افت دقت تشخیص میشود. اما R-SWA با معاف کردن توکنهای بصری از این تغییرات، آنها را یکبار کدگذاری کرده و ثابت نگه میدارد. در نتیجه، حافظه مانند یک صف عمل میکند که هر توکن جدید، قدیمیترین توکن را بیرون میراند. در حالی که مصرف حافظه در توجه چندسر (Multi-Head Attention) بهطور نامحدود رشد میکند، R-SWA آن را در مجموع ثابتِ «طول پیشوند + اندازه پنجره» محدود میکند.
معماری فنی و مقیاس آموزش
سامانه Unlimited OCR بر پایه مدل متنباز Deepseek OCR بنا شده و تغییرات کلیدی زیر را دارد:
- رمزگشدا: معماری ترکیب خبرهها (Mixture of Experts یا MoE) با ۳ میلیارد پارامتر کلی. برای بهینهسازی، تنها حدود ۵۰۰ میلیون پارامتر در زمان استنتاج (Inference) فعال هستند. همچنین، هر لایه توجه استاندارد در رمزگشدا با R-SWA جایگزین شده است.
- DeepEncoder: این بخش تصاویر PDF با ابعاد ۱۰۲۴ در ۱۰۲۴ پیکسل را به ۲۵۶ توکن فشرده میکند. این رمزگذار دو حالت دارد: حالت Base برای مدیریت اسناد چندصفحهای و حالت Gundam که از وضوح پویا (Dynamic Resolution) برای تکصفحهها استفاده میکند.
- مقیاس آموزش: مدل روی تقریباً ۲ میلیون نمونه سند آموزش دیده است (نسبت ۹ به ۱ بین دادههای تکصفحهای و چندصفحهای). برای برچسبگذاری صفحات تکصفحهای از Paddle OCR استفاده شد، در حالی که دادههای چندصفحهای بهصورت مصنوعی از طریق چسباندن صفحات تکصفحهای در بازه ۲ تا ۵۰ صفحه تولید شدند.
- سختافزار و گامها: تمام دادهها در توالیهایی به طول ۳۲,۰۰۰ توکن بستهبندی شدند. آموزش در ۴,۰۰۰ گام روی ۱۲۸ عدد GPU مدل Nvidia A800 (در ترکیب ۸ در ۱۶) انجام شد. در این فرآیند، DeepEncoder منجمد (Frozen) باقی ماند و تنها پارامترهای مدل زبانی بهروزرسانی شدند.
بنچمارکها و عملکرد
طبق گزارش نویسندگان، این مدل در محک OmniDocBench v1.5 به امتیاز کلی ۹۳٪ دست یافته که ۶ درصد بالاتر از خط پایه Deepseek OCR است و در نسخه v1.6 با امتیاز ۹۳.۹۲٪ در صدر رتبهبندی سیستمهای سرانه-به-سرانده قرار گرفته است.
بهبودهای مشخص عبارتند از:
- تشخیص متن: نرخ خطای تشخیص متن خالص (که با فاصله ویرایشی یا Edit Distance اندازهگیری میشود) بهطور جزئی کاهش یافت.
- ساختار: تشخیص ساختار جداول با جهشی چشمگیر و نزدیک به ۶ درصد بهبود یافت.
- پایداری در بازه بلند: در آزمایشهای پردازش بیش از ۴۰ صفحه در یک مرحله، نرخ خطا زیر ۰.۱۱ و امتیاز Distinct-35 در سطح ۹۷٪ باقی ماند.
دستاوردها در سرعت نیز چشمگیر است. در حالت Base، مدل Unlimited OCR به سرعت ۵,۵۸۰ توکن در ثانیه میرسد که ۱۲.۷٪ بیشتر از ۴,۹۵۱ توکن در ثانیه در Deepseek OCR است.
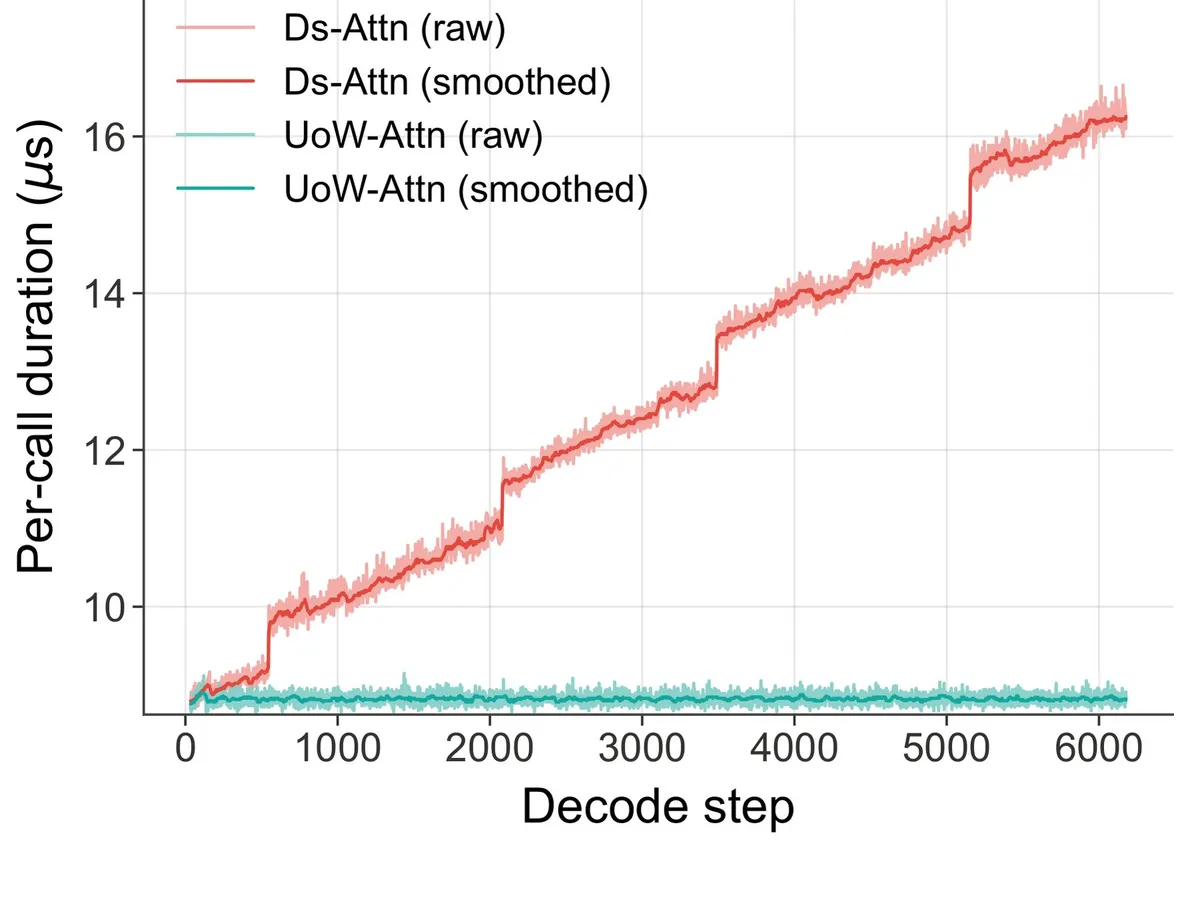
نکته حیاتی این است که تأخیر هسته (kernel latency) با افزایش طول سند، کاملاً ثابت میماند. در حالی که تأخیر در Deepseek OCR با هر گام افزایش مییابد، Unlimited OCR سرعت خود را حفظ میکند. در یک مقایسه تئوریک با فرض موازیسازی ایدهآل در مرزهای فوقانی، این مدل در خروجیهای حدود ۶,۰۰۰ توکنی، ۳۵٪ برتر از مدل پایه است، در حالی که نرخ پردازش (Throughput) مدل پایه با افزایش طول سند بهطور مداوم افت میکند.
تحلیل خطاها و دقت
پژوهشگران اشاره کردند خطاهای باقیمانده عمدتاً به دلیل محدودیت وضوح در حالت Base هنگام مواجهه با متنهای بسیار کوچک است، نه بهدلیل از دست رفتن حافظه یا مشکلات جهتگیری ناشی از R-SWA. جالب این است که محدود کردن پنجره به ۱۲۸ توکن در صفحات تکصفحهای نه تنها دقت را کم نکرد، بلکه باعث بهبود جزئی شد. تیم توسعه حدس میزند R-SWA مدل را مجبور میکند بهجای پراکندهگی (Divergence) که در توجه کامل با رشد طول خروجی رخ میدهد، تمرکز شدیدتری روی وظیفه متراکم OCR داشته باشد.
پیامدهای گسترده و مسیر آینده
این تکنیک ثابت میکند کارهای مرجعمحور — از جمله بازشناسی گفتار و ترجمه — میتوانند از رشد خطی حافظه جدا شوند. همچنین راهی برای استفاده از متنهای تصویر-محور جهت گسترش حافظه مدلهای زبانی برای تاریخچههای چت عظیم یا اسناد بسیار حجیم باز میکند، چرا که تصاویر از نظر محاسباتی بهینهتر از متن دیجیتال هستند. توسعهدهندگان در حال حاضر مفاهیم مشابهی را برای کاهش هزینه توکنها در Fable 5 شرکت Anthropic به کار میبرند.
این اثر در فضای رقابتی شدیدی منتشر شده است. مدل OCR 2 شرکت Deepseek از رمزگذاری استفاده میکند که اطلاعات تصویر را بهصورت معنایی بازآرایی کرده و امتیاز ۹۱.۰۹٪ در OmniDocBench v1.5 کسب کرده است. در همین حال، Mistral AI در حال توسعه Mistral OCR 3 برای بهبود تشخیص دستخط و جداول پیچیده است. برای Baidu، این پیشرفت مکمل عرضه Ernie 5.1 است؛ مدل چندوجهی که در LMArena برای مدلهای چینی رتبه اول را کسب کرد.
Baidu قصد دارد محدودیت فعلی ۳۲ هزار توکن را به ۱۲۸ هزار توکن افزایش دهد و در حال توسعه یک استخر پیش-پر (prefill pool) است تا مدل بتواند بهصورت خودکار بلوکهای KV مرتبط را بازیابی کند — درست مانند ورق زدن یک کتاب برای یافتن مطلب. کدها و وزنهای مدل در GitHub و Hugging Face در دسترس هستند و از ModelScope و موتورهای استنتاج مانند vLLM و SGLang پشتیبانی میکنند. همچنین یک دموی تعاملی در Hugging Face Spaces قرار دارد.
گام بعدی شما
- اگر از vLLM یا SGLang برای سرویسدهی مدل استفاده میکنید، وزنهای منتشرشده در Hugging Face را برای تست بهرهوری در اسناد طولانی بررسی کنید.
- معماری R-SWA را برای کارهای بازشناسی گفتار (ASR) که با مشکل طول توالی مواجهاند، به عنوان جایگزینی برای Attention استاندارد بررسی کنید.
- دموی موجود در Hugging Face Spaces را با اسنادی بیش از ۴۰ صفحه به چالش بکشید تا پایداری نرخ خطا را بسنجید.
اما اثر این بهینهسازی بر هزینههای استنتاج در مقیاس تجاری حتی پیچیدهتر است — به تحلیل ما درباره استراتژیهای کاهش هزینه در مدلهای MoE مراجعه کنید.



گفتگو