
پردازش یک فایل PDF با ۴۰ صفحه معمولاً منجر به یک مارپیچ حافظه میشود، زیرا KV Cache با هر توکن تولید شده رشد میکند. اما شرکت بایدو (Baidu) با معرفی Unlimited OCR، مدلی با ۳ میلیارد پارامتر، این گلوگاه را شکست و پروفیل حافظه را در تمام طول فرآیند تبدیل متن، ثابت نگه داشت.
طبق گزارش منتشر شده، این مدل مکانیزمی را رسمی میکند که از «کندی تولید» (generation drag) در سیستمهای نویسهخوانی نوری (OCR) سرتاسری جلوگیری میکند. در ساختار توجه چندسر (Multi-Head Attention) استاندارد، حافظه و تأخیر با افزایش طول خروجی به صورت نامحدود رشد میکنند. این اندازه به صورت فرمول CMHA(T) = Lm + T تعریف میشود که در آن T طول خروجی است. همانطور که در تحلیل قبلی ما دربارهی قابلیتهای پردازش بازه بلند بایدو اشاره کردیم، این مدل اکنون با تغییر فرمول محاسباتی، این وابستگی خطی را حذف کرده است. این تلاش برای بهینهسازی مصرف حافظه، یادآور راهکارهای دیگری است که در استراتژیهای کوانتش و مدیریت اپیزودیک برای کاهش ۸ برابری حجم KV Cache مورد بررسی قرار گرفتند تا بهرهوری مدلها در توالیهای بلند افزایش یابد.
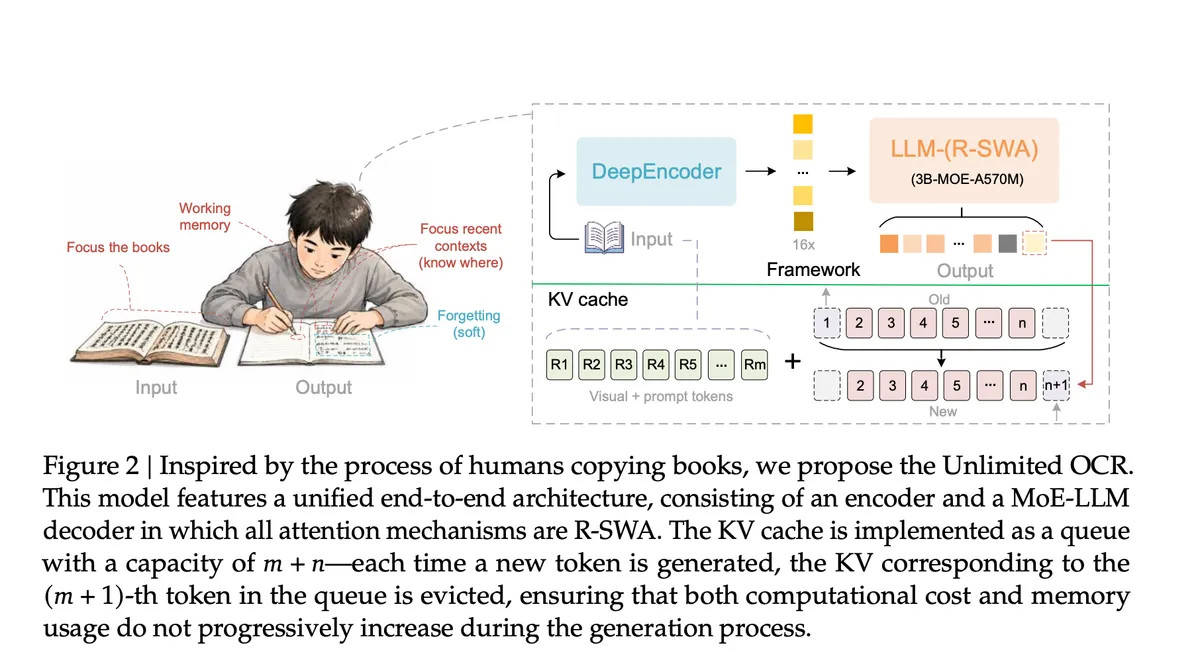
برای دستیابی به این هدف، بایدو از توجه پنجره لغزان مرجع (Reference Sliding Window Attention یا R-SWA) استفاده کرده است. این روش را میتوان نوعی «فراموشی نرم» دانست؛ درست مانند کسی که هنگام کپی کردن یک کتاب، به جای بازخوانی تمام صفحات قبلی، فقط به منبع اصلی و چند کلمه آخرِ نوشتههای خود نگاه میکند.
معماری فنی
Unlimited OCR یک مدل ترکیب خبرهها (Mixture-of-Experts یا MoE) است. با وجود ۳ میلیارد پارامتر کلی، تنها ۵۰۰ میلیون پارامتر در زمان استنتاج (Inference) فعال هستند که هزینه محاسباتی را پایین میآورد. این سامانه از یک DeepEncoder به عنوان موتور فشردهسازی استفاده میکند که ترکیبی از SAM-ViT تحت توجه پنجرهای و CLIP-ViT تحت توجه جهانی است.
مشخصات کلیدی این معماری عبارت است از:
- فشردهسازی ۱۶ برابری توکنها: یک تصویر PDF با ابعاد ۱۰۲۴x۱۰۲۴ به تنها ۲۵۶ توکن بصری تبدیل میشود که باعث کاهش حجم پیشپُرکردن (prefill) میگردد.
- اندازه حافظه پنهان ثابت: حافظه یک صف ثابت است که با مقدار (Lm + n) محدود شده و n به طور پیشفرض ۱۲۸ توکن است. فرمول آن به صورت CR-SWA(T) = Lm + min(n, T) ≤ Lm + n تعریف میشود.
- پنجره زمینه: این مدل از حداکثر ۳۲ هزار توکن پشتیبانی میکند.
- حالتهای رزولوشن: مدل دارای دو حالت است: حالت Base با ابعاد ۱۰۲۴x۱۰۲۴ برای اسناد چندصفحهای و حالت Gundam که از رزولوشن پویا برای پردازش تک-صفحهها استفاده میکند.
بنچمارکهای عملکردی
بر اساس مستندات مقاله پژوهشی (arXiv:2606.23050)، این مدل از صفر آموزش ندیده است. تیم توسعهدهنده، مدل را بر پایه یک نقطه بازرسی (checkpoint) از DeepSeek OCR و برای ۴,۰۰۰ گام آموزش تکمیلی دادهاند. آنها DeepEncoder را منجمد کرده و تنها دکودر را با استفاده از ۲ میلیون نمونه سند روی ۸ خوشه از GPUهای A800 آموزش دادند. دادههای آموزشی از یک تقسیمبندی ۹ به ۱ به نفع دادههای تک-صفحهای استفاده کردند و نمونههای چندصفحهای از طریق الحاق (concatenation) ایجاد شدند.
در محک OmniDocBench v1.5، مدل Unlimited OCR امتیاز ۹۳.۲۳ را کسب کرد و ۶.۲۲ امتیاز بالاتر از مدل پایه DeepSeek OCR قرار گرفت. جزئیات عملکرد در دستههای مختلف به شرح زیر است:
- ویرایش متن (Text Edit): ۰.۰۳۸ (در برابر ۰.۰۷۳ برای DeepSeek-OCR)
- فرمولهای CDM: ۹۲.۶۱ (در برابر ۸۳.۳۷ برای DeepSeek-OCR)
- جداول TEDS: ۹۰.۹۳ (در برابر ۸۴.۹۷ برای DeepSeek-OCR)
- ترتیب خواندن (Read-order): ۰.۰۴۵ (در برابر ۰.۰۸۶ برای DeepSeek-OCR)
در نسخه v1.6 این محک، مدل به امتیاز کلی ۹۳.۹۲ رسید که بالاترین امتیاز در مقایسههای این مقاله است. همچنین سرعت تولید در حالت Base به ۵,۵۸۰ توکن در ثانیه (TPS) رسید که ۱۲.۷٪ افزایش نسبت به مدل پایه (۴,۹۵۱ TPS) است. این شکاف سرعت زمانی که سقف خروجی به ۶,۰۰۰ توکن میرسد، تا ۳۵٪ افزایش مییابد.
کاربردهای عملی و پیادهسازی
این معماری دقیقاً برای بارهای کاری طراحی شده که سیستمهای صفحهبه-صفحه در آنها شکست میخورند. کاربردهای اصلی عبارتند از:
- تبدیل کامل کتابها: پردازش بیش از ۴۰ صفحه در یک گذر پیوسته؛ جایی که فاصله ویرایشی زیر ۰.۱۱ باقی میماند و معیار Distinct-35 برابر با ۹۶.۹۰٪ است.
- خط لوله استخراج اسناد: استخراج همزمان متن، جداول، فرمولها و ترتیب خواندن در یک گذر رفت (Forward Pass).
- پردازش دستهای با توان بالا: استفاده از اسکریپت
infer.pyبرای راهاندازی سرور SGLang جهت مدیریت درخواستهای همزمان روی پوشههای PDF.
تحلیل تحریریه
برای متخصصان فنی، این تغییر در واقع جایگزینی یک مشکل رشد خطی با یک مقدار ثابت است. حیاتیترین تغییر این است که R-SWA با توکنهای بصری به عنوان مراجع دائمی برخورد میکند که هرگز دچار بهروزرسانی حالت (state update) نمیشوند. این امر از پدیده «تاری تدریجی» (progressive blurring) که در مدلهای توجه خطی دیده میشود، جلوگیری میکند.
این ویژگی Unlimited OCR را برای پردازش دستهای با توان بالا از کتابهای کامل یا آرشیوهای پیچیده شرکتی منحصربهفرد میکند. با تثبیت تأخیر، بایدو محدودیت اصلی را از «رشد حافظه» به «زمان پیشپُرکردن اولیه» تغییر داده است؛ زمانی که همچنان با افزایش تعداد صفحات رشد میکند.
با وجود این نقاط قوت، مدل به معنای واقعی کلمه «نامحدود» نیست؛ بلکه همچنان توسط پنجره زمینه ۳۲ هزار توکنی محدود شده است. علاوه بر این، اجرای چندصفحهای به حالت Base وابسته است، به این معنی که ممکن است متون بسیار ریز نادیده گرفته شوند.
کاربران در حال حاضر میتوانند مدل را از طریق کتابخانه Transformers با فعال کردن trust_remote_code=True مستقر کنند یا آن را به عنوان یک API سازگار با OpenAI با استفاده از سرور SGLang و بکاِند توجه fa3 اجرا نمایند. باید منتظر ماند و دید آیا مکانیزم R-SWA به سایر وظایف توالی-به-توالی مانند بازشناسی خودکار گفتار (ASR) یا ترجمههای طولانی منتقل میشود یا خیر، زیرا پژوهشگران ادعا میکنند که این یک توجه پارسکنندهی همهمنظوره است.



گفتگو