اگر امروز مالک یک سامانه باتری صنعتی هستید، تفاوت بین سودآوری و ضرر شما در گرو میلیثانیههایی است که تصمیم میگیرید برق را بخرید یا بفروشید. در محیطی که قیمتها هر ساعت تغییر میکنند، تکیه بر حدس و گمان یا قوانین ساده، یعنی پذیرش ضرر خالص.
طبق گزارش منتشرشده در ۲۳ ژوئن ۲۰۲۶، پروژهای به نام بهینهساز انرژی شبکه هوشمند (Smart Grid Energy Optimizer) نشان داد که یادگیری تقویتی عمیق (Deep Reinforcement Learning یا DRL) — شبیه به ورزشکاری که با هر اشتباه در تمرین، تکنیک خود را برای مسابقه واقعی اصلاح میکند — میتواند فرآیند خرید و فروش برق یا همان «آربیتراژ انرژی» را بهطور خودکار و با دقتی بسیار بالاتر از دستورات انسانی مدیریت کند. این پروژه ثابت کرد که DRL میتواند در یک محیط انرژی شبیهسازی شده، عملکردی بسیار بهتر از روشهای متداول انسانی داشته باشد.
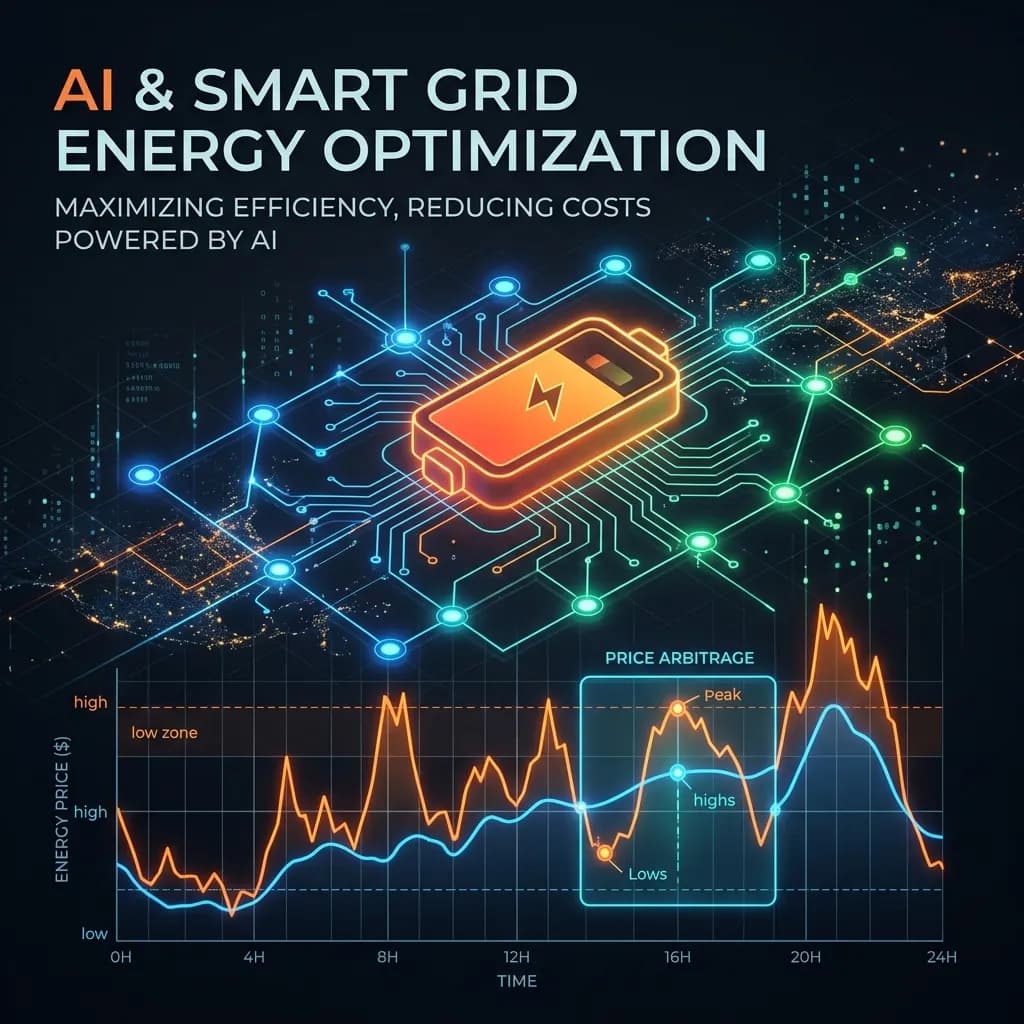
در بخش انرژی مدرن، قیمتها هر ساعت بهشدت نوسان میکنند. ساعت ۳ صبح، وقتی توربینهای بادی میچرخند اما جمعیت شهر در خواب است، برق بسیار ارزان است و گاهی قیمت آن تا ۶ سنت در کیلوواتساعت کاهش مییابد. اما ساعت ۶ عصر، زمانی که خورشید غروب میکند و ساکنان خانهها کولرها و اجاقهای برقی خود را روشن میکنند، شبکه برق تحت فشار شدیدی قرار میگیرد. در طول این بحرانها، قیمتها میتوانند بهشدت جهش کنند و به ۶۰ سنت یا حتی ۲.۵ دلار برای هر کیلوواتساعت برسند.
برای مالکان باتریهای عظیم صنعتی، این نوسانات یک فرصت طلایی به نام «آربیتراژ انرژی» ایجاد میکند: خرید الکتریسیته زمانی که ارزان است، ذخیرهسازی آن در باتریها و فروش مجدد آن به شبکه (یا استفاده از آن برای تأمین برق ساختمان) در زمانی که قیمتها به اوج میرسند. چالش بنیادی این است که اپراتور باتری از آینده خبر ندارد و نمیداند قیمت دقیقاً چه زمانی بالا میرود. برای بررسی اینکه هوش مصنوعی چگونه این مشکل را حل میکند، پروژه بهینهساز انرژی شبکه هوشمند، یک عامل یادگیری تقویتی عمیق را در برابر روشهای اکتشافی انسانی و یک الگوریتم ریاضی کاملاً بینقص قرار داد.
بسیاری از مهندسان سعی میکنند این مسئله را با قوانین ساده یا همان Heuristics حل کنند. یک مهندس نرمافزار معمولی ممکن است اسکریپتی بنویسد که اگر قیمت فعلی کمتر از ۷۵٪ میانگین روزانه بود، باتری را شارژ کند و اگر بیشتر از ۱۲۵٪ آن میانگین بود، باتری را تخلیه نماید. در کدنویسی، این منطق به شکل زیر است:
def heuristic_trader(current_price, daily_average_price): if current_price < (daily_average_price * 0.75): return "CHARGE" elif current_price > (daily_average_price * 1.25): return "DISCHARGE" else: return "IDLE"
اگرچه این قوانین کاربردی هستند، اما بهشدت ناقصاند زیرا فاقد ظرافتهای لازم هستند. یک قانون ایستا نمیتواند تشخیص دهد که آیا یک جهش کوچک قیمت در ساعت ۲ بعدازظهر، نقطه اوج روز است یا اینکه قرار است یک جهش بسیار عظیمتر در ساعت ۶ عصر رخ دهد. علاوه بر این، اضافه کردن پنلهای خورشیدی به پشتبام، این منطق را بیش از حد پیچیده میکند. سیستم باید تصمیم بگیرد که آیا انرژی رایگان خورشیدی باید برای شارژ باتری استفاده شود یا مستقیماً برای کاهش تقاضای ساختمان به کار رود. کدنویسی دستی قوانین برای هر ترکیب ممکن از قیمت، زمان، تولید خورشیدی و بار مصرفی ساختمان، یک کابوس لجستیکی است.
سقف تئوریک و نفرین ابعاد
برای سنجش عملکرد AI، توسعهدهنده از برنامهریزی پویا (Dynamic Programming یا DP) استفاده کرد تا یک «سقف تئوریک» ایجاد کند. DP با فرض داشتن پیشبینی کامل از آینده (Perfect Foresight) — یعنی دسترسی جادویی به قیمت دقیق برق، خروجی خورشیدی و بار ساختمان برای هر ساعت از روز — بهینهترین برنامه شارژ ممکن را محاسبه میکند.
این سازوکار از طریق «استقراء معکوس» (Backward Induction) و با استفاده از معادله بلمن عمل میکند: V(s) = max_a [ Reward(s, a) + V(next_s) ]. در این روش، حلکننده بهجای شروع از ساعت ۱۲ شب، از ساعت ۲۴ شروع کرده و به عقب بازمیگردد تا به ابتدای روز برسد و بهترین تصمیمات را استخراج کند.
جزئیات مکانیسم DP به شرح زیر است:
- شبکه حالت (State Grid): حلکننده یک شبکه از تمام سطوح ممکن شارژ باتری (به عنوان مثال ۵۰ سطح مختلف) ایجاد میکند.
- تست اقدامات (Action Testing): این سیستم هر اقدام ممکن (در محدوده ۳- کیلووات تا ۳+ کیلووات) را برای هر ساعت از شبانهروز تست میکند.
- محاسبه ارزش (Value Calculation): با جمع کردن پاداش فوری با ارزش شناخته شده آینده، بهترین مقدار را مییابد:
total = reward + V[t + 1, get_index(next_soc)]. - بهینگی تضمینشده: چون DP تمام حالتهای ممکن را از انتهای روز به ابتدا بررسی میکند، تضمین میکند که برنامهای کاملاً بینقص ارائه دهد.
اما DP در دنیای واقعی غیرعملی است؛ پدیدهای که به آن «نفرین ابعاد» (Curse of Dimensionality) میگویند. در این شبیهسازی، با ۵۰ سطح شارژ و ۲۴ ساعت، حلکننده $50 \times 24 \times 7 \text{ actions} = 8,400$ ترکیب را بررسی کرد که در میلیثانیهها انجام شد. اما تصور کنید بخواهیم کارخانهای با ۱۰ باتری مستقل، ۱۰۰ ماشین صنعتی و پیشبینیهای تصادفی آبوهوا را مدیریت کنیم. در این حالت، ترکیبات حالتها به تریلیونها میرسد و محاسبات ریاضی سالها زمان میبرد. بنابراین، اجرای DP در لحظه (Real-time) از نظر فیزیکی غیرممکن است، اما به عنوان یک معیار عالی برای نمره دادن به هوش مصنوعی باقی میماند.
پیادهسازی شبکههای Q عمیق (DQN)
برای عملیاتی شدن بدون داشتن «گوی بلورین» برای دیدن آینده، سیستم از یک شبکه Q عمیق (DQN) استفاده میکند. برخلاف DP، عامل DQN نمیتواند آینده را ببیند. در هر ساعت، این عامل یک عکس ۸-بعدی (Observation Snapshot) از وضعیت شبکه دریافت میکند. این عکس از یک شبکه عصبی عبور میکند تا یک «مقدار Q» — که نشاندهنده سود مورد انتظار در آینده است — را برای هفت اقدام گسسته خروجی دهد: [-3kW, -2kW, -1kW, 0kW, +1kW, +2kW, +3kW].
آموزش DQN شامل یک حلقه خاص در PyTorch است که برای تخمین معادله بلمن بدون دانستن آینده طراحی شده است. این فرآیند مراحل کلیدی زیر را دنبال میکند:
۱. ارزش حالت فعلی: شبکه تعیین میکند که حالت فعلی چقدر میارزد: current_q_values = q_network(state).
۲. پیشبینی حالت بعدی: یک شبکه هدف (Target Network) ارزش حالت بعدی را پیشبینی میکند: max_next_q_value = next_q_values.max(1)[0].
۳. هدف بلمن: سیستم هدف را به صورت مجموع پاداش و مقدار تخمینی آینده محاسبه میکند: expected_q_value = reward + (gamma * max_next_q_value).
۴. کاهش خطا: شبکه بهروزرسانی میشود تا میانگین مربعات خطا (MSE) بین مقادیر پیشبینیشده و مقادیر مورد انتظار را به حداقل برساند.
مهندسی ویژگی: ترفند زمان چرخشی
یکی از جذابترین چالشها در یادگیری تقویتی (RL)، نحوه نمایش «حالت» (State) به شبکه عصبی است. اگر ساعت را به صورت یک عدد صحیح ساده به شبکه بدهیم (مثلاً ساعت ۲۳ برای ۱۱ شب)، پرش از ساعت ۲۳ به ساعت ۰ (نیمهشب) برای ریاضیات شبکه به عنوان یک ناهماهنگی و پرش بزرگ ظاهر میشود. برای حل این مشکل، توسعهدهنده از «رمزگذاری چرخشی» (Cyclic Encoding) استفاده کرد و ساعت ۲۴ ساعته را با استفاده از توابع سینوس و کسینوس روی یک دایره رسم کرد:
sin_time = np.sin(hour * np.pi / 12)cos_time = np.cos(hour * np.pi / 12)
به دلیل این روش، ساعت ۲۳ و ساعت ۰ از نظر ریاضی روی دایره در کنار هم قرار میگیرند. این امر به شبکه اجازه میدهد تا گذر زمان را بهطور نرم و بدون شوک ریاضی درک کند.
غلبه بر محدودیتهای فیزیکی و دادهای
فیزیک دنیای واقعی لایه دیگری از دشواری را اضافه میکند. شبیهساز یک بازدهی رفت و برگشتی ۹۲ درصدی را اعمال میکند. این بدان معناست که اگر ۱ کیلووات برق وارد باتری شود، ۸ درصد آن به دلیل گرمای تولید شده تلف میشود و فقط ۰.۹۲ کیلووات قابل بازیابی است. در نتیجه، خرید برق در ۱۰ سنت و فروش آن در ۱۰.۵ سنت، در واقع منجر به ضرر خالص میشود.
نکته شگفتانگیز این است که DQN هیچ کد صریحی درباره قوانین ترمودینامیک دریافت نکرد. مدل بهطور طبیعی کشف کرد که باید تنها زمانی معامله کند که «تفاوت قیمت» (Price Spread) بهقدری زیاد باشد که هزینه ۸ درصدی تلفات انرژی را پوشش دهد.
برای جلوگیری از اینکه AI صرفاً یک منحنی قیمت خاص را حفظ کند — و در واقع به یک «ساعت» تبدیل شود که فقط یاد گرفته در گام ۴ شارژ و در گام ۱۶ تخلیه کند — پروژه از «آموزش تصادفی» (Stochastic Training) استفاده کرد. این روش شامل موارد زیر است:
- نویز گوسی: هر قیمت در طول آموزش با ۱۲٪ نویز گوسی تغییر داده شد تا مدل به اعداد دقیق وابسته نباشد.
- عوامل ابری: تولید برق خورشیدی در ضرایب تصادفی ضرب شد تا نوسانات واقعی آبوهوا شبیهسازی شود.
این کار مدل را مجبور کرد تا رابطه علی (Causal Relationship) میان روند قیمت، خروجی خورشیدی و زمان رسیدن به اوج را یاد بگیرد، به جای اینکه صرفاً به برچسبهای زمانی تکیه کند. نتیجه این کار، یک استراتژی قدرتمند و تعمیمیافته است که میتواند در برابر هرج و مرج بازارهای واقعی دوام بیاورد.
سنجش شکاف هوش
در داشبورد تعاملی پروژه، سه استراتژی در یک روز مشابه با هم رقابت میکنند:
- قوانین دستنویس (Heuristic): معمولاً پایینترین عملکرد را دارند زیرا فاقد ظرافتهای لازم بوده و قادر به تطبیق با روندها نیستند.
- عامل DQN: در جایگاه میانی قرار میگیرد و با استفاده از شهودی که یاد گرفته است، در شرایط عدم قطعیت پیش میرود.
- حلکننده DP: برنده مطلق است که حداکثر سود ریاضی ممکن با پیشبینی کامل آینده را نشان میدهد.
شکاف مالی بین DQN و DP، در واقع اندازهگیری فیزیکی «شکاف هوش» است؛ یعنی هزینه ناشی از ندانستن آینده، به علاوه فضای موجود برای یادگیری و پیشرفت بیشتر هوش مصنوعی.
این گذار از قوانین سخت و صلب به عاملهای RL تطبیقپذیر، معیار مدیریت شبکه برق را تغییر میدهد. تمرکز از «نوشتن قانون درست» به «طراحی تابع پاداش درست» منتقل میشود. برای اپراتورها، این بدان معناست که میتوان داراییهای پیچیده انرژی را بدون افزایش تصاعدی هزینههای مهندسی، مقیاسبندی کرد.
گام بعدی شما
شما میتوانید این دینامیکها را از طریق شبیهساز شبکه هوشمند در Hugging Face Spaces تجربه کنید. برای درک واقعی مکانیسمها، این آزمایشها را انجام دهید:
- مسابقه بنچمارک: سناریوی Summer Peak را اجرا کنید. نمودار میلهای درآمد کل را مقایسه کنید تا ببینید DQN در مقایسه با بهینهی DP، چه مقدار سود را از دست داده است.
- تأثیر خورشید: در تب Dispatch، حالت Summer Peak (با آرایه خورشیدی ۵ کیلووات) را در ساعت ۱ بعدازظهر بررسی کنید. سپس آن را به No Solar تغییر دهید. مشاهده خواهید کرد که عامل کاملاً استراتژی خود را تغییر میدهد و برق گران شبکه را زودتر میخرد، زیرا دیگر به انرژی رایگان خورشیدی دسترسی ندارد.
- آموزش مغز: به Training Lab بروید، تعداد گامها را روی ۲۰,۰۰۰ قرار دهید و صعود منحنی پاداش را تماشا کنید؛ جایی که عامل در حال یادگیری «پاداش تأخیری» برای تخلیه باتری در ساعت ۶ عصر است.
آربیتراژ انرژی، زیبایی یادگیری تقویتی را در توازن بین هزینههای کوتاهمدت و سودهای بلندمدت در یک محیط نوسانی خلاصه میکند. این چهارمین پروژه از ۱۲ پروژه تعاملی RL است که برای پیوند دادن ریاضیات آکادمیک و شهود دنیای واقعی طراحی شده و بخشی از یک پورتفوی بزرگتر شامل Q-Learning، PPO، SAC و موارد دیگر است. اگر این تحلیل عمیق به شما در درک عدم قطعیت AI کمک کرد، میتوانید مخزن کامل پروژهها را در گیتهاب بررسی کنید: ⭐ Reinforcement Learning Portfolio on GitHub Dash10107 / rl-portfolio.



گفتگو