اگر در حال آموزش مدلهایی برای استخراج ساختاریافته هستید، احتمالاً با کابوس حلقههای تکرار بیپایان دستوپنجه نرم کردهاید. باید بدانید که این مشکل، برخلاف تصور رایج، یک خطای ساده در رمزگشایی نیست، بلکه یک شکست در سطح توزیع سیستم است.
به نقل از تحلیل فنی منتشر شده در ۳ ژوئن ۲۰۲۶، پروژه DharmaOCR توانست سقف محدودیتهای تنظیم دقیق نظارتی (Supervised Fine-Tuning یا SFT) را بشکند. این تیم با استفاده از بهینهسازی مستقیم ترجیحات (Direct Preference Optimization یا DPO) برای جریمه کردن شکستهای خودِ مدل، به کاهش میانگین ۵۹.۴ درصدی در زوال متنی (Text Degeneration) در پنج خانواده مدل مختلف دست یافت.
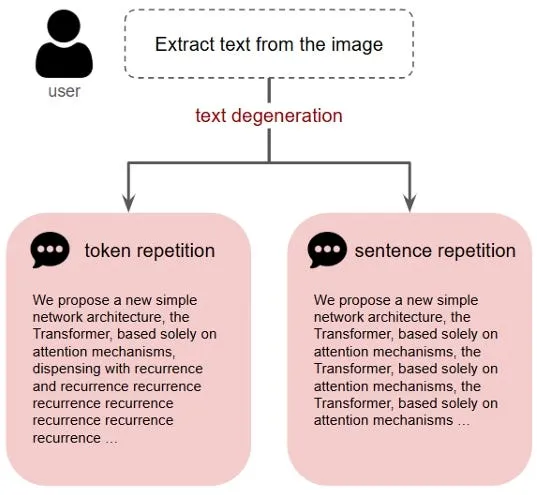
همانطور که در تحلیلهای قبلی ما دربارهی پایداری مدلهای زبانی اشاره کردیم، مدلها اغلب وارد یک ناحیه «جذبکننده» در توزیع احتمالی (Probability Distribution) میشوند که منجر به تکرار بینهایت یک توکن میشود. بر اساس مستندات پژوهشی Holtzman و همکاران (۲۰۲۰)، در این حالت رمزگشا صرفاً از توزیعی نمونهبرداری میکند که پیشتر در یک حلقه گرفتار شده است.
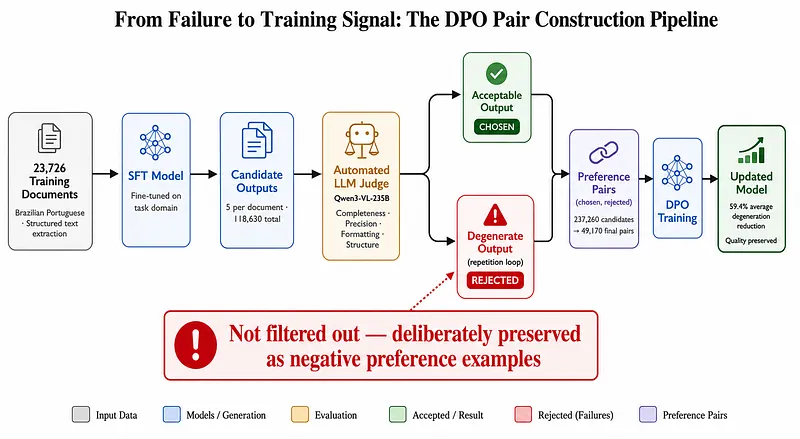
برای حل این معضل، خط لوله DharmaOCR یک رویکرد سهمرحلهای را روی ۲۳,۷۲۶ سند پیاده کرد. به جای حذف خروجیهای معیوب بهعنوان نویز، این تیم از آنها بهعنوان نمونههای «ردشده» در جفتهای ترجیحی DPO استفاده کرد. در این سازوکار، یک مدل زبانی بزرگ (LLM) بهعنوان داور، پاسخهای کاندید را امتیازدهی کرد؛ به گونهای که استخراج پاکیزه به عنوان خروجی «منتخب» و حلقه تکرار به عنوان خروجی «ردشده» جفت شدند.
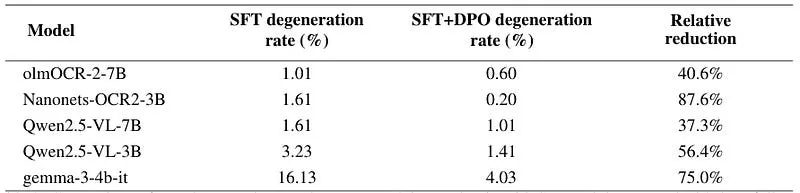
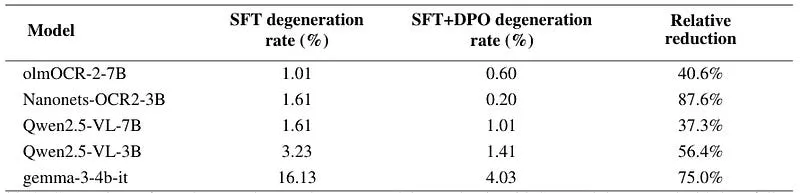
نتایج نشان میدهد که مقاومت در برابر زوال متنی و قابلیتهای وظیفهای به صورت مستقل حرکت میکنند. برای مثال، مدل Qwen2.5-VL-3B پس از SFT، نرخ زوال را از ۰.۶۰٪ به ۳.۲۳٪ افزایش داد؛ زیرا مدل آنقدر توانمند شده بود که وظیفه را شروع کند، اما سپس در جذبکننده خطا گرفتار شد. مرحله DPO این نرخ را دوباره به ۱.۴۱٪ کاهش داد. دراماتیکترین بهبود در Nanonets-OCR2-3B مشاهده شد که نرخ زوال در آن از ۱.۶۱٪ به ۰.۲۰٪ رسید (کاهش ۸۷.۶ درصدی).
این تحول نشان میدهد که در وظایف فنی و غیرگفتگویی، DPO را نباید صرفاً ابزاری برای همراستاسازی با ترجیحات انسانی دانست، بلکه باید آن را یک ابزار دقیق برای کاهش حالتهای شکست (Failure-mode mitigation) دید. با آموزش صریح مدل برای دور شدن از یک کلاس خاص از خطاها، مهندسان میتوانند قابلیت کلی مدل را از پایداری آن جداسازی (Decouple) کنند.
گام بعدی شما
- بررسی کنید که آیا شکستهای خط لوله شما «دستهبندیشده» (Categorical) هستند یا صرفاً کیفیت پایینی دارند.
- اگر یک حالت شکست تکرارپذیر و شناساییپذیر دارید، به جای گسترش دادههای SFT، از خطاهای خودِ مدل بهعنوان سیگنال ردشده در DPO استفاده کنید.
- نرخ زوال متنی را در مدلهای کوچکتر (SLMs) که برای وظایف تخصصی بهینه شدهاند، پایش کنید.
اما داستان سختافزاری این تحول و تأثیر حجم دادهها بر سرعت همگرایی DPO حتی پیچیدهتر است — به تحلیل ما دربارهی بهینهسازی حافظه در تراشههای جدید مراجعه کنید.



گفتگو