
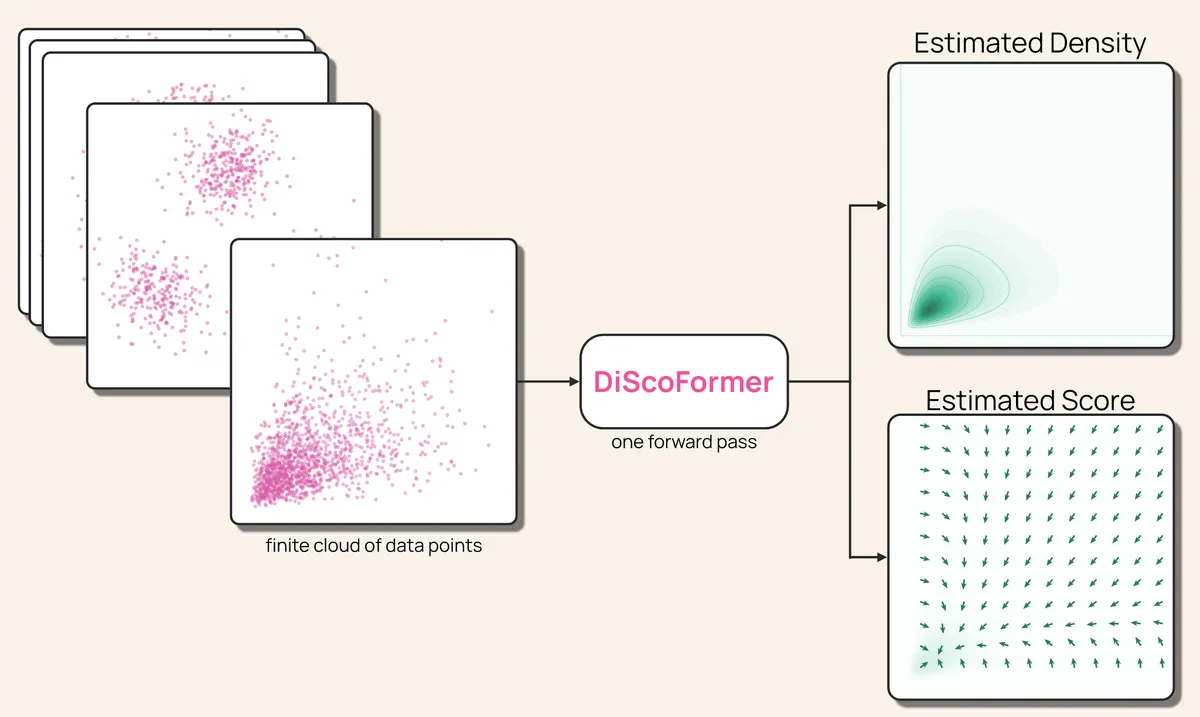
بسیاری از مهندسان یادماشین با یک بنبست تکراری روبرو هستند: یا باید از روشهای عمومی اما ناکارآمد در ابعاد بالا استفاده کنند یا مدلهایی بسازند که برای هر تغییر کوچک در دادهها، نیاز به آموزش مجدد داشته باشند. DiScoFormer (Density and Score Transformer) این معادله را تغییر میدهد و اجازه میدهد مقادیر بحرانی توزیع داده در یک گذر پیشرو (Forward Pass) برای هر مجموعه دادهای تخمین زده شود.
طبق گزارش فنی منتشر شده در ۲۹ ژوئن ۲۰۲۶، این معماری مشکل بازیابی چگالی و امتیاز (Score) توزیع داده را بدون نیاز به بازآموزیهای هزینهبر و وابسته به مسئله حل میکند. اساساً بسیاری از مسائل علوم پایه و هوش مصنوعی بر این پایه استوارند: بازیابی توزیع از مجموعهای از نقاط داده برای تشخیص اینکه کدام مقادیر رایج و کدام نادر هستند. برای مثال، اکثر مدلهای مولد هوش مصنوعی، از جمله Stable Diffusion و DALL-E، برای تبدیل نویز تصادفی به تصاویر واقعگرایانه، به «امتیاز» — که همان گرادیان لگاریتم چگالی است — وابسته هستند. این رویکرد به بهینهسازی بازسازی منیفولدها شباهت دارد، مشابه آنچه در مدل PTL-Diffusion برای جایگزینی توزیع گوسی با قوانین دورهای بررسی شده است. همین سازوکار امتیاز در نمونهبرداری بیزی و شبیهسازیهای ذرات که برای مدلسازی سیستمهای پیچیده مانند پلاسما به کار میروند، نقش پیشران دارد.
پیش از این، متخصصان دو انتخاب داشتند: تخمین چگالی هسته (KDE) که یک روش عمومی است اما در ابعاد بالا شکست میخورد، یا تطبیق امتیاز عصبی (Neural Score-matching) که در ابعاد بالا دقیق است اما برای هر توزیع جدید نیاز به یک چرخه کامل آموزش دارد. تصور کنید میخواهید در شهری مسیریابی کنید و یا نقشهای دارید که فقط برای یک خیابان کار میکند، یا GPSی دارید که هر بار از مرز شهر عبور میکنید، نیاز به بازنویسی کامل نرمافزار دارد؛ DiScoFormer در واقع یک GPS جهانی را فراهم میکند.

معماری فنی و سازوکار
این مدل از بلوکهای ترنسفورمر (Transformer) پشتهای و توجه متقابل (Cross-attention) برای نگاشت یک نمونه کامل به توزیع زیربنایی آن استفاده میکند. مکانیسم توجه متقابل در اینجا حیاتی است؛ زیرا به مدل اجازه میدهد چگالی و امتیاز را در هر نقطهای ارزیابی کند، نه فقط در مکانهایی که دادهها در آنجا حضور دارند. این طراحی شامل یک ستون فقرات (Backbone) مشترک با دو سر (Head) خروجی تخصصی است:
- سر چگالی (Density Head): نسخهای نرم از یک هیستوگرام را تخمین میزند و شناسایی میکند که نقاط داده در کجا خوشهبندی شدهاند (چگالی بالا) و در کجا کمیاب هستند (چگالی پایین).
- سر امتیاز (Score Head): جهت سریعترین افزایش چگالی را پیشبینی میکند. حرکت دادن یک نقطه در راستای این امتیاز، آن را به سمت منطقهای با احتمال وقوع بیشتر هدایت میکند.
به نقل از مستندات پژوهش، از آنجا که امتیاز از نظر ریاضی همان گرادیان لگاریتم چگالی است، مدل از یک تابع زیان سازگاری بدون برچسب (Label-free consistency loss) استفاده میکند تا هر دو سر خروجی با یکدیگر همراستا شوند. این جفتشدگی فراتر از صرفهجویی در پارامترهاست؛ سر امتیاز باید در هر پرسوجو (Query)، با گرادیان سرِ لوگ-چگالی مطابقت داشته باشد. در مرحله استنتاج (Inference)، مدل میتواند با ثابت نگه داشتن زمینه (Context) و اجرای چند گام گرادیانی روی این تابع زیان سازگاری، خود را با ورودیهای خارج از توزیع (Out-of-distribution) تطبیق دهد، بدون اینکه به هیچ دادهی مرجع یا Ground-truth نیاز داشته باشد.
بستر ریاضی
دلیل خاص ریاضی برای اینکه چرا معماری ترنسفورمر برای این تکلیف مناسب است، در تفاوت آن با روشهای کلاسیک نهفته است. روش KDE کلاسیک بر پایه یک «پهنای باند» (Bandwidth) واحد عمل میکند؛ یعنی یک مقدار ثابت که تعیین میکند اثر هر نقطه تا چه فاصلهای گسترش یابد و این مقدار به طور یکسان در همه جا اعمال میشود.
مکانیزم توجه (Attention) به عنوان یک تعمیم سختگیرانه از این مفهوم عمل میکند. پژوهشگران به صورت تحلیلی نشان دادند که وزنهای یک سرِ توجه منفرد، تقریباً معادل یک هسته گاوسی روی دادهها هستند. در نتیجه، یک بلوک توجه متقابل میتواند چگالی و امتیاز KDE را بازتولید کند، اما DiScoFormer فراتر میرود و چندین مقیاس از این دست را به طور همزمان یاد میگیرد و آنها را با دادههای خاص ارائهشده تطبیق میدهد.
بنچمارکها و عملکرد
برای آموزش این مدل، پژوهشگران به دو دلیل از مدلهای مخلوط گاوسی (GMMs) استفاده کردند: اول اینکه آنها تقریبزنندههای جهانی چگالی هستند و میتوانند هر توزیع نرمی را با خطای بسیار کوچک شبیهسازی کنند، و دوم اینکه چگالیها و امتیازهای فرمبسته (Closed-form) را برای نظارت دقیق فراهم میکنند. با استخراج یک GMM جدید برای هر دسته (Batch)، مدل با نمونههای تقریباً نامحدودی از توزیعهای هدف مواجه شد.
نتایج نشان میدهد که DiScoFormer در تمام شاخصها KDE را شکست میدهد و این فاصله در ابعاد بالا بیشتر میشود. در آزمونهای ۱۰۰-بعدی، این مدل خطای امتیاز را تقریباً ۶.۵ برابر و خطای چگالی را بیش از ۳۷ برابر نسبت به بهترین KDE تنظیمشده دستی (Hand-tuned) کاهش داد. در حالی که KDE در این مقیاسها اغلب با کمبود حافظه (Out of memory) مواجه میشود، دقت DiScoFormer با افزودن نمونههای بیشتر بهبود مییابد.
این مدل همچنین تعمیمپذیری قدرتمندی از خود نشان داده است و بر روی مخلوطهایی با تعداد مودهای (Modes) بیشتر از آنچه در طول آموزش دیده بود، و همچنین بر روی اشکال غیرگاوسی مانند توزیعهای لاپلاس (Laplace) و t-Student، دقیق باقی میماند.
پیامدهای حوزه فنی
این دستاورد برای جامعه فنی، این فرض را که تخمین توزیع در ابعاد بالا نیازمند یک مدل اختصاصی (Bespoke) برای هر مسئله است، تغییر میدهد. با تبدیل KDE به یک حالت خاص، DiScoFormer یک ابزار آماری کلاسیک را به یک معماری عصبی مقیاسپذیر تبدیل کرده است.
این رویکرد، یک تخمینگر «پلاگین» ایجاد میکند که میتواند هزینههای محاسباتی استنتاج بیزی، شبیهسازی ذرات در فیزیک پلاسما و مدلسازی مولد را بهشدت کاهش دهد. این پیشرفت در مدلسازی دینامیکها، مکمل پژوهشهای اخیر در زمینه اتوماتای ذرات عصبی برای عبور از شبکههای شبکهای به سمت محیطهای سیال است که بر یادگیری خودسازمانده استوار است. مدلی که پیشآموزش دیده و نیاز به بازآموزی برای هر مسئله را حذف میکند، در هر جایی که مفاهیم چگالی و امتیاز ظاهر شوند، قابل استفاده مجدد است.
پژوهشگران و متخصصان باید اکنون گزارش فنی را در arxiv.org/abs/2511.05924 بررسی کنند تا تعیین نمایند آیا جایگزینی خطلولههای (Pipelines) فعلی تطبیق امتیاز خود با یک DiScoFormer پیشآموزشدیده، میتواند چرخههای تکرار (Iteration cycles) خاص آنها را کاهش دهد یا خیر.
گام بعدی شما
- پژوهشگران و توسعهدهندگان باید گزارش فنی را در arxiv.org/abs/2511.05924 بررسی کنند تا امکان جایگزینی خطلولههای تطبیق امتیاز فعلی خود با DiScoFormer را بسنجند.
- تحلیل کنید که آیا حذف چرخه بازآموزی در پروژههای شبیهسازی شما میتواند سرعت تکرار (Iteration) را افزایش دهد یا خیر.
اما تأثیر این رویکرد بر بهینهسازی حافظه در مدلهای مولد حتی عمیقتر است — به تحلیل ما دربارهی مدیریت KV Cache در مدلهای بزرگ مراجعه کنید.



گفتگو