
اگر توسعهدهندهای هستید که بودجه محدودی دارد اما میخواهد از اتوماسیون هوش مصنوعی استفاده کند، احتمالاً صورتحسابهای API بزرگترین مانع شماست. در ۹ ژوئن ۲۰۲۶، یک توسعهدهنده چارچوب دقیقی را معرفی کرد که در آن هزینهها با تقسیم کار بین یک «برنامهریز استراتژیک» در ابر و یک «مجری متمرکز» در سیستم محلی به حداقل میرسد.
این روش در زمانی ارائه میشود که برنامهنویسان برای مهاجرتهای گسترده کد و تستها، بهشدت به مدلهای زبانی بزرگ (LLM) وابسته شدهاند. برای بسیاری از آنها، هزینه ارسال هزاران توکن به یک ارائهدهنده ابری برای انجام کارهای تکراری کدنویسی دیگر پایدار و بهصرفه نیست. راهکار این است که مدل ابری را بهجای «کارگر»، به عنوان «مدیر» به کار بگیریم تا استدلالهای سطح بالا حفظ شود، اما برای هر خط کد تکراری (Boilerplate) هزینه نکنیم.
طبق گزارش وبسایت dev.to، این سیستم از یک مدل تفویض سلسلهمراتبی سختگیرانه استفاده میکند. در این ساختار، مدل Gemini نقش برنامهریز استراتژیک را بر عهده دارد و مدیریت زمینه، تصمیمگیری و سازماندهی را انجام میدهد. وقتی تسکی نیاز به پردازش سنگین یا حجم زیاد کدنویسی دارد، Gemini بهجای اینکه خودش کد را بنویسد، ابزاری خاص به نام query_local_model را فعال میکند تا کار را به یک نمونه محلی از مدل Gemma بسپارد که از طریق oMLX روی یک دستگاه مک اجرا میشود.
سازوکار فنی
- سرور MCP: سیستم از یک سرور پروتکل ارتباط مدل (Model Communication Protocol) به عنوان لایه میانی یا Middleware استفاده میکند. این سرور درخواستها را از مدل ابری (Gemini) دریافت کرده و آنها را به نمونه مدل محلی هدایت میکند.
- دروازه عدم تحمل: برنامهریز ابری بهشدت منع شده است که اگر مدل محلی در دسترس است، از دستوراتی مثل
write_fileیاreplaceبرای پیادهسازی منطق، نوشتن تستها، انجام بازسازی کد (Refactoring)، تشخیص و رفع خطاهای دیباگ، یا پیشنویس مستندات استفاده کند. - توالی اجباری: گردش کار باید دقیقاً این مسیر را طی کند: جمعآوری زمینه (تحقیق) $\rightarrow$ فراخوانی
omlx/query_local_modelبا یک پرامپت جامع و محدودیتهای مشخص $\rightarrow$ بررسی و ترکیب خروجی $\rightarrow$ اعمال تغییرات در فایلهایsrc/یاtest/. - منطق تفویض: در این معماری، برنامهریز تعیین میکند «چه کاری» باید انجام شود، در حالی که مجری محلی تعیین میکند آن کار «چگونه» به سرانجام برسد.

زمینه پروژه: gas-fakes
این ساختار در پروژه gas-fakes به کار گرفته شده است؛ یک پروژه شبیهسازی که هدف آن آزاد کردن کدهای Apps Script است تا امکان اجرای محلی، کانتینریسازی و یکپارچهسازی مداوم (CI) کدهای بومی Apps Script فراهم شود. در ابتدا، توسعهدهنده بهطور آگاهانه از کدهای تولیدشده توسط هوش مصنوعی و تستهای خودکار AI دوری میکرد؛ به این معنا که بخش اعظم مخزن کد توسط انسانها نوشته و تست شده بود.
اکنون که معماری و تکنیکهای پروژه کاملاً به بلوغ رسیدهاند، کارهای باقیمانده عمدتاً شامل «کارهای خستهکننده» یا همان پیادهسازی و تست متدهای باقیمانده و کمتر استفادهشده از پلتفرم Apps Script است. بر اساس مستندات پروژه، در نسخه ۲.۵.۳، این سیستم توانسته ۴۳۹۹ متد از مجموع ۶۷۰۸ متد و ۱۰۵۰۰ تست تطبیقی (Parity Tests) را در شبیهسازی نسبت به پلتفرم زنده Apps Script پیاده کند.
کیفیت و ارزیابی
پیش از ادغام مدل محلی برای کارهای روتین و سخت، یک ارزیابی توسط Gemini نمره کلی ۹۴ از ۱۰۰ را به این پروژه داد و آن را در سطح «ابزار توسعه درجه سازمانی / تولیدی» (Enterprise Grade / Production Dev Tool) طبقهبندی کرد. جزئیات این ارزیابی به شرح زیر است:
- طراحی معماری و قابلیت اجرا (A+): به دلیل طراحی همزمان (Synchronous) استثنایی که V8 GAS را روی بستر async نود جیاس شبیهسازی میکند، مورد تقدیر قرار گرفت.
- ردیابی تطبیق و کامل بودن (A): استفاده از یک سیستم ردیابی دادهمحور که هزاران متد را از طریق مسیر
/progressنقشهبرداری میکند. - تست، تضمین کیفیت و دقت (A): یک ردپای گسترده شامل بیش از ۱۰,۰۰۰ پاس تایید داخلی و چرخهای که تطبیق رفتاری ۱:۱ را اثبات میکند.
- مدیریت موارد خاص/لبه (A-): شفافیت کامل در مورد محدودیتهای پلتفرم، رفتارهای عجیب اجرای اسکریپت و تغییرات مدرن در احراز هویت (Auth Drift).
- آمادگی اکوسیستم (A+): یکپارچگی کامل با سرور MCP، ابزار اتوماسیون
gf_agentو قابلیت کانتینریسازی.
جزئیات پیادهسازی
از نظر مالی، این یعنی گرانترین توکنها فقط صرف معماری سطح بالا و بازبینی نهایی میشوند. «کارهای سخت و روتین» بهصورت رایگان توسط سختافزار محلی انجام میگیرد. این تغییر، مدل هزینه را از یک مبلغ خطی بهازای هر توکن، به یک سرمایهگذاری ثابت روی سختافزار تبدیل میکند.
برای راهاندازی این سیستم روی مک، توسعهدهنده از oMLX برای سرویسدهی مدل محلی استفاده میکند. اگرچه سازماندهندههای (Orchestrators) دیگری برای کاربران غیر مک وجود دارد، اما این راهنمای خاص بر ترکیب Mac/AntiGravity تمرکز دارد. همکاران پروژه gas-fakes این ساختار را در فورکهای خود دارند، اما باید تنظیمات .gemini/settings را برای اشاره به مسیر محلی ابزارهای MCP در سیستم خود تغییر دهند.
برای تایید اینکه سیستم بهدرستی عمل میکند، کاربران میتوانند اقدامات زیر را انجام دهند:
- از CLI ابزار
agyبپرسند: «آیا میتوانی از مدل محلی استفاده کنی؟» - پیامهای سرور مانند
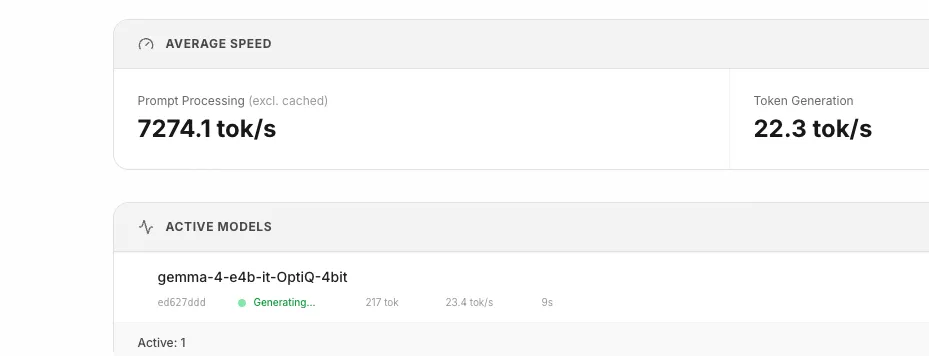
omlx/query_local_model(Delegate documentation generation to local model)را رصد کنند. - داشبورد oMLX را در آدرس
http://127.0.0.1:8000/admin/dashboardبرای مشاهده وضعیت «در حال تولید» (generating) در مقابل مدل Gemma چک کنند.
این تغییر رویکرد نشان میدهد که آینده مهندسی با کمک هوش مصنوعی، نه در یافتن یک مدل «کامل» و واحد، بلکه در ساخت لایههای مسیریابی (Routing Layers) کارآمد است. با تبدیل مدلهای محلی به کارگران متخصص و مدلهای ابری به سازماندهندهها، تیمها میتوانند اتوماسیون خود را بدون افزایش خطی بودجه، گسترش دهند.



گفتگو