
تصور کنید مدل هوش مصنوعی شما در محیط عملیاتی فعال است، اما کاربران پاسخهای خالی دریافت میکنند و سیستم همچنان وضعیت را «سالم» نشان میدهد. این شکاف میان «اجرای مدل» و «مدیریت عملیاتی»، دقیقاً همان نقطهای است که GPUStack v2.2 برای حل آن طراحی شده است. تغییر در استقرار هوش مصنوعی اکنون به این معناست که لانچ کردن یک مدل دیگر خط پایان نیست، بلکه نقطه شروع است. طبق گزارش وبسایت dev.to، این پلتفرم که در ۳۰ ژوئن ۲۰۲۶ عرضه شد، از یک ابزار ساده برای سرویسدهی مدلها به یک زیرساخت جامع برای ارائه خدمات هوش مصنوعی در سطح سازمانی تبدیل شده است.
همانطور که برنامههای مبتنی بر مدلهای زبانی بزرگ به سمت تولید در مقیاس بالا حرکت میکنند، زیرساختهای هوش مصنوعی وارد مرحله اجتنابناپذیر بلوغ میشوند. این تغییر صرفاً افزودن ویژگیهای جدید نیست، بلکه بازتابی از حرکت به سمت ایجاد قابلیت دید (Visibility) و قابلیت اطمینان در سطح عملیاتی است. چالش اصلی در پیشبرد موازی دو حوزه نهفته است: سرویسدهی مدل باید قابل اعتماد شود و در عین حال، مدیریت محاسبات باید از سرویسدهی ساده استنتاج به تخصیص یکپارچه تمامی منابع متنوع مورد نیاز هوش مصنوعی گسترش یابد. این ضرورت تکامل زیرساخت، بهویژه زمانیکه تکیه بر تنها یک مدل به یک ریسک تجاری تبدیل میشود، اهمیت مییابد؛ موضوعی که در تحلیل ما درباره نقش لایهی مسیریابی در ایجاد مزیت رقابتی هوش مصنوعی مورد بررسی قرار گرفته است.
بسیاری از تیمهای فنی زمانی که یک مدل وارد مرحله تولید در مقیاس بزرگ میشود، دچار مشکل میشوند. انتقال از یک استارتاپ موفق به یک سرویس پایدار، جایی است که خطاهای OOM (کمبود حافظه)، درخواستهای استنتاج معلق (Hanging) و کرشهای خاموش پردازش معمولاً رخ میدهند. تصور کنید در یک محیط تولیدی، یک نمونه معیوب همچنان ترافیک دریافت میکند زیرا سیستم فکر میکند سالم است، اما کاربران پاسخهای خالی دریافت میکنند. هدف نسخه ۲.۲ پل زدن میان این فاصله است.
عملیاتیسازی چرخه حیات مدل
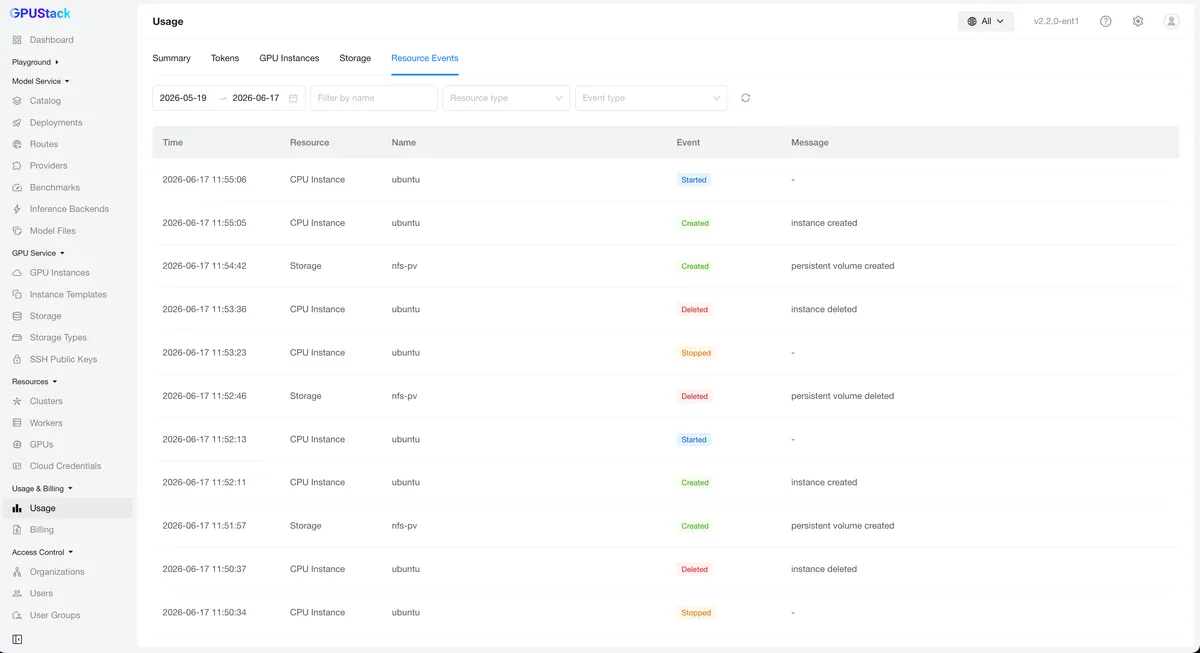
در نسخههای پیشین GPUStack، بررسیهای سلامت (Health Checks) عمدتاً بر مرحله راهاندازی متمرکز بود. وقتی یک نمونه با موفقیت استارت میخورد، پلتفرم راهی برای شناسایی مشکلاتی که بعداً رخ میدادند نداشت. نمونههای معیوب میتوانستند در استخر سرویس باقی بمانند و به دریافت ترافیک ادامه دهند، که منجر به شکستهای خاموشی میشد که تنها پس از بازرسی دستی یا گزارش کاربران شناسایی میشدند.
به نقل از مستندات رسمی این پروژه، نسخه ۲.۲ پایش سلامت را به کل چرخه حیات زمان اجرا (Runtime Lifecycle) گسترش داده است. سیستم اکنون قابلیت استنتاج (Inference) — یعنی همان لحظهی تولید جواب توسط مدل، شبیه به خودِ آشپزی (نه آموزش آشپز) — را بهطور مداوم رصد میکند. اگر یک نمونه غیرعادی شناسایی شود، سیستم فوراً آن را از استخر سرویس حذف کرده و بهطور خودکار ریاستارت میکند. پس از بازیابی، نمونه مجدداً به استخر اضافه میشود تا در دسترس بودن سرویس بهطور پیشدستانه حفظ شود.
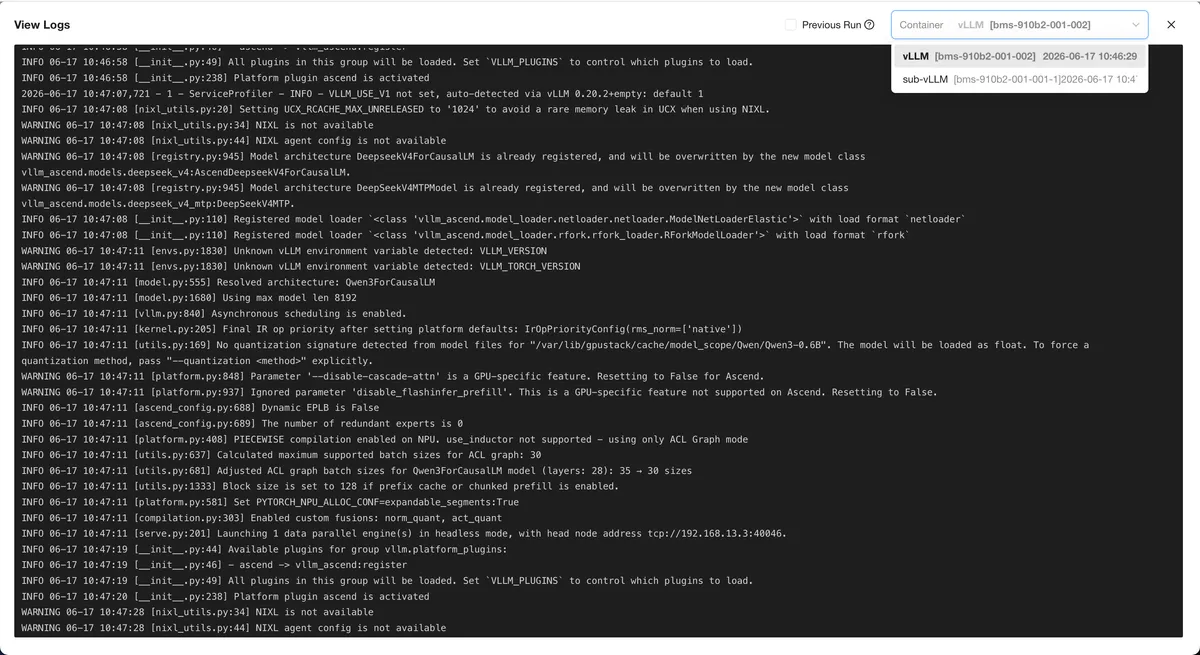
عیبیابی نیز از محیط ترمینال به رابط کاربری (UI) منتقل شده است تا اطمینان حاصل شود که تیمها سوابق کاملی از شکستها دارند. توسعهدهندگان اکنون به سه نوع لاگ حیاتی دسترسی دارند:
- لاگهای تاریخی پیش از ریاستارت: این قابلیت به شما اجازه میدهد خروجی کامل را قبل از کرش کردن نمونه مشاهده کنید و مطمئن شوید لاگهای خطا پس از ریاستارت پاک نمیشوند.
- لاگهای توزیعشده زیر-نمونهها (Sub-instance): امکان بررسی خروجی هر گره بهصورت مجزا در استقرارهای چند-گرهای را فراهم میکند تا نقطه شکست سریعاً شناسایی شود.
- لاگهای کانتینر Ray: مشاهده مستقیم لاگهای کانتینرهای Ray در محیط UI، بدون نیاز به اجرای دستورات دستی عیبیابی در ترمینال.
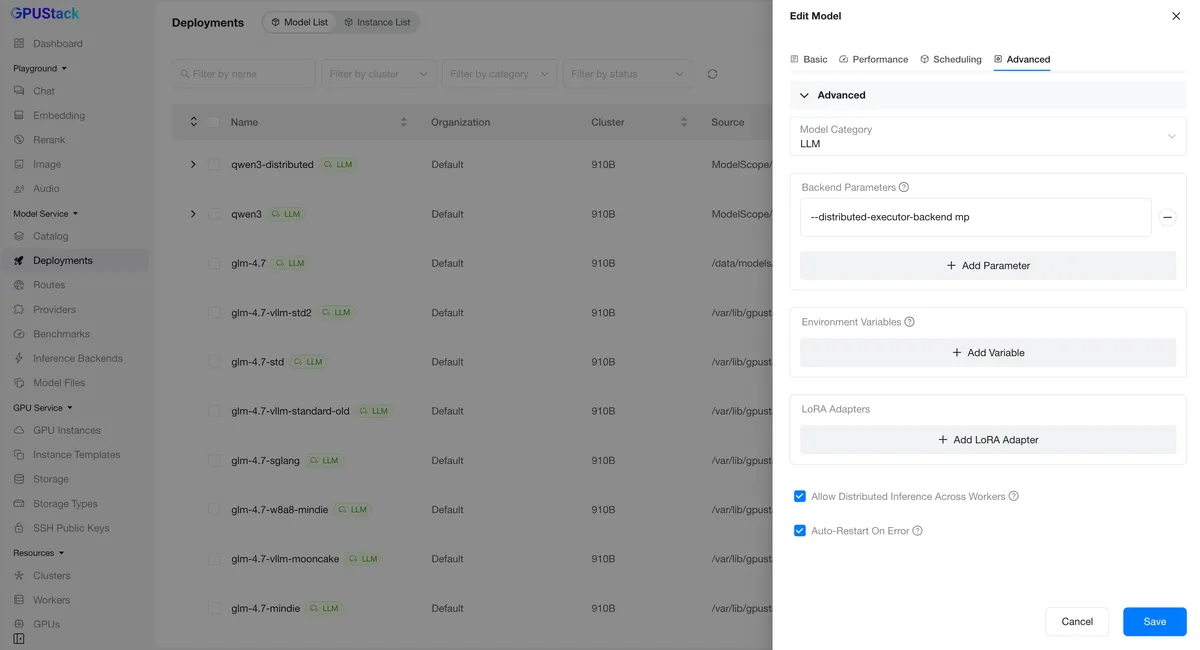
برای کسانی که استنتاج توزیعشده را مقیاس میکنند، حالت vLLM MP auto-distributed معرفی شده است. پیش از این، GPUStack تنها از استقرارهای توزیعشده vLLM مبتنی بر Ray پشتیبانی میکرد و استقرارهای مبتنی بر MP باید بهصورت دستی پیکربندی میشدند، زیرا پلتفرم نمیتوانست تمام نمونههای توزیعشده را بهطور خودکار فعال کند. با تکامل سریع vLLM، حالت جدید مبتنی بر MP مزایای واضحی نسبت به استقرارهای Ray از نظر سربار عملیاتی و عملکرد استنتاج دارد. کاربران اکنون میتوانند استراتژی توزیع اتوماتیک vLLM را که با نیازهای خاص آنها در مورد تأخیر (Latency) و توان عملیاتی (Throughput) سازگار است، انتخاب کنند.
هدررفت منابع نیز هدف بعدی این بهروزرسانی است. در محیطهای سازمانی، تنظیم دقیق (Fine-tuning) — که مثل وقتی است به یک پزشک عمومی تخصص پوست میدهیم تا روی یک حوزه دقیق شود — برای سناریوهای مختلف تجاری یک استاندارد است. پیشتر، هر آداپتور (Adapter) لورا (LoRA) باید بهعنوان یک نمونه مدل مجزا اجرا میشد که باعث میشد سربار حافظه GPU بهصورت خطی با تعداد وظایف افزایش یابد. اما پشتیبانی از Multi-LoRA در نسخه ۲.۲ اجازه میدهد چندین آداپتور لورا روی یک مدل پایه سوار شوند و بهصورت پویا جابهجا شوند. این امر اجازه میدهد سختافزار یکسان، وظایف تنظیمشده بیشتری را پشتیبانی کند و بهرهوری حافظه GPU بهطور قابلتوجهی بهبود یابد.
حاکمیت توکن و تخصیص هزینهها
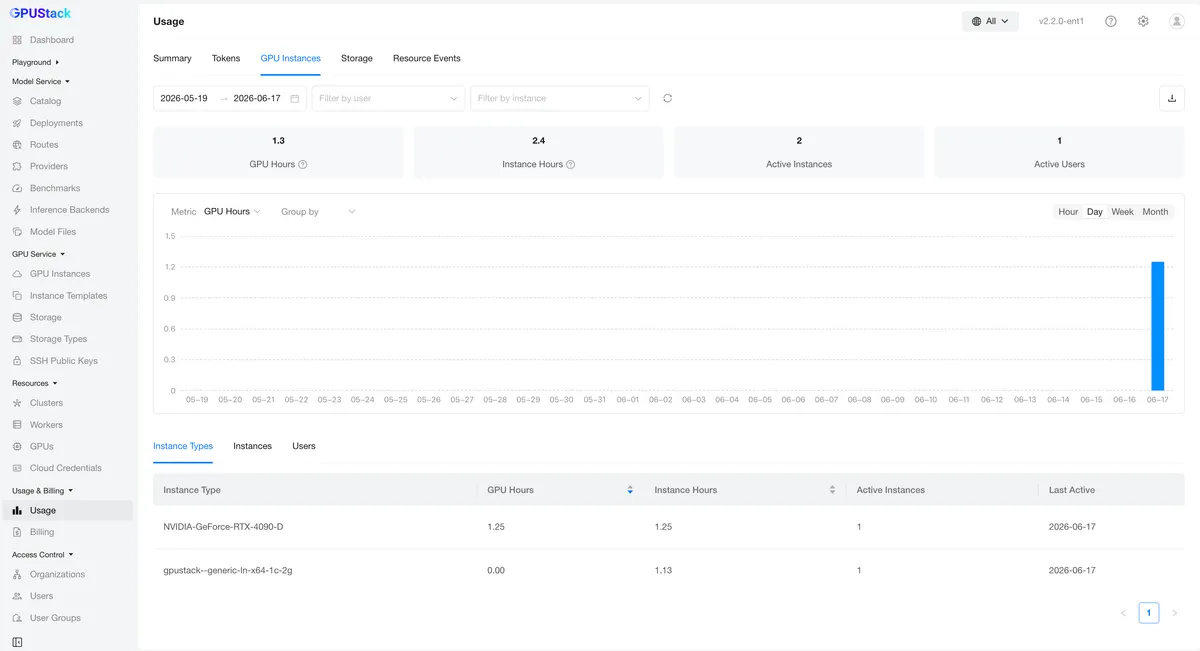
وقتی چندین تیم و برنامه از یک پلتفرم مشترک استفاده میکنند، مصرف توکن اغلب به یک «جعبه سیاه» تبدیل میشود. GPUStack پیشتر آمارهای مصرف را بر اساس مدل و کاربر ردیابی میکرد که به تیمها کمک میکرد روندهای کلی را درک کنند. با این حال، این دو بُعد برای تخصیص دقیق هزینهها کافی نبودند. وقتی خطوط مختلف کسبوکار چندین کلید API را تحت یک حساب کاربری مشترک به اشتراک میگذارند، مصرف را نمیتوان بهوضوح تفکیک کرد و حسابداری دقیق هزینهها دشوار میشود.
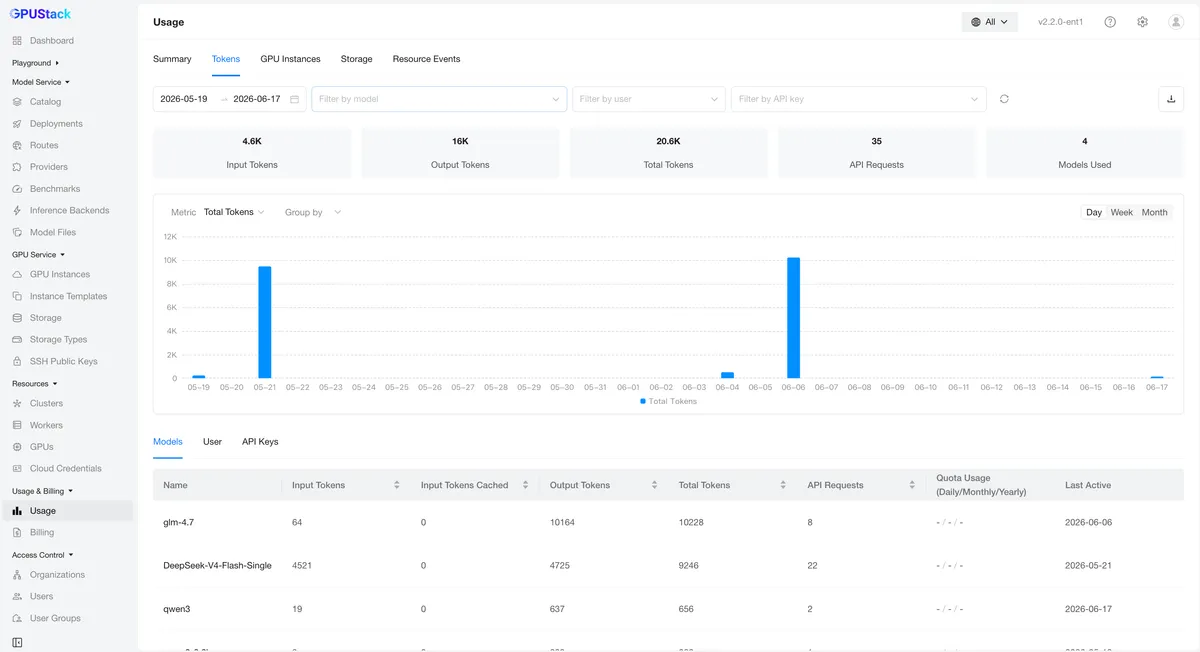
نسخه ۲.۲ این مشکل را با پیادهسازی آمار مصرف در سطح API Key حل کرد. مصرف توکن برای هر کلید بهصورت مستقل اندازهگیری میشود. این قابلیت به مدیران اجازه میدهد دقیقاً ببینند کدام فراخوان، چه مقدار و چه چیزی مصرف میکند و یک مبنای واقعی برای تخصیص هزینهها بین تیمها و مدیریت سهمیهها (Quota) فراهم میکند.
برای کاهش بار عملیاتی مدیران، نسخه ۲.۲ استعلامات شخصی مصرف را بهصورت سلفسرویس معرفی کرده است. کاربرانی که پیشتر مجبور بودند برای دریافت دادهها از مدیران درخواست دهند، اکنون میتوانند تاریخچه مصرف خود را بر اساس مدل و بازه زمانی مستقیماً در رابط کاربری مشاهده کنند. با استقرار این قابلیتهای اندازهگیری، مصرف توکن به دادههای عملیاتی تبدیل میشود که از بازپرداختهای داخلی (Chargebacks) و تحلیلهای دقیق هزینه پشتیبانی میکند.
مقاومسازی استقرار سازمانی
قابلیتهای پلتفرم تنها زمانی محقق میشوند که توسط یک تجربه استقرار مستحکم پشتیبانی شوند. در نسخه ۲.۲، GPUStack شکافهای کلیدی در استقرار تولیدی سازمانی را در سه حوزه خاص برطرف کرده است:
- یکپارچگی با Kubernetes: از آنجایی که K8s انتخابی رایج برای زیرساختهای سازمانی است، نسخه ۲.۲ اکنون Helm Chart رسمی را ارائه میدهد. این امر نصب و پیکربندی را از طریق Helm در یک فرآیند تکمرحلهای ساده میکند و اجازه میدهد GPUStack مستقیماً در گردشکارهای GitOps و سیستمهای CI/CD قرار گیرد.
- سازگاری با پایگاهداده: پلتفرم پشتیبانی از پایگاهدادههای خود را گسترش داده تا OceanBase و openGauss را نیز شامل شود و به تیمها انعطاف بیشتری در محیطهای استقرار سازمانیشان بدهد.
- توپولوژی شبکه: نسخه ۲.۲ اکنون از حالت دسترسی یکطرفه Worker-to-Server پشتیبانی میکند. در سناریوهای بین-منطقهای یا مرزهای شبکه، برقراری اتصال دوطرفه اغلب دشوار است. با شبکه یکطرفه، گرههای Worker فقط نیاز به دسترسی به سرور دارند و سرور نیازی به ایجاد اتصالات معکوس ندارد، که این امر مانع بزرگی را برای مدیریت خوشههای چند-منطقهای برطرف میکند.
از تجمع محاسباتی به سرویس GPU
زمانبندی یکپارچه منابع محاسباتی ناهمگون — یعنی آوردن GPUهای برندها و مشخصات مختلف در یک استخر واحد — همواره نقطه قوت اصلی این پلتفرم بوده است. با این حال، آن استخر در درجه اول برای استنتاج استفاده میشد. دانشمندان داده اغلب به محیطهای توسعه تعاملی نیاز دارند و مهندسان الگوریتم ممکن است برای دیباگ و آزمایش به GPUهای اختصاصی نیاز داشته باشند. پیش از این، این نیازها از طریق سیستمهای مجزا مدیریت میشدند و منجر به تخصیص پراکنده منابع میگشتند. این چالشها در واقع بخشی از همان گلوگاههای سختافزاری هستند که مقیاسبندی تولید هوش مصنوعی را در بسیاری از سازمانها با دشواری مواجه کردهاند.
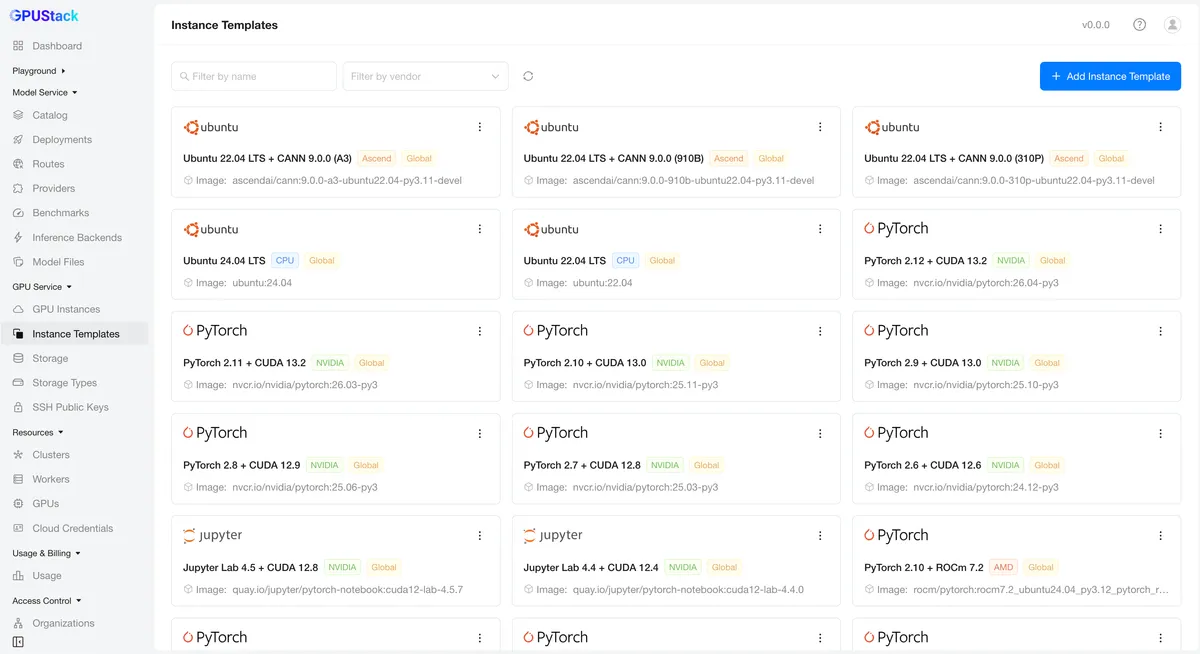
سرویس GPU Instance در نسخه ۲.۲، فرآیند تخصیص محیطهای ایزوله گرافیکی را زیر مدیریت یکپارچه پلتفرم میآورد. کاربران اکنون میتوانند نمونههای ایزوله GPU را بهصورت درخواستی با قابلیتهای زیر درخواست دهند:
- تعیین برند GPU، مدل و تعداد.
- انتخاب قالبهای زمان اجرا (Runtime Templates) که شامل نقاط اتصال ذخیرهسازی (Storage Mounts) و پیکربندی پورتها است.
- دسترسی به نمونه از طریق SSH یا محیط وب.
از آنجایی که مصرف بهصورت متمرکز اندازهگیری میشود و از همان سیستم زمانبندی سرویسهای استنتاج استفاده میکند، مدیریت دیگر پراکنده نخواهد بود. این یک تغییر بنیادین است که در آن یک استخر محاسباتی واحد، هم بهعنوان موتور استنتاج و هم بهعنوان ارائهدهنده نمونههای GPU درخواستی عمل میکند. این پایه، قابلیتهای آینده مانند زمانبندی منابع برای آموزش و تنظیم دقیق (Fine-tuning) و تقسیمبندی مجازیتر محاسبات را ممکن میسازد.
این تحول، شیوه مدیریت زیرساخت AI را تغییر میدهد. شرکتها بهجای مدیریت ناوگانی از سرورهای استنتاج، اکنون میتوانند یک استخر محاسباتی یکپارچه را مدیریت کنند که بهعنوان یک سرویس انعطافپذیر عمل کرده و سختافزار خام را به یک ابزار شفاف تبدیل میکند.
با ایجاد این بنیاد متنباز، نسخه تجاری (GPUStack v2.2 Enterprise Edition) که در راه است، بر حاکمیت در سطح سازمان و عملیات تجاری تمرکز خواهد کرد. این نسخه برای محیطهای پیچیدهای طراحی شده است که به ایزولاسیون چند-مستأجری، محدودیتهای دقیق سهمیه و نرخ (Rate Limiting)، کنترل دسترسی و قابلیت دسترسی بالا (High Availability) در سطح تولید نیاز دارند. نسخه تجاری بهطور خاص به چالشهای مدیریت مصرف محاسبات تا سطح هر API Key و مسیر مدل، بصریسازی توپولوژی منابع و مدیریت کامل صورتحساب توکن و GPU خواهد پرداخت.
برای بررسی این بهبودهای عملیاتی، میتوانید مستندات رسمی را مطالعه کنید یا استقرار خود را از طریق مخزن گیتهاب آنها آغاز نمایید.
شروع به کار:
- گیتهاب: https://github.com/gpustack/gpustack
- مستندات: https://docs.gpustack.ai
- تماس: https://gpustack.ai/contact/
گام بعدی شما
- اگر از vLLM برای استقرار مدل استفاده میکنید، حالت MP auto-distributed را برای کاهش سربار عملیاتی آزمایش کنید.
- برای بهینهسازی VRAM، مدلهای تخصصی خود را از طریق Multi-LoRA روی یک مدل پایه مستقر کنید.
- برای کنترل هزینهها، سیستم پرداخت داخلی خود را با API Key metering متصل کنید.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو