
اگر قصد دارید یک مدل ۷۰ میلیارد پارامتری را روی یک GPU واحد اجرا کنید، بزرگترین دشمن شما پهنای باند حافظه و توان مصرفی است. طبق گزارش منتشر شده در ۱۸ ژوئن ۲۰۲۶ در وبسایت hello-fri-end.github.io، تغییر دقت از ۱۶-بیت به کوانتایزیشن (Quantization) ۴-بیت اعداد صحیح، فضای اشغالشده در حافظه را ۴ برابر کاهش میدهد.
این تغییر حیاتی است چون عملیات اعداد اعشاری انرژی بسیار زیادی مصرف میکنند. مدل زبانی بزرگ (LLM) — مثل کتابخانهداری که میلیاردها صفحه را خوانده و حالا با همان لحن کتابها جواب میدهد — برای تولید هر توکن نیاز به محاسبات عظیمی دارد. همانطور که در تحلیلهای پیشین ما دربارهی بهینهسازی سختافزار مدلها اشاره کردیم، گلوگاه اصلی همیشه انتقال داده است. بر اساس پژوهش مارک هوروویتز از دانشگاه استنفورد، یک عملیات جمع با دقت int8 تا ۳۰ برابر کمتر از fp32 انرژی میبرد و ضرب اعداد صحیح ۱۸ برابر بهینهتر است.

این بهرهوری در سطح سختافزار درون واحدهای ضرب-تجمعی (MAC) رخ میدهد. این واحدها ضرب ماتریسی را با بارگذاری وزنهای کوانتیده انجام داده و نتیجه را در ثبتهای int32 با دقت بالا جمع میکنند.
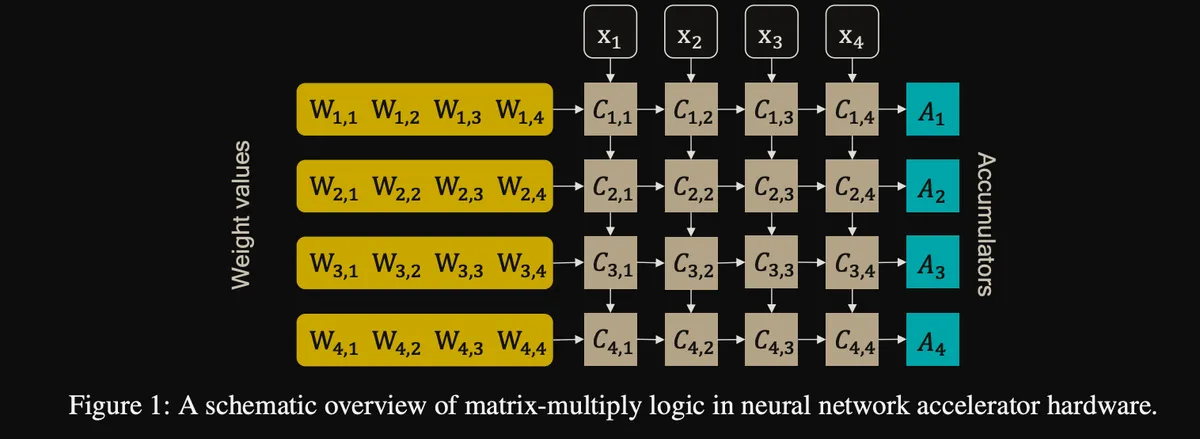
برای کاهش افت دقت، مهندسان از روشهای زیر استفاده میکنند:
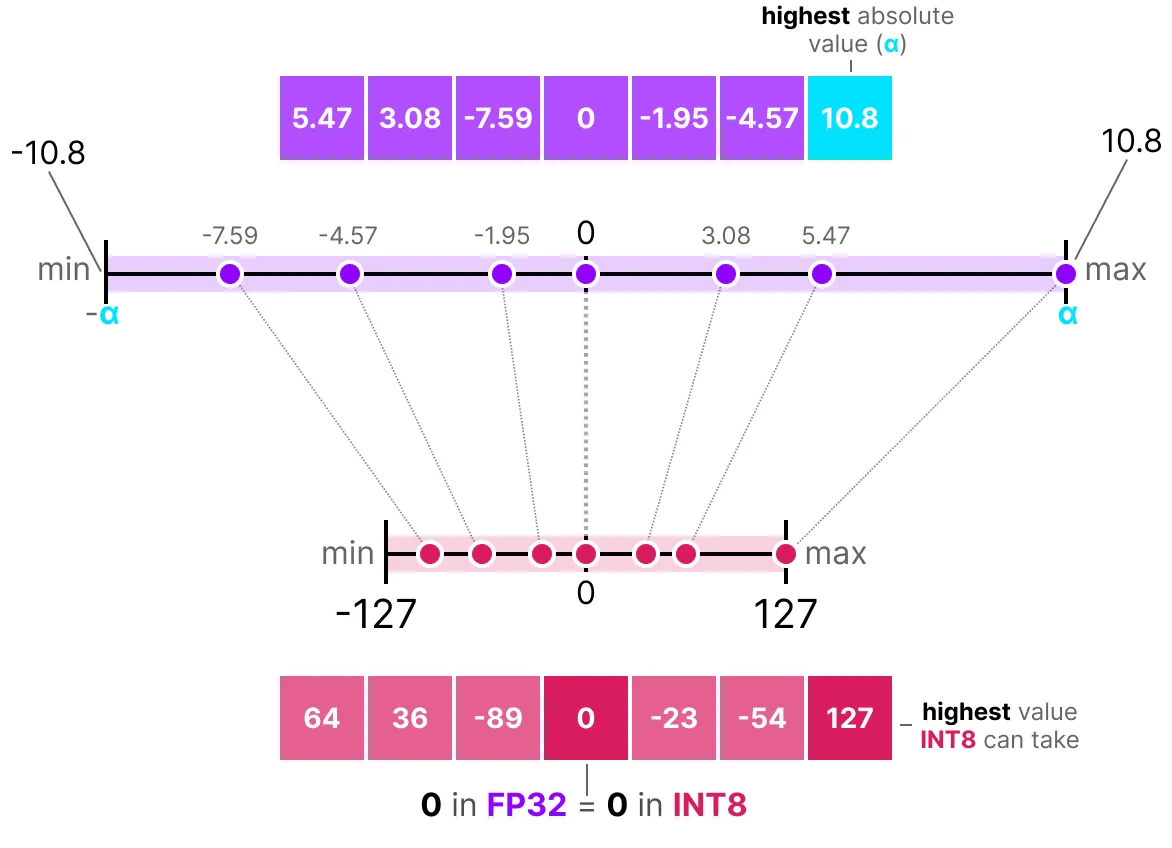
- کوانتایزیشن متقارن (Symmetric Quantization): نقطه صفر را ثابت نگه میدارد و برای شبکههای اعداد صحیح علامتدار ایدهآل است.
- کوانتایزیشن نامتقارن (Asymmetric Quantization): از یک آفست غیرصفر برای تطبیق بهتر با توزیع دادهها استفاده میکند.
- آموزش آگاه از کوانتایزیشن (QAT): افت دقت را در حین آموزش شبیهسازی میکند تا مدل با وزنهای جدید سازگار شود.
- کوانتایزیشن پس از آموزش (PTQ): کاهش دقت را بعد از اتمام آموزش اعمال میکند تا استقرار سریعتر شود.
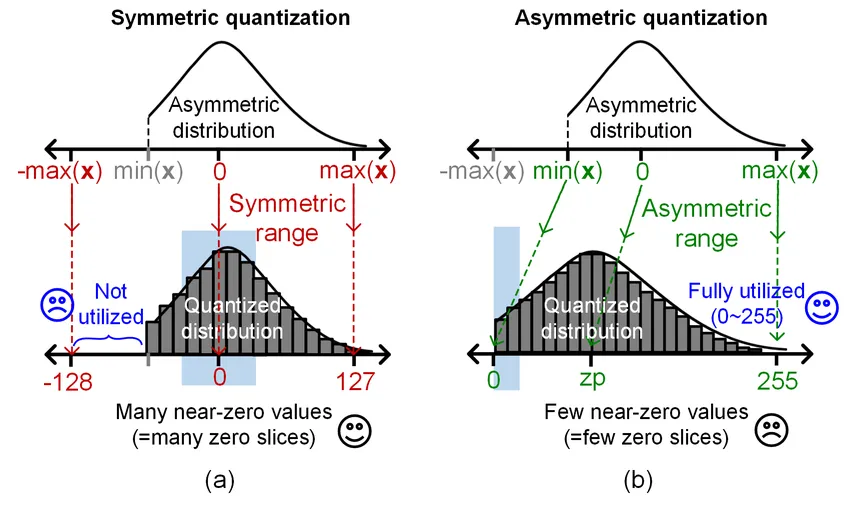
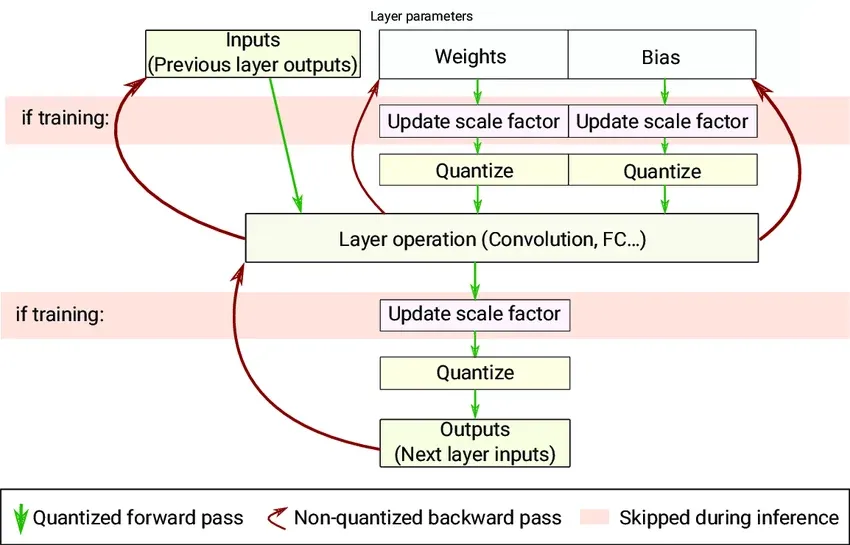
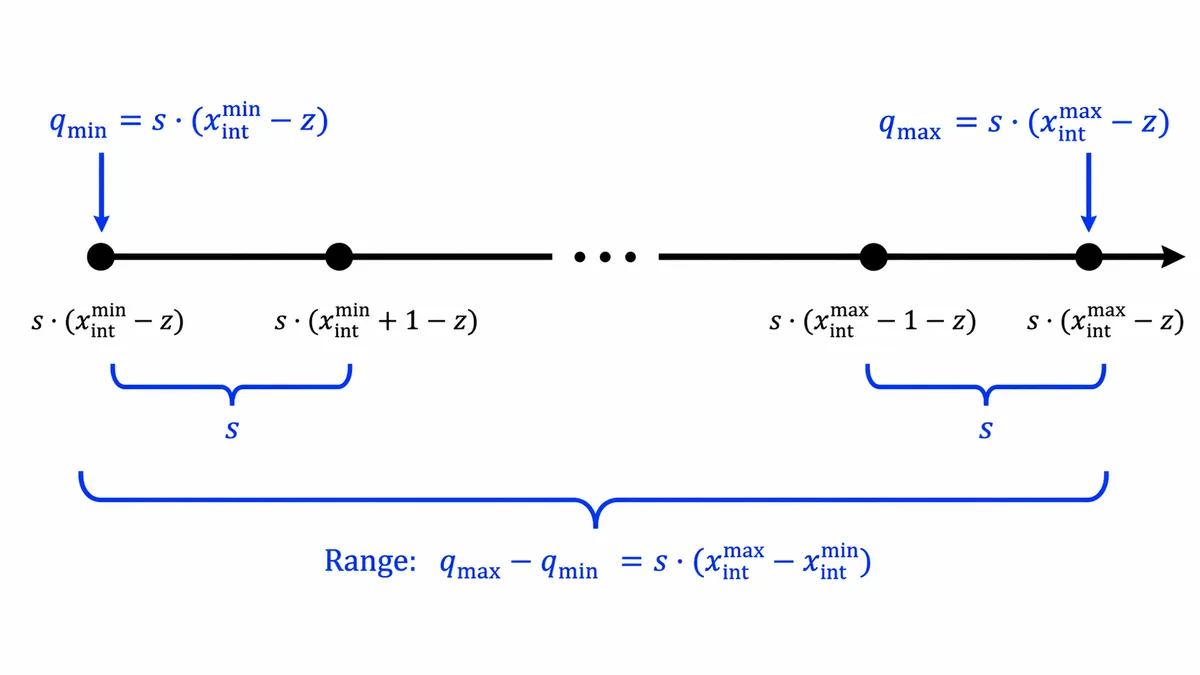
از دیدگاه کاربردی، این رویکرد فرض ما از سختافزار را تغییر میدهد؛ دیگر نیازی به آرایههای عظیم اعشاری برای هر عملیات نیست. سیستم با استفاده از یک مقیاس باز-کوانتایزیشن (M)، کل خط لوله را در محاسبات اعداد صحیح نگه میدارد و تنها یک عملیات اعشاری برای تغییر مقیاس لایهی بعدی انجام میدهد.
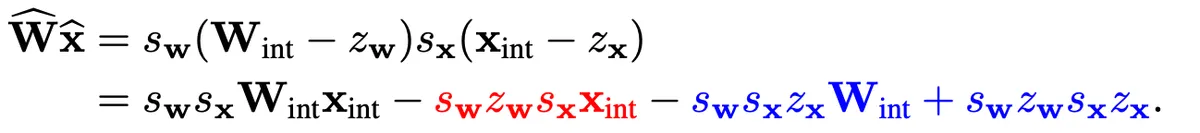
اگرچه کوانتایزیشن در سطح تانسور سادهترین روش است، اما طرحهای کانال-محور (per-channel) دقت بیشتری برای وزنهای حساس ایجاد میکنند. با این حال، این روش برای «فعالسازها» بهدلیل ایجاد ناکارآمدی سختافزاری در مرحله تجمعی، معمولاً توصیه نمیشود.
گام بعدی شما
- بررسی تفاوتهای عملکردی بین مدلهای کوانتیده شده با روش GPTQ در برابر AWQ.
- آزمایش استقرار مدلهای کوچکتر (SLM) با دقت ۴-بیت روی سختافزارهای لبه (Edge).
- مطالعه اثرات توزیعهای پرت (Outliers) در معماری ترنسفورمر بر دقت کوانتایزیشن.
اما داستان سختافزاری این تحول با ظهور تراشههای تخصصی حتی شگفتانگیزتر است — به تحلیل ما دربارهی معماری NPUها مراجعه کنید.



گفتگو