
تصور کنید برنامهنویسی هستید که ساعتها وقت خود را صرف خواندن مستنداتی میکند که از سال پیش بهروز نشدهاند و در نهایت کدش شکست میخورد. این کابوس تکراری در تیمهای مهندسی، اکنون جای خود را به سیستمی میدهد که در آن مستندات دیگر یک «تکلیف جداگانه» نیستند، بلکه اثر جانبی کدنویسیاند. فلسفه اصلی این تغییر، تبدیل مستندات از یک وظیفه اجباری به محصول جانبی کد است؛ رویکردی که ویکیهای دستی را با یک «پایگاه دانش زنده» جایگزین میکند.
به نقل از راهنمای فنی منتشرشده در سایت dev.to در ۲۴ ژوئن ۲۰۲۶، این رویکرد با جایگزینی ویکیهای دستی با یک پایگاه دانش زنده (Living Knowledge Base)، اصطکاک ثبت اطلاعات را از بین میبرد. در این سیستم، عاملهای هوش مصنوعی (AI Agents) — شبیه دستیارهای هوشمندی که تمام جزئیات جلسات و تغییرات کد را یادداشت میکنند — بینشهای فنی را در حین جلسات کاری فعال استخراج کرده و ثبت میکنند تا مانعی که معمولاً باعث قدیمی شدن مستندات داخلی میشود، حذف گردد.
کالبدشکافی نقاط درد (Pain Points)
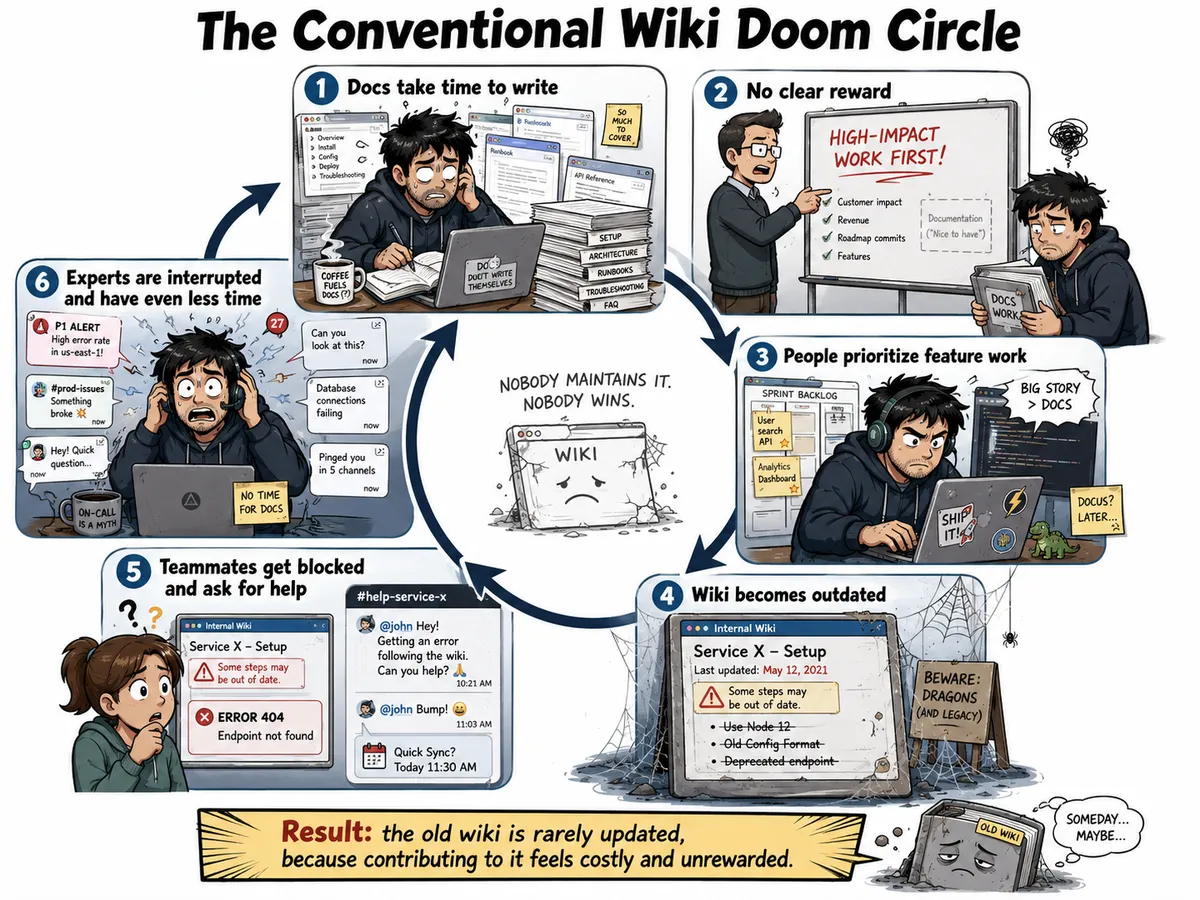
بیشتر تیمهای مهندسی از یک چرخه ناکارآمدی خاص رنج میبرند. یک توسعهدهنده جدید از او خواسته میشود تا روی یک سرویس جدید مسلط شود (Ramp up). او مستندات داخلی را بررسی میکند، یک روز کامل را صرف نوشتن یک اثبات مفهوم (POC) میکند و در نهایت شکست میخورد؛ چرا که مستندات بهروز نبودهاند. بدتر از آن، ممکن است سرویس خطایی را صادر کند که توسعهدهنده هرگز پیش از این ندیده است. نتیجه این است که جلسهای با یکی از اعضای تیم برنامهریزی میشود که احتمالاً تا دو روز آینده برگزار نخواهد شد.
در همین حال، مالک سرویس (Service Owner) غرق در فشار است. او نیمی از وقت خود را صرف نگهداری زیرساختها و نیمی دیگر را صرف پاسخ به سوالات تکراری مشتریان میکند. با وجود این فشار، مدیران همچنان داستانهای بزرگ (Big Stories) و درخواستهای ویژگیهای جدید را به عنوان اولویت اول فشار میدهند. مالک سرویس ممکن است اراده کند تا مستندات را بهروز کند تا دیگران دچار آن رنج نشوند، اما متوجه میشود که زمان کافی ندارد و از آن مهمتر، میبیند که مدیریت هرگز بابت انجام این کار به او پاداشی نخواهد داد.
این تنش یک «شکاف دانشی» ایجاد میکند؛ جایی که افرادی که تواناترینها برای مستندسازی یک سیستم هستند، کمترین زمان را برای انجام آن دارند. ویکیهای سنتی شکست میخورند زیرا نیازمند تلاش آگاهانه و دستی از سوی مشارکتکننده هستند. در برخی فرهنگهای سازمانی، این ریسک با تمایل به «انحصار دانش» برای تضمین امنیت شغلی تشدید میشود. علاوه بر این، مسئله رویتپذیری (Visibility) نقش دارد: کسی که در جریان یک حادثه زنده نقش «آتشنشان» را ایفا میکند، دیده شده و پاداش میگیرد، اما کسی که با مستندسازی دقیق از وقوع آن حادثه جلوگیری کرده است، نادیده گرفته میشود.
چرا هوش مصنوعی به تنهایی پاسخگو نیست؟
وسوسهبرانگیز است که اجازه دهیم هوش مصنوعی کل فرآیند آشنایی با پروژه (Ramp-up) را مدیریت کند. با این حال، در عمل، ابزارهای مستقل هوش مصنوعی اغلب دچار توهم (Hallucination) میشوند — یعنی حالتی که مدل با اطمینان چیزی میگوید که وجود ندارد، شبیه دوستی که خاطرهای را اشتباه تعریف میکند. هرچه یک پروژه خصوصیتر باشد، احتمال اشتباه AI بیشتر است، زیرا این ابزارها فاقد زمینه (Context) دقیق و مستند در مورد معماری داخلی و منطق اختصاصی آن پروژه هستند. این چالشهای استدلالی در مدلهای هوش مصنوعی، مشابه آنچه در حوزههای حساس مانند پزشکی رخ میدهد، نیاز به مکانیزمهای اجماع دارد؛ برای مثال، رویکرد PACT برای حل تداخلات استدلالی در مدلهای پزشکی تلاش میکند تا با استفاده از اجماع شاخهای، دقت پاسخهای AI را در محیطهای پیچیده افزایش دهد.
مکانیسم پایگاه دانش زنده
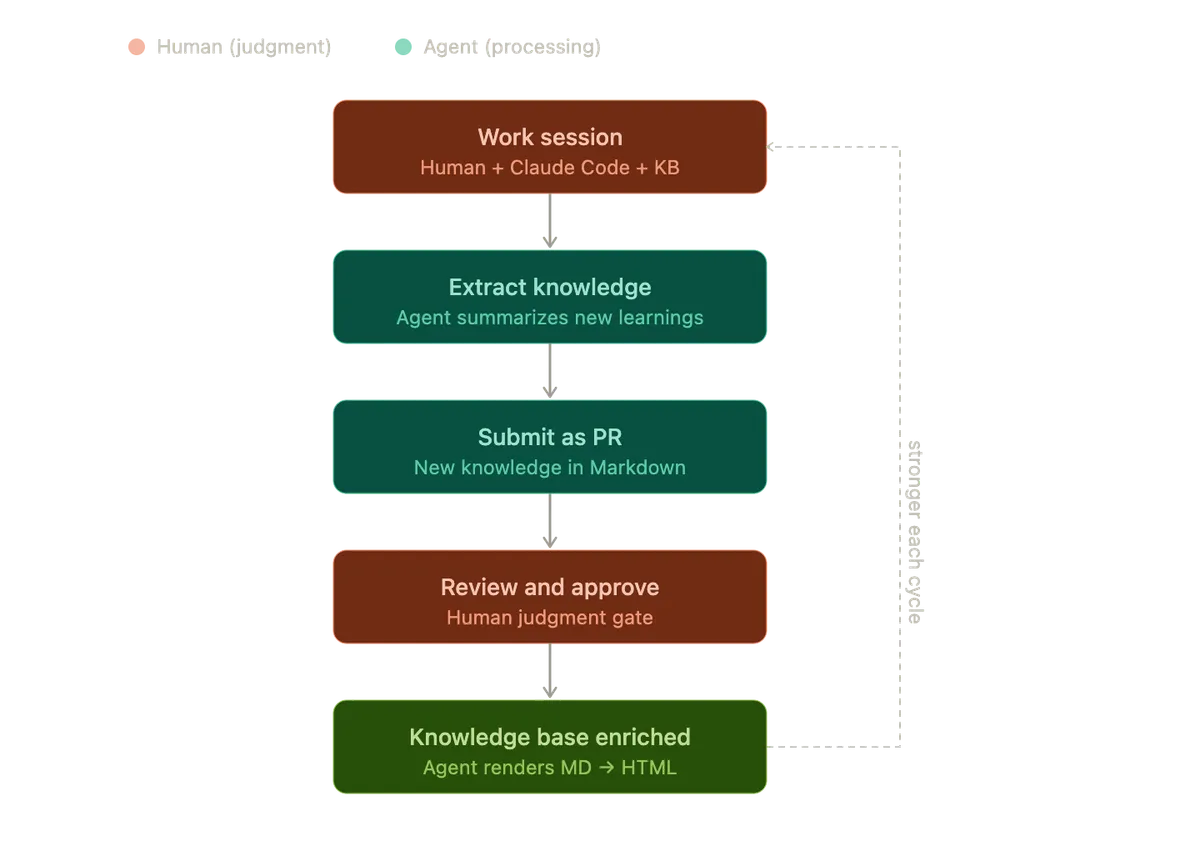
برای حل این مشکل، معماری پیشنهادی یک «پایگاه دانش زنده» را پیاده میکند. برخلاف یک ویکی ایستا، این ابزاری است که اطلاعات خاص مورد نیاز AI را فراهم میکند و در عین حال فضای همکاری باقی میماند که تیم از آن استفاده کرده و به آن کمک میکند. به عنوان مثال در یک سرویس استاندارد KMS/PKI، سیستم مستندات را در پوشههایی با دستهبندی منطقی ذخیره میکند. سپس ابزارهای AI برای بازیابی این مستندات بر اساس نیازهای خاص به کار گرفته میشوند.
این پایگاه دانش نماینده «حداقل مجموعه مشترک» از دانش برای تیم مالک سرویس است. از آنج keystroke که دو نفر در یک پروژه ممکن است برداشتهای متفاوتی داشته باشند، سیستم تنها «واقعیات» (Facts) را ذخیره میکند تا تضمین شود که تنها یک منبع واحد حقیقت (Single Source of Truth) وجود دارد.
جزئیات فنی و گردش کار
برای حذف اصطکاک نوشتن دستی، سیستم یک جریان فنی خاص را به کار میگیرد:
- مارکداون به عنوان مرجع: انسانها فقط در گرههایی (Nodes) ظاهر میشوند که نیاز به قضاوت دارد. آنها بهروزرسانیهای دانشی را در قالب Markdown که برای هر توسعهدهندهای نگهداریاش آسان است، بررسی و تأیید میکنند.
- خروجیهای تولیدی AI: عامل هوش مصنوعی، متن خام مارکداون را گرفته و آن را به HTML چندوجهی رندر میکند. این شامل ایجاد خودکار نمودارهای معماری، فلوچارتها و هایلایت کردن کدها است؛ ارزشافزودههایی که انسانها به ندرت برای ایجاد دستی آنها زمان دارند.
- اثر چرخی (Flywheel Effect): تمام توسعهدهندگان عاملهای خود را بر اساس این پایگاه دانش اجرا میکنند، به این معنی که جریان کاری روزانه آنها از قبل در زمینه (Context) عامل قرار دارد. آنها به جای نوشتن مستند از صفر، از یک «مهارت بهبود دانش» (Enhance-knowledge skill) استفاده میکنند.
- مستندات در قالب PR: عامل آنچه را که در طی یک جلسه کاری آموخته است خلاصه کرده و آن را به صورت یک Pull Request (PR) ارسال میکند. سپس یک متخصص سرویس آن را بازبینی و تأیید میکند.

با تبدیل مستندسازی به یک PR، این فرآیند از یک تکلیف خارجی به بخشی از چرخه استاندارد مهندسی تبدیل میشود. هر PR تأیید شده، عامل را هوشمندتر میکند و به نوبه خود به او اجازه میدهد دانش بهتری را برای توسعهدهنده بعدی استخراج کند. هزینه مشارکت تقریباً به صفر میرسد و ارزش به صورت خودکار انباشته میشود.
حل مشکل «پوسیدگی» مستندات
یکی از پایدارترین شکستهای مستندات داخلی، زوال یا قدیمی شدن آنهاست. برای مقابله با این مشکل، سیستم یک «قلاب تشخیص تاریخگذشتگی» (Staleness Detection Hook) زمانبندی شده را پیاده میکند. عامل به صورت دورهای پایگاه دانش را برای یافتن محتوایی که ممکن است منقضی شده باشد اسکن کرده و آن را برای بازبینی انسانی علامتگذاری میکند. این کار، عملیات نگهداری را با روال استاندارد مهندسی ادغام میکند و تضمین میکند که دانش به جای اینکه گورستان اطلاعات قدیمی باشد، یک دارایی زنده باقی بماند.
کاربردهای فراتر از مستندسازی
این لایه دانشی به عنوان یک لایه زیرساختی عمل میکند که سایر ابزارهای عاملمحور میتوانند روی آن بنا شوند. دو مثال اصلی عبارتند از:
۱. عاملهای آنکال (On-call Agents): تیم تمام حوادث (Incidents) پیشین را جمعآوری کرد تا یک مجموعه تست بسازد. اکنون عامل آنکال برنامههای اصلاحی (Remediation Plans) را بر اساس دادههای پایگاه دانش تولید میکند که باید با این سوابق تاریخی مطابقت داشته باشد.
۲. ابزارهای همگامسازی شاخه (Branch Sync): این ابزار که برای همکاری بین تیمی طراحی شده، تغییرات incoming از یک شاخه اصلی دیگر را تحلیل میکند. این ابزار استدلال میکند که تغییرات چیستند و چگونه ممکن است بر سرویس محلی اثر بگذارند؛ در واقع مانند یک متخصص سرویس عمل میکند که ۲۴ ساعته تغییرات را رصد میکند.

تفکرات نهایی درباره جریانهای کاری عاملمحور
ادغام هوش مصنوعی در هسته اشتراک دانش، تغییر بنیادینی در نحوه فعالیت مهندسان است. عصر برنامهنویسانی که در تنهایی کد میزنند به پایان رسیده و به سمت جریانهای کاری عاملمحور (Agentic Workflow) حرکت میکنیم که در آن خودِ سیستم، حافظه جمعی تیم را مدیریت میکند.
با این حال، این بهرهوری هزینهای به نام «بدهی شناسایی» (Recognition Debt) ایجاد میکند. هنگامی که عاملها به کیوریتورها و بازیابیکنندگان اصلی دانش تبدیل شوند، فرآیند انباشت دانش توسط خودِ توسعهدهنده ممکن است تخریب شود. اگر عامل مسئول «به یاد آوردن» باشد، انسان ممکن است مدلهای ذهنی عمیقی را که از طریق کلنجار رفتن با مستندسازی و سنتز دستی اطلاعات به دست میآمد، از دست بدهد.
برای تیمهایی که قصد پیادهسازی این سیستم را دارند، اولین قدم تغییر طرز فکر است: از نوشتن برای دیگران به قیمت از دست دادن وقت خود دست بردارید و برای خودتان کار کنید، و اجازه دهید دانش به عنوان یک اثر جانبی تولید شود. این یک تغییر از مدل «یک نفر برای همه مینویسد» به مدل «همه برای یکی، و یکی برای همه» است.
گام بعدی شما
- جایگزینی ویکیهای متنی با ساختارهای Markdown-based که توسط AI قابل خواندن باشند.
- تعریف یک گردش کار برای پذیرش مستندات در قالب Pull Request.
- پیادهسازی اسکنرهای دورهای برای شناسایی محتوای منقضی شده در مستندات.
این تحول در مدیریت دانش تنها بخشی از تغییرات است؛ اثر این معماری بر کاهش هزینه استنتاج در مقیاس سازمانی را در گزارش بعدی بررسی خواهیم کرد.



گفتگو