
تصور کنید سیستم توصیهگر شما در هر لحظه، حجم عظیمی از پهنای باند حافظه را صرف کپی کردن دادههای تکراری میکند. اگر هنوز به بهینهسازیهای نرمافزاری سنتی تکیه کردهاید، باید بدانید که با یک سقف رشد مواجه هستید که هیچ کدنویسی سادهای آن را نمیشکند.
در ۵ مه ۲۰۲۶، شرکت متا (Meta) از چارچوب بهینهسازی پخش درون-کرنلی (In-Kernel Broadcast Optimization یا IKBO) پرده برداشت. به نقل از گزارش pytorch.org است، این رویکرد از طریق «طراحی مشترک» مدل و سیستم، منطق پخش داده را مستقیماً در کرنلهای تعاملی ادغام میکند تا از ایجاد تانسورهای تکراری در حافظه جلوگیری شود.
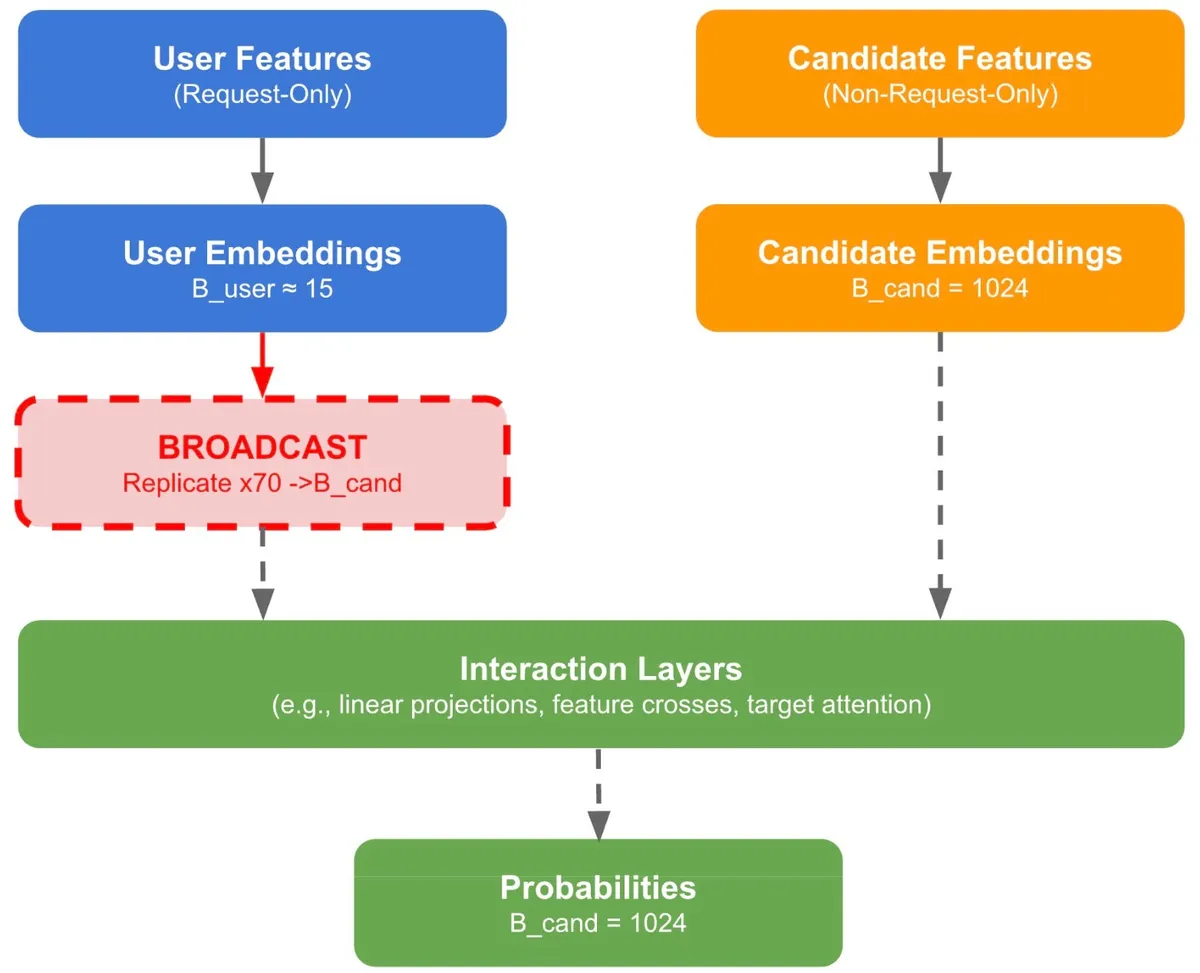
این سیستم اکنون در تمامی مراحل قیف توصیهگر متا، از جمله مدل رتبهبندی تطبیقی متا (Meta Adaptive Ranking Model)، روی پردازندههای گرافیکی انویدیا (NVIDIA) و شتابدهندههای MTIA (Meta Training and Inference Accelerator) پیادهسازی شده است. بر اساس مستندات فنی متا، نتایج بهدستآمده خیرهکننده است:
- فشردهسازی خطی: دستیابی به افزایش سرعت تقریباً ۴ برابری روی تراشههای H100 SXM5 از طریق تجزیه ضرب ماتریسی و همترازی حافظه.
- فلش اتنشن (Flash Attention): افزایش نرخ پردازش (Throughput) بین ۲.۴ تا ۶.۴ برابر نسبت به مدلهای پایه، با رسیدن به ۶۲۱ TFLOPs در فرمت BF16.
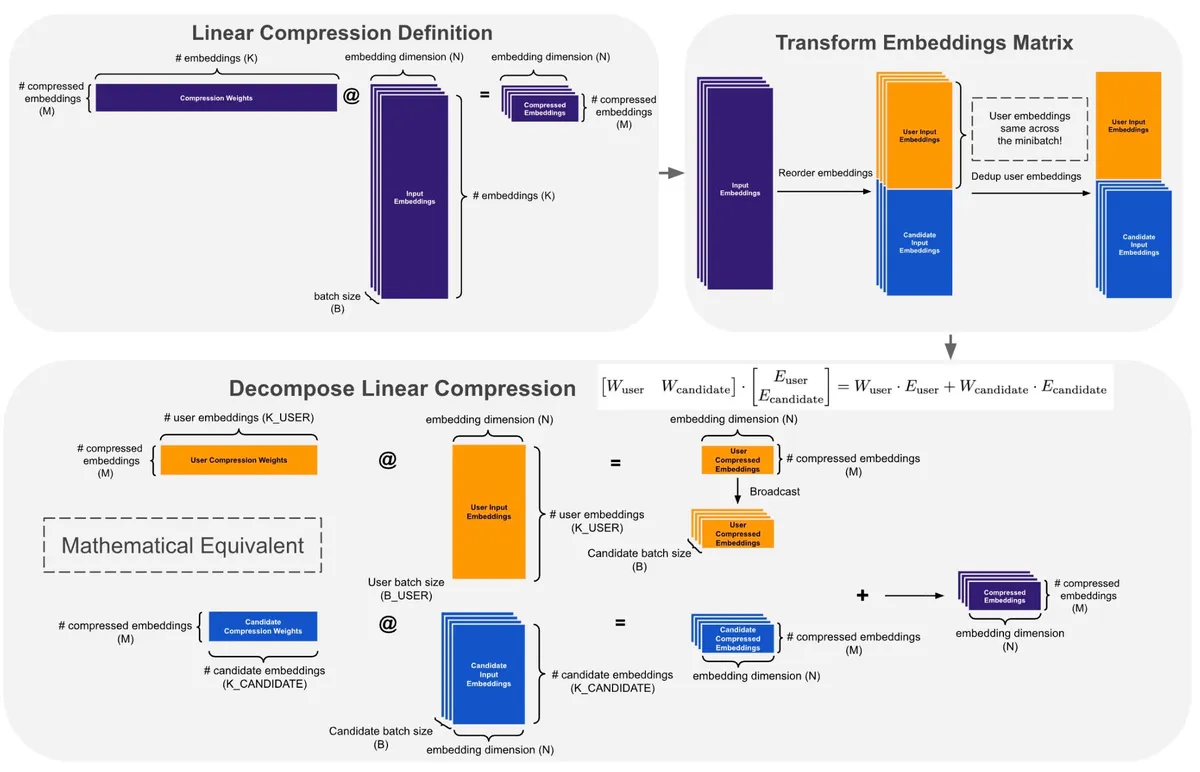
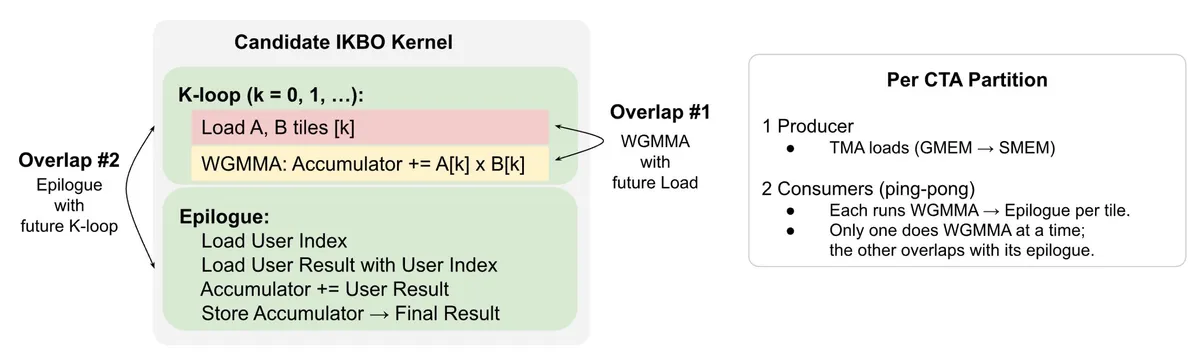
همانطور که در تحلیلهای پیشین ما دربارهی بهینهسازیهای سطح پایین در Triton اشاره کردیم، مدیریت حافظه در مقیاس بالا، تعیینکنندهی برنده در میدان رقابت است. متا برای رسیدن به این نتایج از TLX (Triton Low-Level Extensions) برای پیادهسازی «ادغام چندمرحلهای تخصصی-وارپ» استفاده کرده است تا تأخیر را با تقسیمبندی گروههای تولیدکننده و مصرفکننده در CTAها پنهان کند.

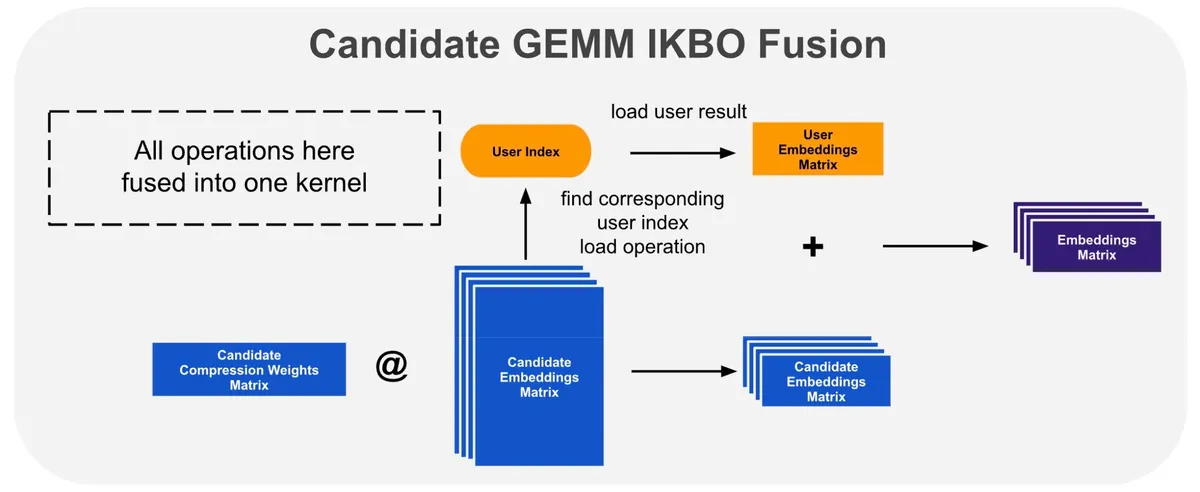
این فرآیند بهینهسازی در چهار گام دقیق اجرا شد: تجزیه ضربهای ماتریسی، پدینگ ابعاد K برای همترازی بهتر حافظه، ادغام پخشها در بخش Epilogue عملیات GEMM و در نهایت پیادهسازی ادغام تخصصی-وارپ.
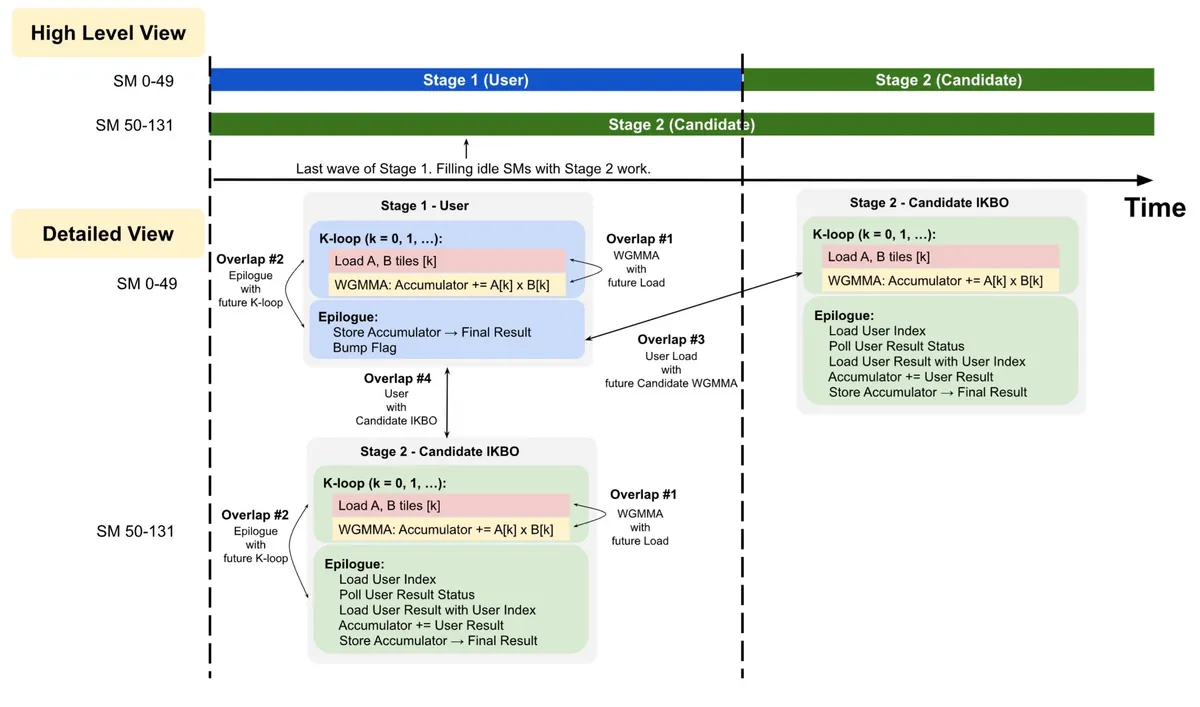
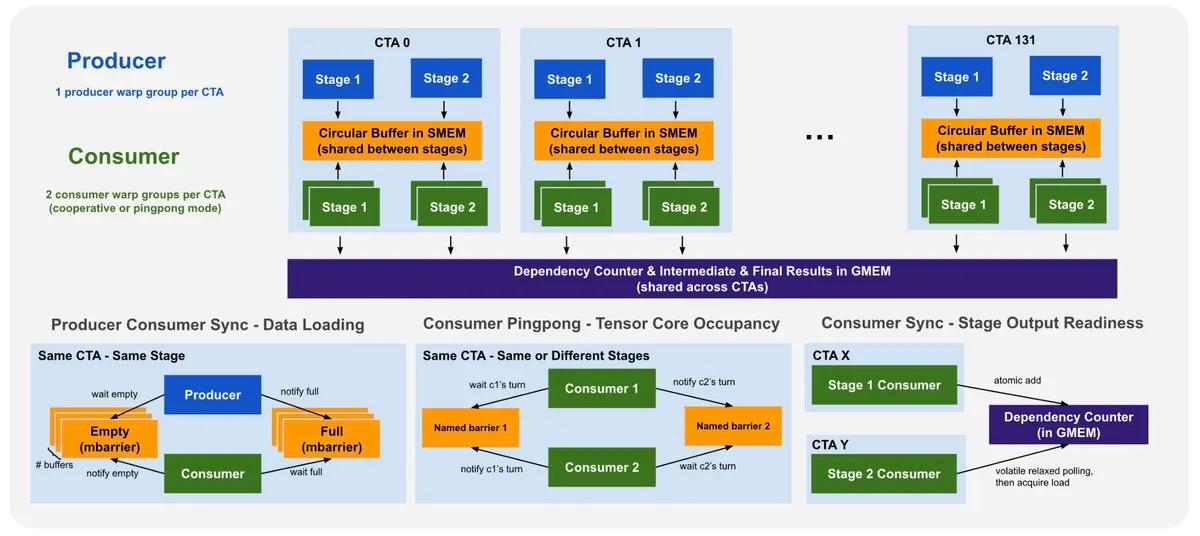
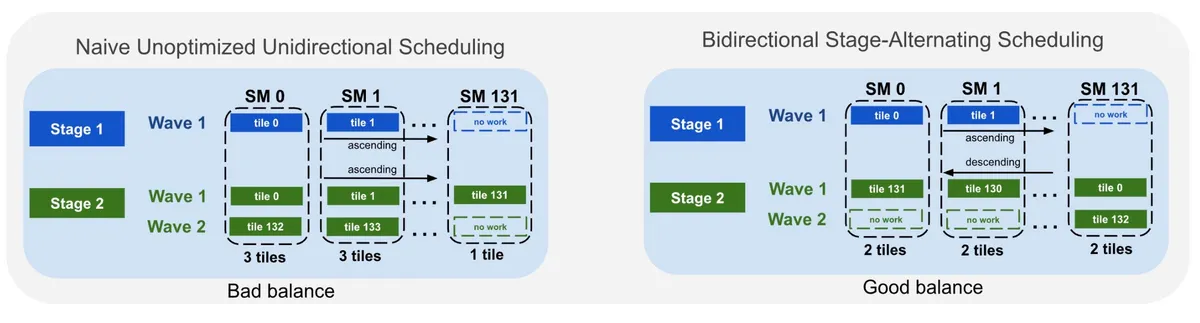
متا با تغییر تمرکز از سیستمهای «محدود به ورودی-خروجی» (IO-bound) به سیستمهای «محدود به محاسبات» (Compute-bound)، هزینه تعامل کاربر-کاندید را از تعداد کاندیدها جدا کرد. این یعنی اکنون میتوان الگوهای تعاملی پیچیدهتر و متراکمتری را بدون افزایش خطی هزینههای حافظه پیاده کرد.
اما این تنها بخشی از پازل است؛ تأثیر این بهینهسازی بر مدلهای چندوجهی در گزارش بعدی ما بررسی خواهد شد.
گام بعدی شما
- بررسی مستندات Triton برای درک نحوه مدیریت حافظه در سطح کرنل.
- تحلیل استراتژیهای همترازی حافظه (Memory Alignment) در مدلهای توصیهگر خود.
- مطالعه معماری MTIA برای درک تفاوتهای سختافزاری در استنتاج مقیاسپذیر.



گفتگو