
اگر امروز برای پردازش متون طولانی در مدلهای زبانی هزینههای گزاف میپردازید، باید بدانید که کاهش ۲۸.۴ برابری در محاسبات برای چنین زمینههایی اکنون به یک واقعیت تبدیل شده است. این رقم نه یک ادعای بازاریابی، بلکه نتیجهی تغییر در بنیادیترین بخش معماری مدلهای ترنسفورمر است.
در ۱ ژوئن ۲۰۲۶، آزمایشگاه MiniMax مستقر در شانگهای، مدل M3 را منتشر کرد. این نخستین مدل با وزنهای باز (Open Weights) است که بهطور همزمان پنجرهٔ زمینه (Context Window) یک میلیون توکنی و قابلیتهای چندوجهی (Multimodal) بومی را برای ورودیهای متنی، تصویری و ویدئویی ارائه میدهد. عرضه این مدل در راستای جریان اخیر انتشار مدلهای متخصص با وزنهای باز است که در هفتههای اخیر بازار هوش مصنوعی را متحول کرده است.
در مدلهای رایج، سازوکار توجه (Attention) بهصورت درجه-دو مقیاس مییابد؛ یعنی با دوبرابر شدن حجم متن، محاسبات چهاربرابر میشود. این همان مشکل O(n²) است که پیش از این، اجرای یک پاس پیشرو (Forward Pass) با یک میلیون توکن را برای توسعهدهندگان از نظر سختافزاری غیرممکن میکرد. در حالی که دیگران تلاش کردهاند از فشردهسازی KV-cache یا توجه خطی استفاده کنند، این روشها اغلب دقت را فدای سرعت میکنند. این چالش مقیاسبندی یک بار مشترک در سراسر صنعت است و مدلهای وزن-باز دیگری مانند Apertus 70B سوئیس را نیز تحت تأثیر قرار داده است.
MiniMax این چالش را با معرفی توجه پراکنده MiniMax (MSA) حل کرده است. به نقل از مقالهای که در arXiv (شناسه ۲۶۰۶.۱۳۳۹۲) منتشر شده، MSA بهجای پردازش کل پنجرهٔ متنی، تنها ۲۰۴۸ توکن مرتبط با هر پرسوجو را شناسایی میکند. این مکانیسم باعث میشود حجم محاسبات با رشد متن ثابت بماند و یک مقیاسبندی زیر-درجه-دو ایجاد شود. این رویکرد در واقع تکامل یافتهی مفاهیم توجه پراکنده زیر-کوادراتی است که پیشتر برای کاهش هزینههای استنتاج پیشنهاد شده بود.
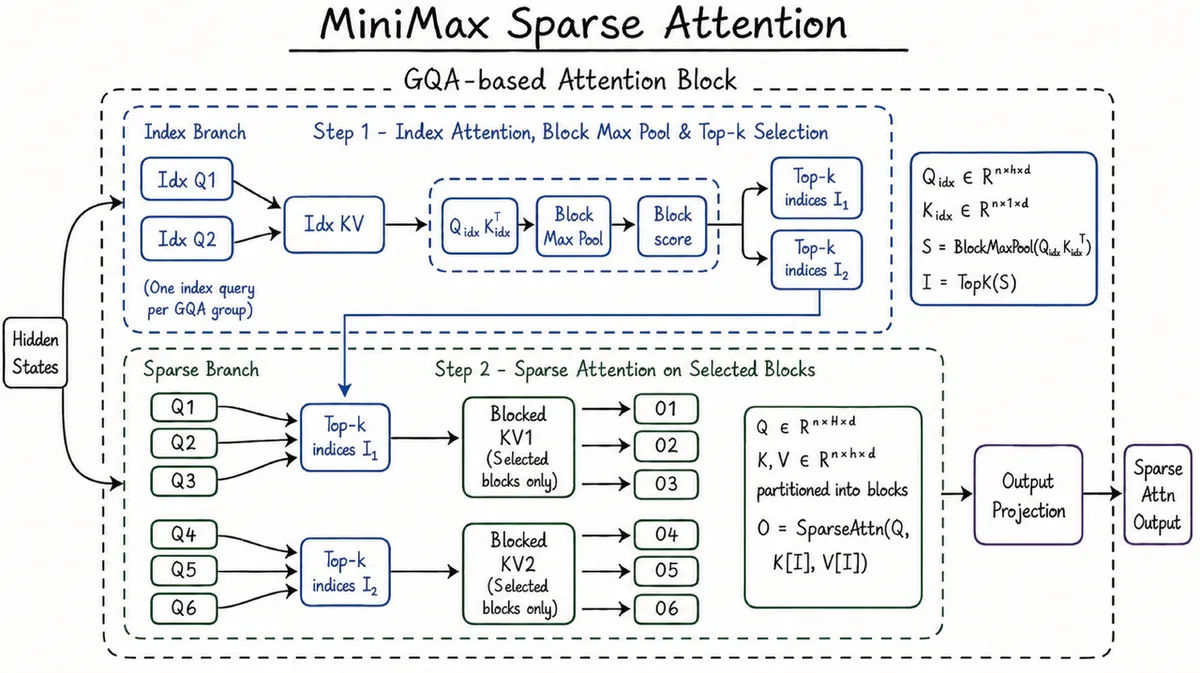
جزئیات معماری MSA
- انتخاب دو مرحلهای: MSA در دو مرحله عمل میکند. ابتدا یک شاخهٔ نمایهساز (Index Branch)، حافظهٔ KV را به بلوکهای ۱۲۸ توکنی تقسیم کرده و ۱۶ بلوک مرتبطترین را برای هر گروه GQA انتخاب میکند. این پراکندگیِ خاص برای هر گروه، MSA را از رویکردهای یکنواخت متمایز میکند. سپس شاخهٔ اصلی، توجه دقیق را تنها روی آن حدود ۲۰۴۸ توکن اجرا میکند.
- طراحی مشترک با GPU: برای تبدیل این تئوری به سرعت واقعی، تیم MiniMax یک کرنل سفارشی ساخت. ویژگیهای این کرنل شامل انتخاب k-برتر بدون نیاز به تابع exp (exp-free top-k selection)، توجه پراکنده KV-outer (که پرسوجوهای نیازمند یک بلوک یکسان را دستهبندی میکند) و دسترسی پیوسته به حافظه است تا تضمین شود هر بلوک تنها یکبار خوانده شود.
- دقت در برابر کارایی: MSA یک انشعاب معماری واقعی از توجه نهانی چندسره (MLA) در مدل DeepSeek است. در حالی که MLA دادههای KV را برای بهینهسازی حافظه به یک فضای نهان فشرده میکند، MSA روی دادههای KV فشردهنشده عمل میکند. این انتخاب باعث حفظ دقت بازیابی در متون بسیار طولانی میشود، هرچند هزینه حافظه را افزایش میدهد.
عملکرد و نمایشهای عملی
این مدل در محک SWE-bench Pro به امتیاز ۵۹.۰٪ رسید و با اختلاف اندکی از امتیاز ۵۸.۶٪ مدل GPT-5.5 پیشی گرفت. علاوه بر بنچمارکها، به گزارش MiniMax، این مدل در سه سناریوی خودمختار موفق بود:
- پژوهش دانشگاهی: مدل M3 توانست یک مقاله از ICLR ۲۰۲۵ را در مدت ۱۲ ساعت و با ثبت ۱۸ کامیت کد بازتولید کند.
- بهینهسازی کرنل: این مدل در عرض ۲۴ ساعت و با ۱۴۷ مورد ارسال کد (Submission)، به شتاب ۹.۴ برابری در یک کرنل CUDA FP8 GEMM دست یافت.
- آموزش مدل: M3 موفق شد به صورت کاملاً خودمختار، فرآیند آموزش را برای چهار مدل پایه آموزشندیده در یک بازه ۱۲ ساعته مدیریت کند. این قابلیتهای پیشرفته در گزارش اولیه عرضه M3 و تمرکز آن بر عاملهای هوشمند مورد بررسی قرار گرفته بود.
تحلیل هزینه و دسترسی
از نظر مالی، قیمت API این مدل در طرح تشویقی ۰.۳۰ دلار به ازای هر میلیون توکن ورودی است؛ در حالی که این رقم برای Opus 4.8 و GPT-5.5 حدود ۵.۰۰ دلار است. یک تسک کدنویسی معمولی با ۵۰۰ هزار توکن ورودی و ۱۰۰ هزار توکن خروجی در M3 حدود ۰.۲۷ دلار هزینه دارد که تقریباً ۵٪ هزینه مدل Opus 4.8 است. حتی با نرخهای استاندارد (۰.۵۴ دلار برای هر تسک)، M3 برای جریانهای کاری با حجم بالا، یک مرتبه ارزانتر است.
محدودیتهای حیاتی
با این حال، M3 محدودیتهای مشخصی دارد. این مدل تحت لایسنس MiniMax Community (CC BY-NC 4.0) منتشر شده است؛ این بدان معنای است که استفاده تجاری آن مستلزم انعقاد یک قرارداد جداگانه است و میزبانی شخصی برای مقاصد تجاری ممنوع است.
همچنین شکافهای عملکردی دیده میشود. استدلال انتزاعی مدل ضعیف است؛ به طوری که در آزمون ARC-AGI-2 نمراتی در محدوده «تکرقمی پایین» کسب کرد. توماس ویگولد، تحلیلگر مستقل، اشاره کرد که M3 حدود ۳۰ تا ۴۰ دقیقه روی یک شبیهسازی پوکر وقت صرف کرد اما در نهایت تنها نتایجی متوسط تولید کرد. این امر نشان میدهد M3 یک «مجری» توانمند است، نه یک جایگزین برای استدلال کلی.
در نهایت، کاربران باید موضوع حاکمیت دادهها را در نظر بگیرند. بهدلیل استقرار MiniMax در شانگهای، تمام ترافیک API بدون توجه به مکان کاربر، تحت قوانین دادههای چین است. علاوه بر این، بنچمارکهای خوداظهاری ممکن است خوشبینانه باشند؛ زیرا مقایسهها با Opus 4.7 (۶۴.۳٪) انجام شده است نه نسخه جاری Opus 4.8 (۶۹.۲٪)، که نشان میدهد فاصله با مدلهای پیشرو حدود ۱۰ درصد بیشتر از ادعاهای تیترهاست.
برای متخصصان، این معماری یک چرخش جدی از روند «فشردهسازی نهان» است. MiniMax با اثبات اینکه توجه پراکنده میتواند کیفیت کدنویسی پیشرو را حفظ کرده و همزمان «مالیات O(n²)» را حذف کند، یک نقشه راه مقیاسپذیر برای نسل بعدی مدلهای با زمینه طولانی ارائه داده است.
کاربران باید نتایج آتی و مستقل Chatbot Arena را دنبال کنند تا تأیید شود که آیا این بنچمارکهای خوداظهاری در برابر آخرین نسخههای Opus 4.8 و GPT-5.5 پایداری میکنند یا خیر.
برای متخصصان، این معماری یک چرخش جدی از روند «فشردهسازی نهان» است. MiniMax با اثبات اینکه توجه پراکنده میتواند کیفیت کدنویسی پیشرو را حفظ کرده و همزمان «مالیات O(n²)» را حذف کند، یک نقشه راه مقیاسپذیر برای نسل بعدی مدلهای با زمینه طولانی ارائه داده است.
کاربران باید نتایج آتی و مستقل Chatbot Arena را دنبال کنند تا تأیید شود که آیا این بنچمارکهای خوداظهاری در برابر آخرین نسخههای Opus 4.8 و GPT-5.5 پایداری میکنند یا خیر.
گام بعدی شما
- اگر روی پروژههای کدنویسی با حجم داده بالا کار میکنید، هزینه استنتاج خود را با نرخهای M3 مقایسه کنید.
- محدودیتهای لایسنس NC 4.0 را پیش از ادغام در محصولات تجاری بررسی کنید.
- نتایج مستقل Chatbot Arena را برای تأیید بنچمارکهای خوداظهاری M3 دنبال کنید.
اما اثر این کاهش هزینه بر استقرار عاملهای کدنویس در مقیاس صنعتی حتی تکاندهندهتر است؛ به تحلیل ما دربارهی آینده Agentic Workflow مراجعه کنید.



گفتگو