
تصور کنید برای تحلیل یک فایل صوتی پیچیده، دیگر نیازی به زنجیرهای از ۵ مدل تخصصی نباشد. اگر هنوز از سیستمهای تکمنظوره برای تبدیل گفتار به متن یا تشخیص صدا استفاده میکنید، باید بدانید که عصر مدلهای تکبعدی به پایان رسیده است.
OpenMOSS، MOSI.AI و مؤسسه نوآوری شانگهای از مدل MOSS-Audio پردهبرداری کردند؛ یک مدل بنیادی (Foundation Model) متنباز که تحلیل گفتار، موسیقی و صداهای محیطی را در یک سیستم واحد ادغام میکند. به نقل از MarkTechPost، این سیستم نیاز به خطلولههای پردازشی مجزا را حذف کرده و تحلیلهای صوتی را به شکلی یکپارچه انجام میدهد. بر اساس مستندات منتشر شده، معماری این مدل یک چرخش راهبردی در برابر رابطهای صوتی سنتی است.

بهرهوری خیرهکننده این مدل مدیون دو نوآوری کلیدی در معماری است:
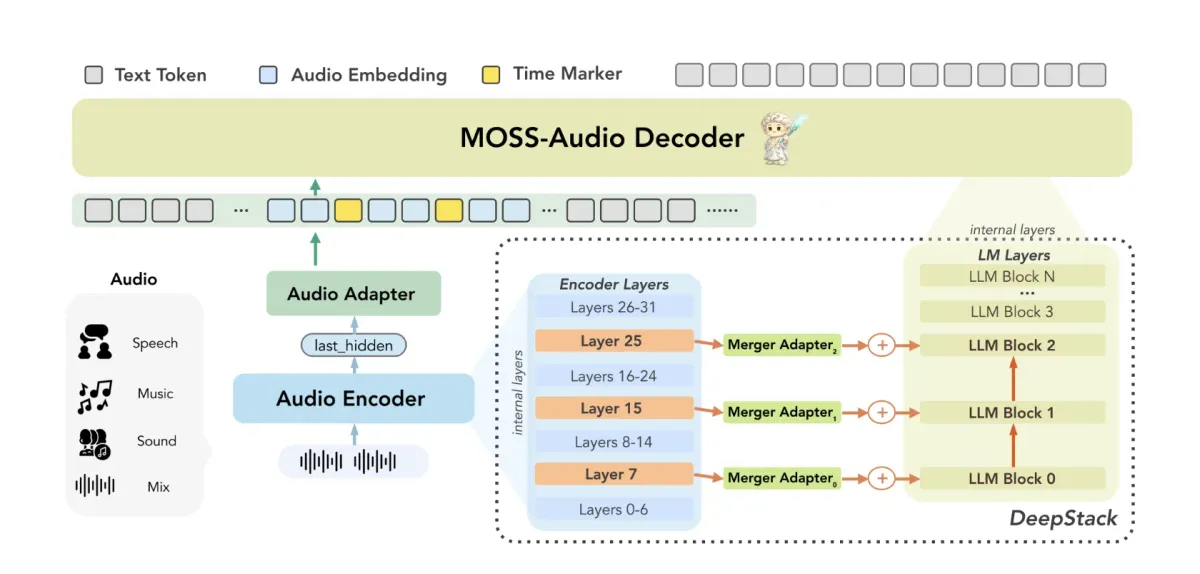
- تزریق ویژگیهای لایهای DeepStack: برخلاف مدلهای رایج که فقط به لایهی نهایی رمزگذار (Encoder) تکیه میکنند، MOSS-Audio ویژگیهای لایههای میانی را مستقیماً به مدل زبانی بزرگ (LLM) تزریق میکند. این کار باعث حفظ جزئیات آکوستیک ظریفی مانند طنین و آهنگ صدا میشود که معمولاً در لایههای انتزاعی بالا از بین میروند.
- نمایش آگاه از زمان (Time-Aware Representation): تیم توسعه با درج توکنهای زمانی صریح در مرحلهی پیشآموزش، به مدل آموخت که «چه اتفاقی در چه زمانی» رخ داده است، بدون اینکه نیاز به یک سرِ مکانیابی (Localization Head) مجزا باشد.
همانطور که در تحلیل قبلی ما دربارهی مدلهای چندوجهی (Multimodal) اشاره کردیم، بهینهسازی معماری همواره بر افزایش کورکورانهی پارامترها غلبه میکند. این موضوع در MOSS-Audio به وضوح دیده میشود؛ نسخهی MOSS-Audio-8B-Thinking با دقت متوسط ۷۱.۰۸ در چهار بنچمارک صوتی، توانست مدل ۳۳ میلیاردی Step-Audio-R1 (با دقت ۷۰.۶۷) و مدل ۳۰ میلیاردی Qwen3-Omni-30B-A3B-Instruct (با دقت ۶۷.۹۱) را شکست دهد.
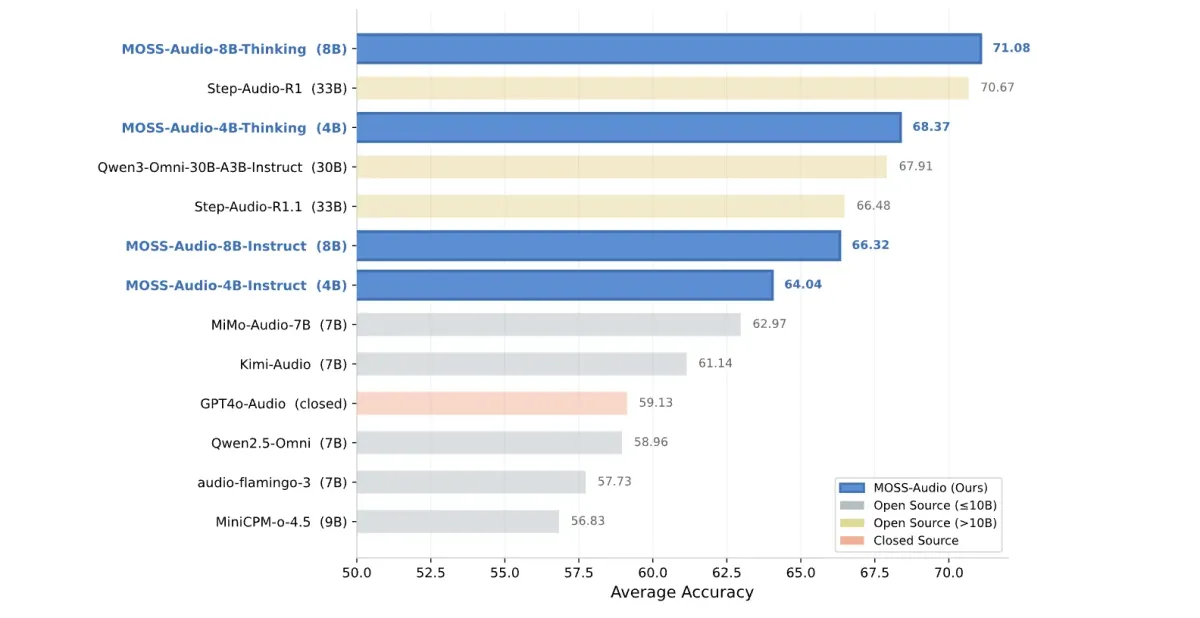
برای محیطهای عملیاتی، چهار نسخهی مختلف بر پایهی Qwen3 ارائه شده است. نسخههای «Instruct» برای خروجیهای ساختاریافته بهینه شدهاند، در حالی که نسخههای «Thinking» از زنجیره تفکر (Chain-of-Thought) برای استنتاجات چندمرحلهای استفاده میکنند. شایان ذکر است که نسخهی 8B-Instruct کمترین نرخ خطای نویسهای (CER) یعنی ۱۱.۳۰ را در ۱۲ بُعد ارزیابی ASR، از جمله در تحلیل آوازها و تغییر زبان (Code-switching) به دست آورده است.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی رایانش لبه (Edge Computing) مراجعه کنید.
گام بعدی شما
- اگر توسعهدهنده هستید، وزنهای باز (Open Weights) این مدل را برای جایگزینی سیستمهای چندمرحلهای صوتی آزمایش کنید.
- تفاوت عملکردی نسخههای Thinking و Instruct را در تحلیلهای پیچیده صوتی مقایسه کنید.
- بر روی کاهش تأخیر (Latency) در استقرار مدلهای ۸ میلیاردی در محیطهای لبه تمرکز کنید.



گفتگو