
اگر هنوز فکر میکنید کندی عاملهای هوش مصنوعی به دلیل محدودیت سختافزاری است، سخت در اشتباهید. باید بدانید که گاهی یک خطای کوچک در سرآیند (Header) صورتحساب میتواند عملکرد یک عامل (Agent) — تشبیه روزمره: دستیاری که نه تنها حرف میزند، بلکه میتواند ابزارها را برای انجام کارها به کار بگیرد — را تا ۵۰۰٪ کاهش دهد.
به نقل از وبسایت developer.nvidia.com در تاریخ ۸ مه ۲۰۲۶، انویدیا (NVIDIA) مجموعهای از اصلاحات معماری را در موتور Dynamo پیاده کرده است تا پدیدهای به نام مسمومیت حافظه کلید-مقدار (KV cache poisoning) را متوقف کند. این پدیده زمانی رخ میدهد که متادیتای مربوط به هر نشست، موتور را مجبور میکند هر درخواست جدید را مانند یک شروع سرد (Cold Prefill) پردازش کند.
همانطور که در تحلیل قبلی ما دربارهی بهینهسازی مدلهای زبانی اشاره کردیم، پایداری در لایهی سرویس به اندازه خودِ مدل اهمیت دارد. در جریانهای کاری عاملمحور (Agentic)، سیستمها به ساختارهای تکرارپذیر بزرگی از پرامپتها تکیه میکنند. وقتی این ساختارها به دلیل تغییرات جزئی در سرآیندها بههم بریزند، قابلیت استفاده مجدد از توکنهای ذخیرهشده از بین میرود و نتیجه آن، جهشهای شدید در تأخیر پاسخدهی است.
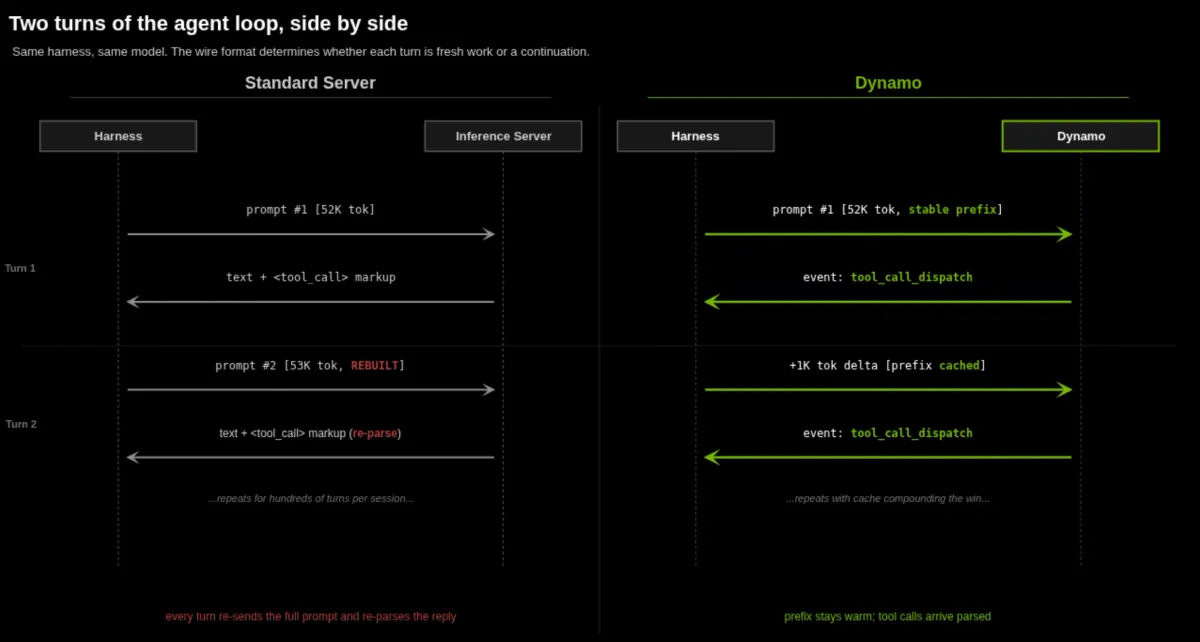
بر اساس مستندات فنی انویدیا، راهکار این مشکل معرفی پرچم --strip-anthropic-preamble است. در آزمایشهای انجام شده با مدل NVIDIA-Nemotron-3-Super-120B-A12B-NVFP4 و یک پرامپت ۵۲ هزار توکنی، نتایج تکاندهنده بود:
- زمان تا اولین توکن (TTFT) — تشبیه روزمره: فاصله زمانی بین پرسیدن سؤال و لحظهای که اولین کلمه از دهان مدل خارج میشود — از ۹۱۲ میلیثانیه به ۱۶۹ میلیثانیه کاهش یافت.
- حل مشکل «بازپخش استدلالی» (Reasoning Replay) برای حفظ پیوستگی زنجیرهی تفکر در ابزارهای مختلف.
- پشتیبانی از ارسال استریم ابزارها (Streaming Tool Dispatch) از طریق کانال SSE، که اجازه میدهد ابزارها بهصورت موازی با تولید متن اجرا شوند.
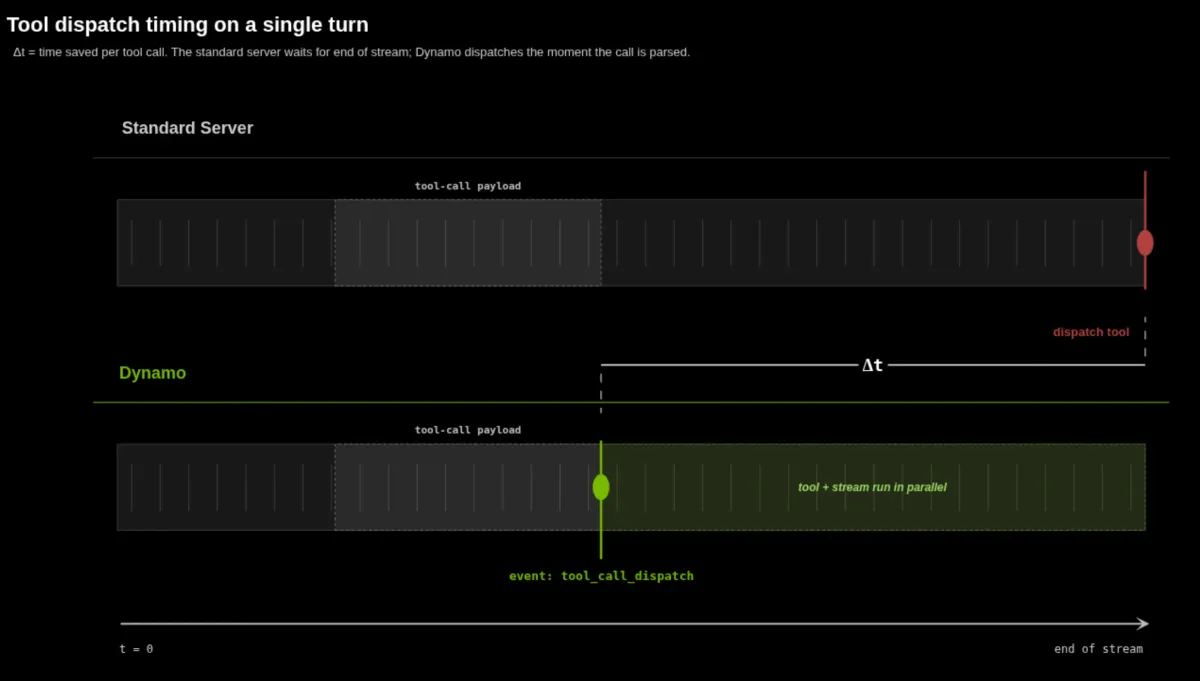
این تحول نشان میدهد که هوشمندی مدل اگر با یک لایهی سرویس «همراستا» (Fidelity-aligned) همراه نباشد، بیفایده است. برای مثال در Codex، استفاده از یک پروفایل عمومی به جای کاتالوگ اختصاصی مدل، میتواند تعداد دفعاتی که یک عامل از ابزارها استفاده میکند را به نصف کاهش دهد و اساساً رفتار حل مسئلهی آن را تغییر دهد. در واقع، گلوگاه دیگر فقط وزنهای مدل نیست، بلکه دقت قراردادهای API است.
توسعهدهندگان اکنون میتوانند از طریق کریتهای Rust، از جمله dynamo-parsers و dynamo-tokenizers به این قابلیتها دسترسی داشته باشند. انتظار میرود این اجزا بهزودی در سیستمهای خودمختار پیچیدهتری مانند AutoResearch ادغام شوند.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.
گام بعدی شما
- اگر از مدلهای Nemotron استفاده میکنید، فوراً پرچم
--strip-anthropic-preambleرا برای کاهش TTFT تست کنید. - ساختار API خود را بررسی کنید تا مطمئن شوید متادیتای متغیر در هر درخواست، باعث پاک شدن حافظه کش (Cache) مدل نمیشود.
- برای پیادهسازی سیستمهای سریعتر، از کتابخانههای Rust مربوط به Dynamo برای توکنبندی بهینه استفاده کنید.



گفتگو