
تصور کنید هر بار برای استخراج یک گزارش ساده، باید ساعتها با نقشههای پیچیده پایگاهداده دستوپنجه نرم کنید. پایلوتبیس (Pilotbase) قصد دارد این دشواری را با تبدیل دیتابیس به یک شریک گفتوگو، بهکلی حذف کند. به نقل از مستندات پروژه، این رابط گرافیکی جامع که در ۵ ژوئیه ۲۰۲۶ وارد مرحله بتا شد، جستوجوی دستی برای یافتن جداول را با یک گردشکار عاملمحور (Agentic) جایگزین میکند که روابط بین ستونها و جداول را بهصورت لحظهای میفهمد.
برای اکثر مهندسان، چالش اصلی مدیریت دیتابیس نوشتن کد نیست، بلکه بهخاطر سپردن ساختار (Schema) است. وقتی میخواهید به سؤالی مثل «کدام بخش بیشترین دستمزد را دارد؟» پاسخ دهید، باید ابتدا ساختار دیتابیس را به یاد آورید، تعیین کنید کدام جداول باید با هم پیوند (Join) شوند، کد SQL را بنویسید و در نهایت نتایج را تفسیر کنید. در دیتابیسهای حجیم، این فرآیند شامل ملاحظات پیچیدهتری مثل بررسی ایندکسها، تحلیل طرحهای کوئری (Query Plans) و جلوگیری از مشکلات رایج عملکردی مانند خطاهای تکرار کوئری (N+1) است.
وقتی یک توسعهدهنده مجبور است بین محیطهای متفاوتی مثل Postgres و MongoDB جابهجا شود، بار ذهنی مربوط به پیوند زدن جداول یا نوشتن خط لولههای تجمیعی (Aggregation Pipelines) باعث کند شدن تحلیلهای اکتشافی میشود. همانطور که در تحلیلهای پیشین ما دربارهی اتوماسیون ابزارهای توسعه اشاره کردیم، کاهش اصطکاک بین «قصد کاربر» و «اجرای فنی»، کلید بهرهوری جدید است. پایلوتبیس دقیقاً در همین نقطه عمل کرده و به عنوان پلی میان نیت انسان و اجرای ماشین عمل میکند تا جابهجایی ذهنی بین دیتابیسهای مختلف را سریعتر و روانتر کند.
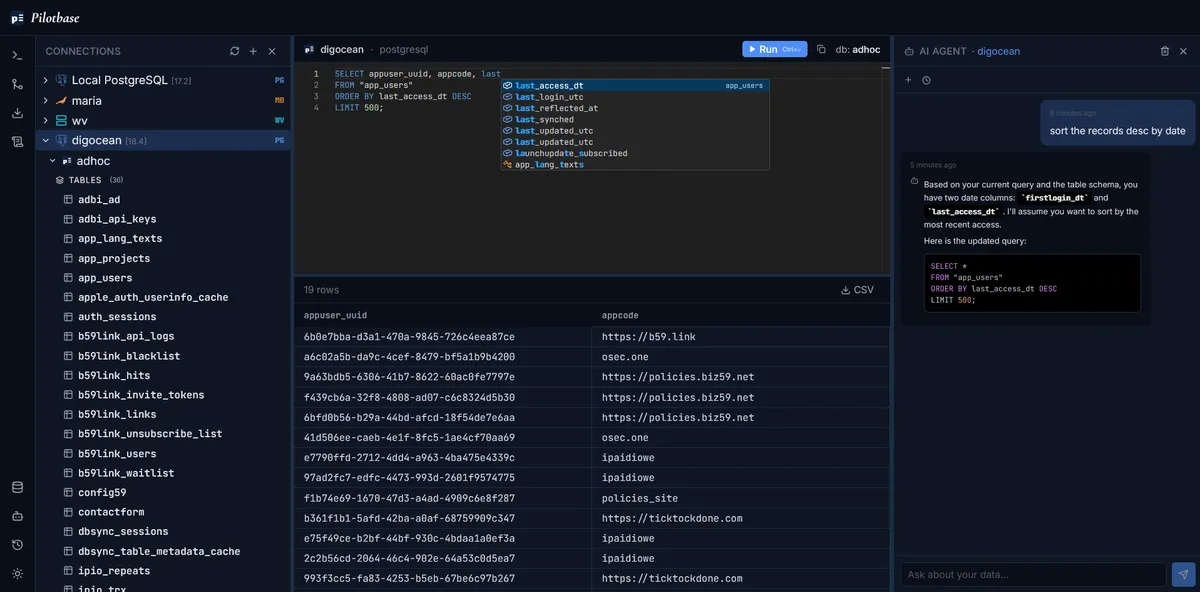
طبق گزارش فنی منتشرشده در dev.to، این سامانه بر پایه لنگگراف (LangGraph) و الگوی ریاکت (ReAct) بنا شده است. ریاکت (Reasoning + Acting) — شبیه به شطرنجبازی که قبل از هر حرکت، چند گام جلوتر را میبیند و بر اساس واکنش حریف تصمیمش را اصلاح میکند — یک فرآیند چرخهای است: مدل ابتدا فکر میکند، سپس یک اقدام انجام میدهد، نتیجه را مشاهده میکند و در نهایت رویکرد خود را بر اساس مشاهدات جدید تنظیم میکند.
این حلقه تکرار برای کارهای دیتابیس حیاتی است. اگر عامل در انتخاب جدول دچار اشتباه شود، بهجای توقف یا ارائه پاسخ غلط، میتواند بهصورت منعطف به عقب بازگردد تا ساختار دیتابیس را به روش متفاوتی بررسی کند، یا در صورت مبهم بودن قصد کاربر، سؤالات شفافکنندهای بپرسد. این عامل برای پیمایش محیط از یک مجموعه ابزار تخصصی استفاده میکند:
list_databases: شناسایی دیتابیسهای متصل برای تعیین اینکه دادههای مورد نیاز در کدام یک قرار دارند.describe_table: استخراج جزئیات دقیق ساختار، شامل نام ستونها، انواع دادهها و روابط بین جداول.execute_query: اجرای نهایی دستورات SQL، خط لولههای تجمیعی MongoDB یا سایر پرسوجوها.ask_clarification: درخواست راهنمایی از کاربر در زمانی که قصد او مبهم است تا از دقت پاسخ اطمینان حاصل شود.
این سازوکار باعث میشود دقت و ایمنی سیستم به شدت بالا برود. برای مثال، اگر کاربر بخواهد «۱۰ مشتری برتر بر اساس مجموع خرید را به تفکیک دستهبندی محصولات» ببیند، عامل حدس نمیزند. او ابتدا لیست دیتابیسها را میگیرد، جداول مشتریان (Customers)، سفارشات (Orders) و دستهبندی محصولات (Product Categories) را توصیف میکند و سپس یک عملیات پیوند (Join) ساختاریافته را طراحی میکند.
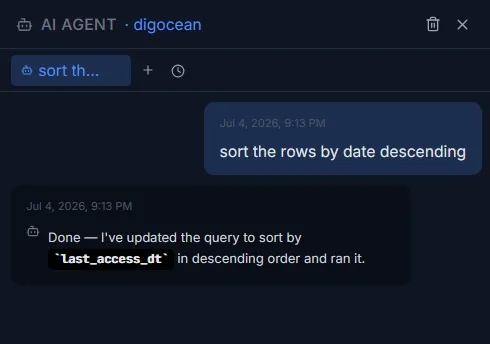
یک نکته کلیدی این است که عامل پیش از هر اجرای عملیاتی، هشدار داده و تأییدیه کاربر را میگیرد. این لایهی حفاظتی مانع از اجرای دستورات فاجعهباری میشود که میتوانند دادهها را نابود کنند، مانند اجرای یک دستور خام DROP TABLE. پس از تأیید کاربر، مدل منطق خود را به زبان ساده توضیح میدهد: «من جداول مشتریان، سفارشات و محصولات را بر اساس شناسه سفارش (order_id) و شناسه محصول (product_id) پیوند زدم، نتایج را بر اساس دستهبندی گروهبندی کردم و مشتریان را بر اساس مجموع مبلغ سفارش رتبهبندی نمودم».
در بحث امنیت و حاکمیت داده، پایلوتبیس از اولاما (Ollama) استفاده میکند تا تیمها بتوانند مدلهای بازمتن قدرتمندی مثل میسترال (Mistral) یا گما (Gemma) را بهصورت درونسازمانی (On-premises) اجرا کنند. این بدان معناست که ساختارهای دیتابیس و کوئریهای حساس هرگز از شبکه محلی خارج نمیشوند؛ شرطی که برای بخشهای حساس مثل بهداشت و درمان، امور مالی یا صنایع دفاعی غیرقابل مذاکره است. اگرچه کاربران میتوانند با تغییر در فایل تنظیمات (Config)، سیستم را به APIهای OpenAI متصل کنند، اما رویکرد «اول-محلی» (Local-first) تضمینکننده حاکمیت کامل بر دادههاست.
معماری زیربنایی این سیستم بر پایه یک پشته (Stack) بهینه است:
- Frontend: React
- Backend: FastAPI
- منطق عامل: LangGraph (ReAct)
- آداپتورها: SQLAlchemy, pymongo, redis-py و موارد دیگر.
- پایگاههای داده تحت پشتیبانی: Postgres, MongoDB, Redis, Qdrant و دیتابیسهای بیشتر.
این طراحی ماژولار باعث میشود عامل «پلاگینپذیر» باشد و توسعهدهندگان بتوانند بهراحتی مدلهای زبانی (LLM) را تعویض کرده یا آداپتورهای جدیدی برای دیتابیسهای ناشناخته اضافه کنند.
البته نویسنده پروژه اشاره میکند که مدلهای زبانی هنوز دچار توهم (Hallucination) میشوند و گاهی نام جداول یا منطقهای غیرموجود را اختراع میکنند. همچنین کوئریهای با پیچیدگی بالا که شامل زیر-پرسوجوهای (Subqueries) متعدد هستند، میتوانند عامل را گیج کنند. در مورد NoSQL نیز، پشتیبانی از نوشتن دادهها در MongoDB هنوز در مرحله برنامهریزی است و قابلیتهای فعلی برای دیتابیسهای NoSQL تنها در سطح «خواندنی» (Read-only) است.
با وجود این محدودیتها، بزرگترین دستاورد این ابزار، تسهیل اکتشاف در دادهها (Exploratory Analysis) و پاسخ به سؤالات «این دادهها چه شکلی هستند؟» است. این تغییر رویکرد، مانع ورود تحلیلگران تازهکاری را که متخصص SQL نیستند، بهشدت کاهش میدهد. این نرمافزار با مجوز MIT منتشر شده و توسعهدهندگان میتوانند با کلون کردن مخزن رسمی گیتهاب (https://github.com/icedsg/pilotbase.git) و اجرای یک build استاندارد در Docker Compose، آن را مستقر کنند.
گام بعدی شما
- اگر با دیتابیسهای چندگانه سر و کار دارید، مخزن GitHub پروژه را کلون و با Docker Compose اجرا کنید.
- برای امنیت حداکثری، مدلهای سبک Gemma را از طریق Ollama روی سختافزار محلی تست کنید.
- در کوئریهای بسیار پیچیده، خروجی عامل را با دقت بازبینی کنید تا اثر توهمات احتمالی مدل خنثی شود.
اما داستان سختافزاری اجرای این مدلها در محیطهای محلی حتی پیچیدهتر است — به تحلیل ما درباره تأثیر کوانتش مدلها بر سرعت استنتاج مراجعه کنید.



گفتگو