
اگر تا به حال فکر کردهاید چرا یک مدل هوش مصنوعی یک اشتباه خاص را مدام تکرار میکند، پاسخ در «اندازهی گام» سیستم پاداش آن است. باید بدانید که اصلاح این رفتارها، برخلاف تصور عموم، نتیجهی جادوی نرمافزاری نیست، بلکه یک محاسبهی دقیق ریاضی است.
در ۱۵ مه ۲۰۲۶، یک راهنمای عملی در وبسایت dev.to بهطور دقیق بررسی کرد که گرادیانهای سیاست (Policy Gradients) چگونه یک تصمیم غلط را به یک اصلاح ریاضی تبدیل میکنند. این فرآیند شبیه آموزش یک سگ است؛ وقتی سگی روی مهمان میپرد، شما یک سیگنال منفی میدهید تا آن رفتار متوقف شود. در یادگیری تقویتشده (Reinforcement Learning) — که دقیقاً مثل همین آموزش سگ است و مدل را با جایزه و تنبیه هدایت میکند — این سیگنال یک مقدار پاداش است که به شبکه عصبی (Neural Network) میگوید دفعهی بعد از این مسیر عبور نکند.
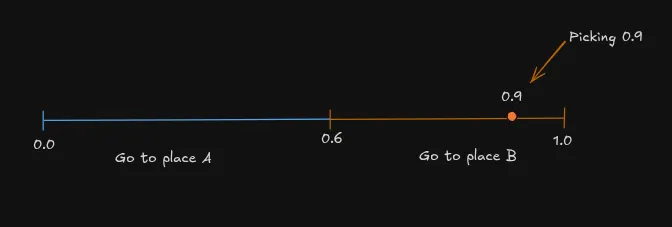
همانطور که در تحلیلهای قبلی ما دربارهی همراستاسازی (Alignment) مدلها اشاره کردیم، کنترل این سیگنالها کلید دستیابی به پاسخهای دقیق است. برای درک بهتر، این راهنما سناریوی سادهای دربارهی «گرسنگی» مثال میزند. مدل باید بین مکان A و B یکی را انتخاب کند. طبق گزارش dev.to، اگر ورودی گرسنگی پایین باشد، انتخاب مکان B (که سیبزمینی سرخکرده دارد) اشتباه است.
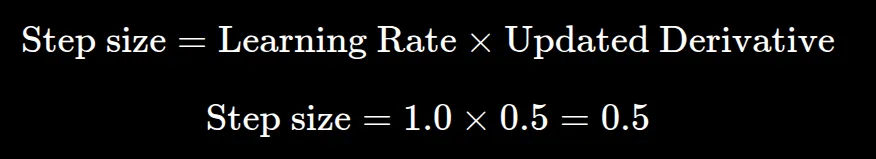
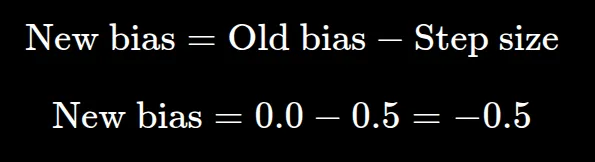
بر اساس مستندات این آموزش، مدل این خطا را با توالی زیر اصلاح میکند:
- نرخ یادگیری (Learning Rate): روی ۱.۰ تنظیم شده که اندازه گام اولیه را ۰.۵ میکند.
- تخصیص پاداش: چون انتخاب مدل غلط بود، پاداش -۱ دریافت میکند.
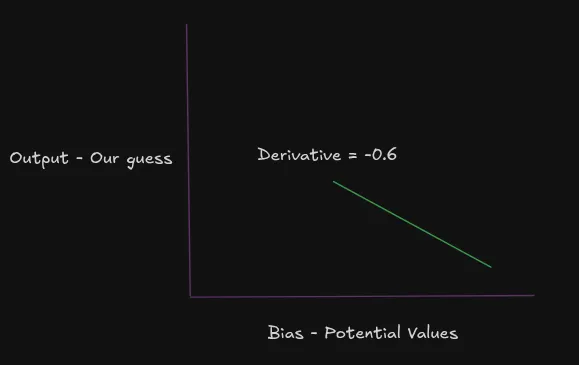
- بهروزرسانی گرادیان: سیستم تفاوت بین مقدار ایدهآل (۱.۰) و احتمال فعلی (۰.۴) را محاسبه میکند.

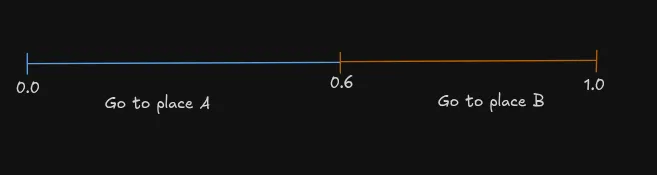
با ضرب مشتق در پاداش -۱، مشتق بهروزرسانیشده مثبت (۰.۶) میشود. این تغییر باعث میشود در آینده، وقتی گرسنگی پایین است، احتمال انتخاب مکان B توسط مدل کاهش یابد.
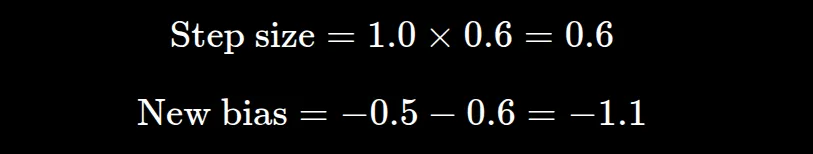
برای توسعهدهندگان، این موضوع ثابت میکند که یادگیری تقویتشده یک جعبه سیاه نیست؛ بلکه مجموعهای از تفریقها و ضربهای کنترلشده است. با تغییر اندازه گام، شما تعیین میکنید مدل با چه سرعتی یک عادت بد را فراموش کند. بنابراین آموزش مدل، بیشتر به «تنظیم اعداد» تبدیل میشود تا «حدس زدن منطق».
گام بعدی شما
- اگر روی مدلهای عاملمحور کار میکنید، نرخ یادگیری را در سناریوهای تنبیهی کاهش دهید تا از نوسانات شدید در رفتار مدل جلوگیری کنید.
- برای درک عمیقتر، مفاهیم مشتق و ضرب در پاداش منفی را در محیطهای شبیهساز ساده پیادهسازی کنید.
- بررسی کنید که آیا پاداشهای منفی در مدل شما باعث «توقف کامل» یادگیری شدهاند یا صرفاً جهت تصمیم را تغییر دادهاند.
برای دیدن واکنش این وزنها به سناریوهای پیچیدهتر، منتظر راهنمای بعدی این مجموعه باشید که آموزش مدلها با ورودیهای متنوع را بررسی میکند.



گفتگو