
عصر فشار آوردن به سختافزار با مدلهای غولآسا به پایان رسیده است. اگر هنوز فکر میکنید برای رسیدن به عملکرد سطح اول فقط به پارامترهای بیشتر نیاز دارید، سخت در اشتباهید.
Poolside AI با معرفی خانواده مدلهای مخلوط متخصصان (Mixture-of-Experts یا MoE)، ثابت کرد که کارایی معماری میتواند با مقیاس خام رقابت کند. به نقل از مستندات فنی poolside.ai، این شرکت دو مدل کلیدی را توسعه داده است: مدل بنیادی Laguna M.1 و مدل با وزنهای باز (Open Weights) به نام Laguna XS.2.

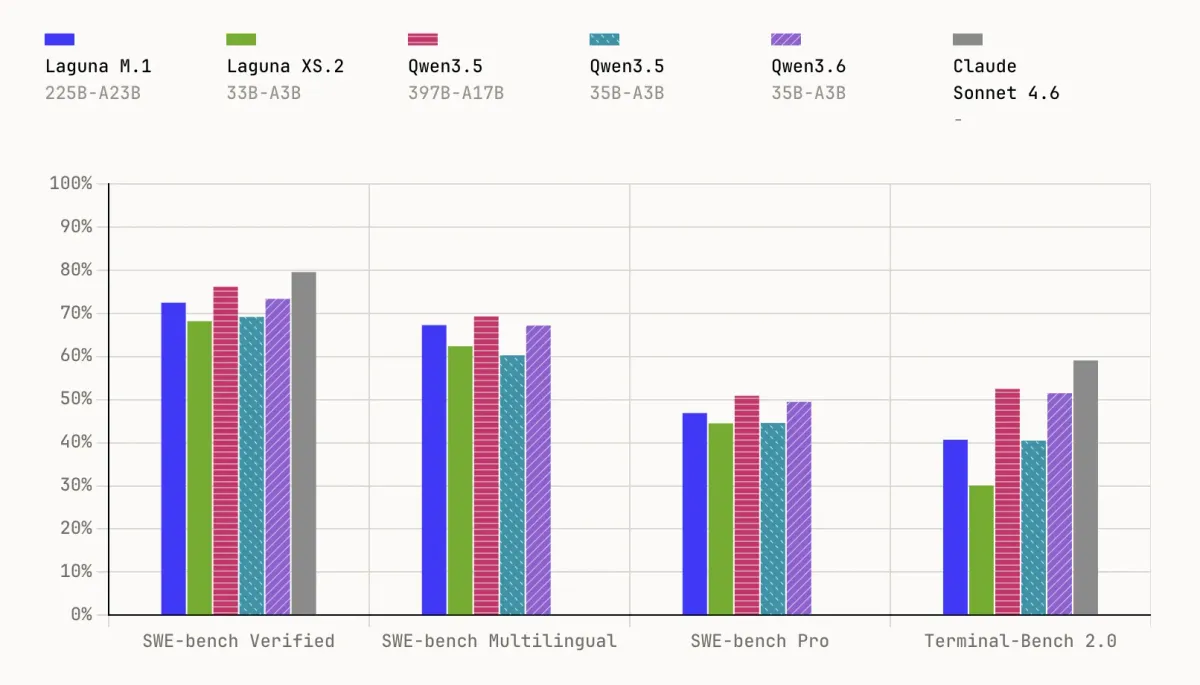
تفاوت عملکردی این دو مدل بهطرز عجیبی اندک است. طبق گزارش marktechpost.com، مدل Laguna M.1 با ۲۲۵ میلیارد پارامتر (۲۳ میلیارد فعال)، به امتیاز ۷۲.۵٪ در بنچمارک SWE-bench Verified دست یافت. در مقابل، مدل کوچکتر Laguna XS.2 با تنها ۳۳ میلیارد پارامتر (۳ میلیارد فعال)، امتیاز ۶۸.۲٪ را کسب کرد. این یعنی XS.2 آنقدر کوچک است که میتوان آن را بهصورت محلی روی یک مک با ۳۶ گیگابایت رم و از طریق Ollama اجرا کرد.
رمز این بهرهوری در سه نوآوری کلیدی در آموزش نهفته است:
- بهینهساز Muon (Muon Optimizer): این بهینهساز توزیعشده با جایگزینی AdamW، گامهای آموزشی را حدود ۱۵٪ کاهش داد و با استفاده از تنها یک وضعیت برای هر پارامتر، نیاز به حافظه را به شدت پایین آورد.
- AutoMixer: بهجای تکیه بر حدس و گمانهای دستی، Poolside از مجموعهای از ۶۰ مدل پروکسی برای بهینهسازی خودکار ترکیب دادههای کد، ریاضی و STEM استفاده کرد.
- یادگیری تقویتشده عاملمحور (Async On-Policy Agent RL): سیستمی پیچیده که در آن استنتاج (Inference) و آموزش بهصورت موازی اجرا میشوند و از GPUDirect RDMA برای انتقال وزنها بهره میبرند.
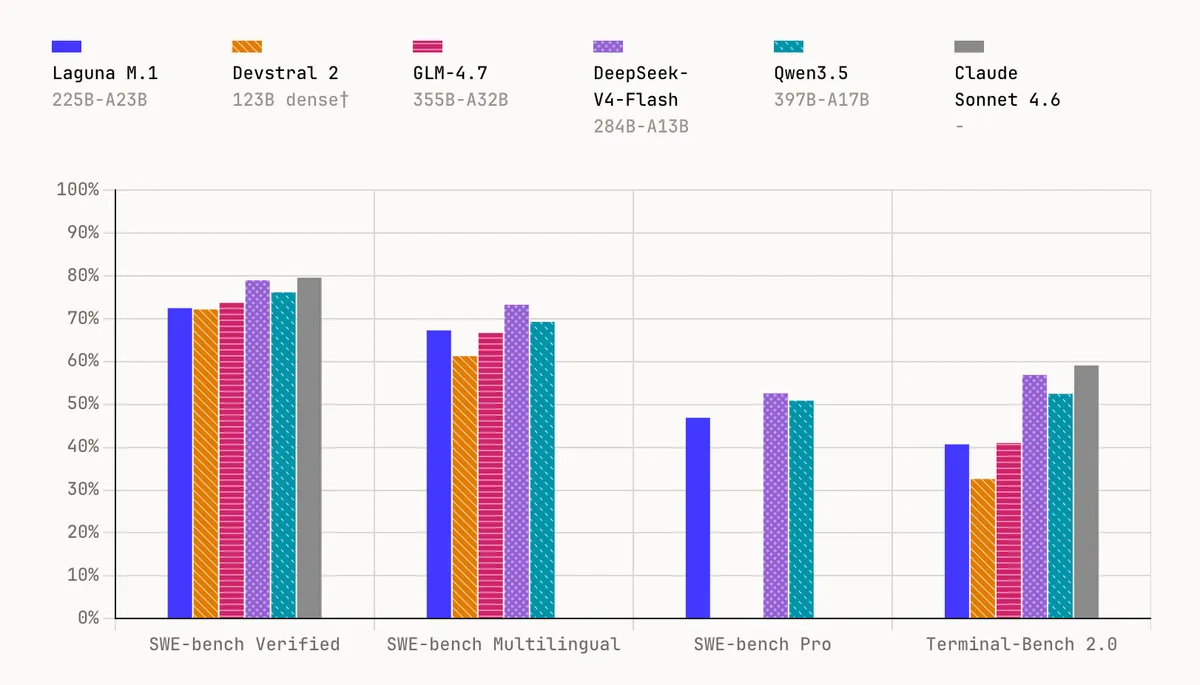
هر دو مدل روی بیش از ۳۰ تریلیون توکن آموزش دیدهاند و پیشآموزش Laguna M.1 در پایان سال ۲۰۲۳ به اتمام رسید. همانطور که در پوشش پیشین ما از چرخش Poolside به سمت مدلهای بازمتن دیدیم، این شرکت به دنبال تغییر قواعد بازی در دسترسی به مدلهای سطح اول است. این مدلها سیگنالی از گذار به کدنویسی عاملمحور (Agentic) هستند؛ جایی که مدلها تفکر و فراخوانی ابزار را برای حل وظایف پیچیده ترکیب میکنند.
این تنها آغاز ماجراست؛ اثر موجگونهی این بهینهسازیها بر اکوسیستم مدلهای زبانی کوچک را در گزارش بعدی بررسی خواهیم کرد.
گام بعدی شما
- مدل Laguna XS.2 را از طریق Ollama روی سختافزار محلی خود تست کنید تا سرعت استنتاج را بسنجید.
- مستندات بهینهساز Muon را مطالعه کنید تا متوجه شوید چگونه میتوان هزینه آموزش را بدون کاهش دقت پایین آورد.
- بر روی قابلیتهای استفاده از ابزار (Tool Use) در مدلهای MoE تمرکز کنید.



گفتگو