
تصور کنید گزارش تولید شده توسط هوش مصنوعی شما، با اطمینان کامل ادعا کند فشار پردازنده ۲٪ است، در حالی که دادههای واقعی عدد ۹۰٪ را نشان میدهند. این شکستِ «پوچی ریاضی» دقیقاً دلیل آن است که ریختن دادههای خام در یک مدل زبانی، یک اشتباه استراتژیک در معماری است.
سیستمهای مانیتورینگ مثل Prometheus، Grafana و Loki حجم عظیمی از دادههای سری زمانی تولید میکنند. مدل زبانی بزرگ (LLM) — مثل کتابخانهداری که میلیاردها صفحه را خوانده و حالا با همان لحن کتابها جواب میدهد — در تفسیر آماری این توالیها ضعیف است. همانطور که در تحلیل قبلی ما دربارهی اتوماسیون یادداشتهای فنی اشاره کردیم، در اینجا با نیاز معکوس روبرو هستیم: قبل از اینکه هوش مصنوعی به دادههای فنی دست بزند، ساختار باید به شدت دقیق باشد.
به نقل از یک توسعهدهنده، در ۱۲ مه ۲۰۲۶ نقشهای برای یک پلتفرم مانیتورینگ خود-میزبان (Self-hosted) منتشر شد. این سیستم برای تولید گزارشهای سلامت ماهانه از یک خط لوله سهمرحلهای استفاده میکند:
- مرحله اول: اسکریپتهای پایتون به جای خروجی خام، آمارهای دقیق مثل میانگین مصرف CPU و نرخ رشد دیسک را محاسبه میکنند.
- مرحله دوم: این یافتهها وارد یک پرامپت ساختاریافته میشوند تا مدل را مجبور کنند «راوی» باشد، نه «تحلیلگر».
- مرحله سوم: هر فراخوانی برای هر سرور و کاربر ایزوله میشود تا نشت دادهها پیش نیاید.
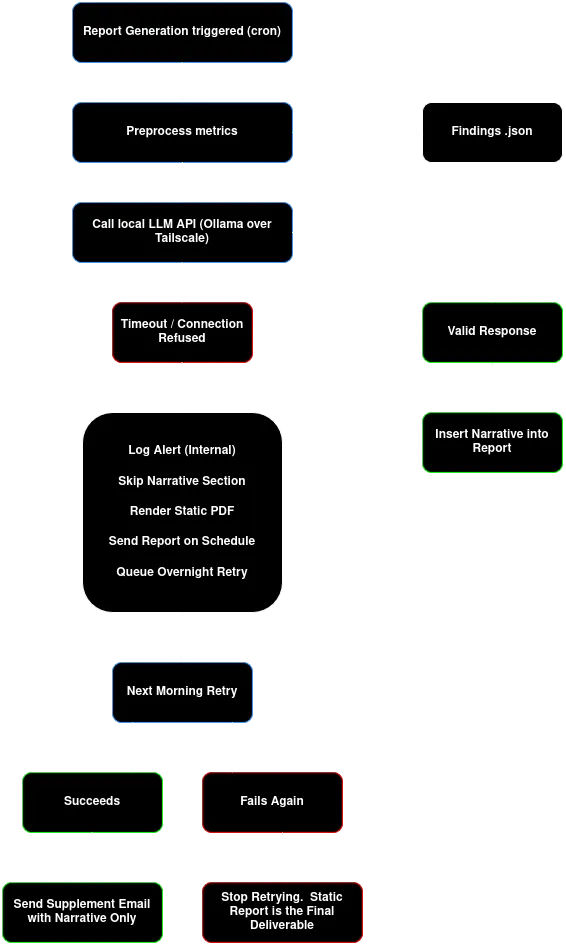
این مدل در شبکه داخلی (LAN) اجرا میشود. بنابراین دادههای حساس هرگز از زیرساخت فیزیکی مالک خارج نمیشوند. در این حالت، استنتاج (Inference) — لحظهای که مدل واقعاً جواب تولید میکند و شبیه خودِ آشپزی است، نه دورهی آموزش آشپز — در محیطی امن صورت میگیرد.
این چرخش از «تحلیلگر AI» به «راوی AI»، یک فرض بنیادی در DevOps را تغییر میدهد. وقتی استدلال در سیستمهای قطعی (Deterministic) باقی بماند و مدل زبانی فقط برای نگارش متن استفاده شود، احتمال توهم (Hallucination) — یعنی وقتی مدل با اطمینان چیزی میگوید که وجود ندارد، مثل دوستی که خاطرهای را اشتباه تعریف میکند — به شدت کاهش مییابد.
گام بعدی شما
- پرامپتهای فعلی خود را بررسی کنید و ببینید آیا از مدل میخواهید «محاسبه» کند یا فقط «توصیف»؟
- برای دادههای حساس، استقرار مدلهای محلی را جایگزین APIهای ابری کنید.
- لایهی پیشپردازش دادهها را از لایهی تولید متن کاملاً جدا کنید.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است؛ اثر این مدلهای محلی بر کاهش هزینههای GPU را در گزارش بعدی بررسی خواهیم کرد.



گفتگو