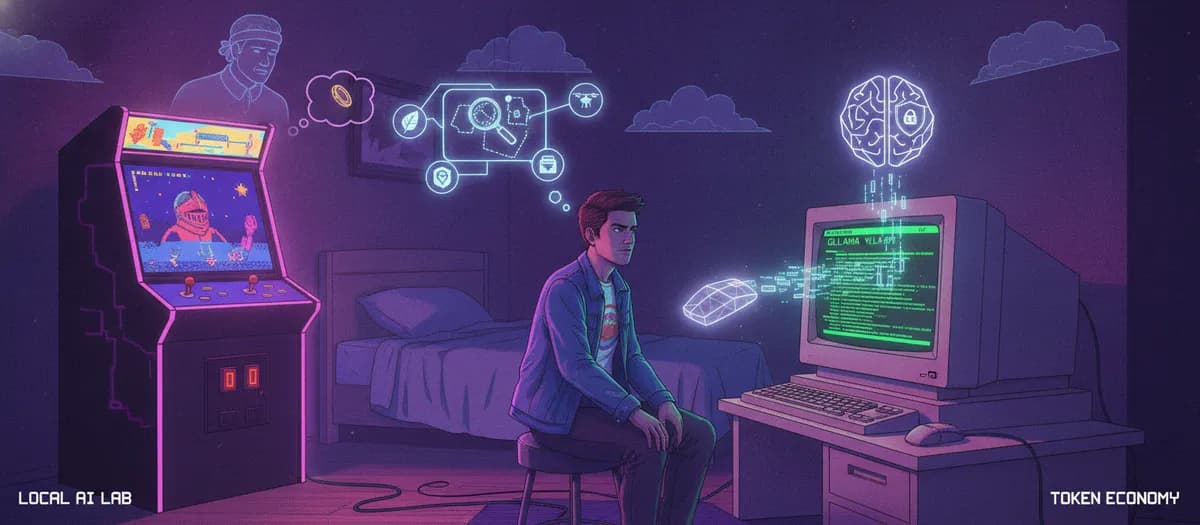
اگر هر روز دهها اسکرینشات از رابطهای کاربری پیچیده را برای تحلیل به مدلهای ابری میفرستید، احتمالاً با بحران «ورشکستگی توکنی» آشنا هستید. طبق تحلیل فنی لوئیس سباستین واسکز (Luis Sebastian Vasquez) در ۲۵ ژوئن ۲۰۲۶، یک اسکرینشات Full HD ساده در مکبوک میتواند ۱۵۴۸ توکن (Token) — تکههای کوچکی از متن، شبیه برشهای یک کیک طولانی که مدل تکهتکه میخورد — را در مدلهایی مثل Claude مصرف کند. برای توسعهدهندگانی که برای یادگیری رابطهای کاربری پیچیده به پرسوجوهای بصری متکی هستند، این هزینهها بهسرعت سقف محدودیتهای ساعتی را پر کرده و روند تولید کد را متوقف میکند.
این «ورشکستگی توکنی» به یکی از نقاط اصطکاک اصلی برای مهندسانانی تبدیل شده است که از ابزارهای عاملمحور (Agentic) مانند Claude Code، Codex یا Gemini CLI استفاده میکنند. همانطور که در تحلیلهای پیشین ما دربارهی بهینهسازی هزینههای استنتاج اشاره کردیم، مهندسی پرامپت میتواند سربار متنی را کاهش دهد، اما وظایف مبتنی بر بینایی در ابر همچنان بهطرز بازدارندهای گران هستند. در واقع، این چالش منجر به شکلگیری روشهای جدیدی شده است، مانند استراتژی توکنمینینگ برای کاهش چشمگیر هزینههای استنتاج که بر بهینهسازی مصرف توکنها تمرکز دارد. برای حل این مشکل، واسکز گردش کار خود را از APIهای ابری به یک آزمایشگاه AI محلی (Homelab) منتقل کرد.
به نقل از مستندات واسکز، او یک کامپیوتر گیمینگ را با سیستمعامل Pop!_OS و یک کارت گرافیک NVIDIA RTX 4070 با ۱۲ گیگابایت حافظه ویدیویی (VRAM) بازسازی کرد. به دلیل اینکه ۱۲ گیگابایت برای مدلهای مدرن AI یک گلوگاه تنگ محسوب میشود، او بهجای اندازه مدل، روی بهرهوری شدید تمرکز کرد. او برای مدیریت امن سرور از Tailscale و برای سازماندهی مدلها از Ollama و llama.cpp بهره برد.
مرکز این معماری، مدل بینایی-زبانی (VLM) qwen2.5-vl:7b است. این مدل — شبیه انسانی که همزمان متن، عکس و صدا را میفهمد — برخلاف سیستمهای قدیمی نویسهخوانی نوری (OCR) که فقط متن خام را استخراج میکنند، معنا و جایگاه فضایی (Spatial context) اجزا در یک رابط کاربری را درک میکند.
خط لوله (Pipeline) این سیستم بهصورت زیر است:
- ورودی: آپلود تصویر از طریق مرورگر (درخواست POST با فرمت base64).
- پردازش: یک سرور Flask روی پورت ۵۰۰۰ تصویر را به Ollama میفرستد.
- استنتاج (Inference) — لحظهای که مدل واقعاً جواب تولید میکند، شبیه خودِ آشپزی و نه دوره آموزش آشپزی — توسط مدل qwen2.5-vl:7b روی GPU محلی انجام میشود.
- خروجی: متن استخراجشده برای تفسیر به یک عامل (Agent) دیگر ارسال میشود.
بر اساس گزارش واسکز، این فرآیند پاسخ را در حدود ۸ ثانیه بازمیگرداند. در حالی که تمام دادهها در شبکه محلی میمانند و حریم خصوصی کامل تضمین شده و هزینه هر تصویر صفر است.
این رویکرد نشاندهنده ترند رو به رشد «حاکمیت محاسباتی» (Compute Sovereignty) برای توسعهدهندگان است. با انتقال کارهای حجیم اما کم-استدلال (مثل استخراج بصری) به یک مدل محلی ۷ میلیارد پارامتری، کاربران میتوانند توکنهای گرانقیمت ابری را برای وظایف با استدلال بالا، مانند کدنویسی معماریهای پیچیده، ذخیره کنند. این تفکیک دقیق نقشها میان مدلهای محلی و ابری، مشابه رویکرد معماری هیبریدی gas-fakes است که برای کاهش هزینههای توکن Gemini پیاده شده است.
برای کسانی که VRAM محدودی دارند، این راهکار ثابت میکند که یک مدل ۷ میلیاردی برای تحلیل رابطهای کاربری کافی است. نویسنده در حال حاضر در حال گسترش این اکوسیستم محلی برای پردازش تصاویر پهپادی در یک پروژه شناسایی گیاهان کشاورزی است. توسعهدهندگان علاقهمند میتوانند از طریق مخزن VLM Local Parser این پیادهسازی را بررسی کنند تا دیگر برای «دیدن» صفحه نمایش خود به ارائهدهندگان ابری هزینه نپردازند.
گام بعدی شما
- بررسی مخزن VLM Local Parser در گیتهاب برای پیادهسازی مشابه.
- تست مدلهای ۷ میلیاردی روی سختافزارهای با VRAM محدود (۱۲ گیگابایت).
- جداسازی وظایف «بینایی محلی» و «استدلال ابری» برای کاهش هزینهها.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است؛ برای درک اینکه چگونه مدلهای کوچکتر در حال بلعیدن غولهای ابری هستند، به تحلیل ما دربارهی مدلهای زبانی کوچک مراجعه کنید.



گفتگو