
تصور کنید ساعت ۲ بامداد است، سرورها سقوط کردهاند و شما تنها مهندسی هستید که باید در حالی که فشار هزاران دلار ضرر در هر دقیقه را حس میکنید، راه حل را پیدا کنید. در این لحظه، تفاوت بین یک بازگشت سریع به حالت عادی و ساعتها سردرگمی، داشتن دسترسی به «حافظهٔ جمعی» تیم است.
RecallOps یک عامل (Agent) — شبیه به دستیاری که تمام سوابق شرکت را حفظ است و دقیقاً میداند کدام پیچ را در کدام سال باید چرخاند — است که توسط یک تیم دو نفره در یک هکاتون ساخته شده است. این ابزار برای حذف آن ۴۵ دقیقه زمان تلفشده در جستوجوی فایلهای راهنمای قدیمی و رشتهگفتارهای پراکنده در Slack طراحی شده است. به جای اینکه نیروی آنکال (On-call) مجبور باشد در میان پیامهای سال گذشته بگردد، این ابزار فوراً راهکارهای موفق از حوادث مشابه قبلی را بازیابی میکند.
پاسخ به حوادث فنی محیطی است که در آن استرس به اوج میرسد و هر دقیقه توقف سرویس، هزینههای سنگینی دارد. طبق گزارش توسعهدهندگان، اکثر تیمهای مهندسی دانش لازم برای رفع یک باگ تکراری را دارند، اما این اطلاعات در پلتفرمهای مختلف پراکنده است. RecallOps به عنوان یک راهکار تخصصی برای پر کردن این شکاف وارد شده است تا با اعطای یک حافظه سازمانی پایدار به یک عامل هوش مصنوعی، دسترسی به دانش را تسهیل کند. این تلاش برای تثبیت حافظه در عوامل هوش مصنوعی، یادآور رویکردهای نوآورانهای است که در پروژه Lorekeeper برای کاهش فراموشی حافظه در عاملها از طریق چرخههای بازاندیشی به کار گرفته شد.
همانطور که در تحلیلهای قبلی ما دربارهی تولید بازیابیافزا (RAG) اشاره کردیم، قدرت مدلهای زبانی زمانی افزایش مییابد که به دادههای خارجی و بهروز دسترسی داشته باشند؛ RecallOps را میتوان پیادهسازی عملی این مفهوم در مدیریت بحران دانست.
بستر مشکل
تیمهای مهندسی اغلب در چرخه تکراری شکستها گرفتار میشوند. وقتی در ساعت ۲ بامداد هشدار خطا صادر میشود، مهندس آنکال باید در میان رشتهگفتارهای قدیمی Slack یا دفترچههای راهنمایی (Runbooks) که ماههاست بهروزرسانی نشدهاند، جستوجو کند. آنها به شدت در تلاش هستند تا به یاد آورند آیا یک خطای خاص قبلاً رخ داده است یا خیر. تا زمانی که پاسخ پیدا شود، اغلب خسارات حیاتی به سیستم وارد شده است.
RecallOps این مشکل را با حصول اطمینان از اینکه هر حادثه ذخیره شود و هر راهکار بهخاطر سپرده شود، حل میکند. هدف سازندگان این بود که یک ابزار واقعی بسازند که مهندسان در لحظه بحران واقعاً بخواهند از آن استفاده کنند، نه یک اسباببازی یا یک دموی شکننده.
معماری سه پنله
توسعهدهندگان برای بصری کردن این حافظه و کاربردی کردن آن، یک رابط کاربری خاص با React، Vite و CSS خالص طراحی کردند. آنها از کتابخانههای سنگین UI اجتناب کردند تا رابط کاربری سبک باقی بماند. ساختار این رابط از یک چیدمان سه پنله تشکیل شده است:
- پنل چپ: یک رابط چت آشنا که مهندسان لاگهای خطا را در آن قرار میدهند.
- پنل مرکزی: پاسخ فعال هوش مصنوعی که حاوی توصیههای دقیق برای رفع مشکل است.
- پنل راست: یک پنل اختصاصی زمینه (Context) که حوادث مشابه گذشته را از حافظه بیرون میکشد.
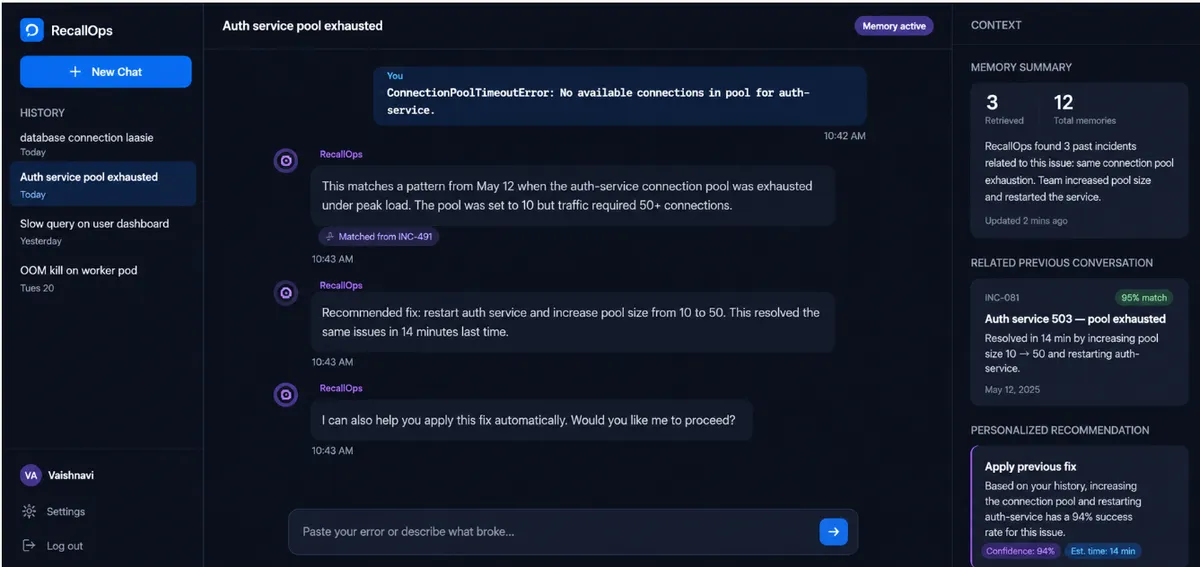
این چیدمان باعث میشود ویژگی حافظه غیرقابل چشمپوشی باشد. ارتباط بین «اتفاق فعلی» و «تجربه قبلی» کاملاً بصری و فوری رندر میشود.
بصریسازی لایه حافظه
پنل راست، گواه بصری دانش سازمانی این عامل است. اینجاست که لایه حافظه Hindsight برای کاربر قابل مشاهده میشود. زمانی که یک خطا وارد میشود، این بخش با اطلاعات زیر بهروز میشود:
- خلاصه حافظه: جزئیاتی درباره تعداد کل حوادث ذخیرهشده و تعداد مواردی که با پرسوجوی فعلی مرتبط هستند.
- گفتوگوهای مرتبط پیشین: مشابهترین حادثه گذشته، شامل امتیاز تطابق (Match Score)، تاریخ و خلاصه روش حل مسئله.
- پیشنهاد شخصیسازیشده: یک راهکار دقیق پیشنهادی همراه با سطح اطمینان و زمان تخمینی برای رفع مشکل.
وجود نشان «حافظه فعال» (Memory active) در سرصفحه تأیید میکند که عامل بهجای تکیه بر دادههای عمومی آموزش، از تاریخچه و دانش درونسازمانی استفاده میکند.
گردشکار فنی و استک ابزارها
به نقل از گزارشی در وبسایت dev.to که در ۲۸ ژوئن ۲۰۲۶ منتشر شد، این ابزار برای کاهش تأخیر و پایین نگه داشتن زمان پاسخدهی، از چندین فناوری پرسرعت استفاده میکند. فرانتاند از طریق یک فایل مدیریت وضعیت مرکزی به نام AppContext.jsx به بکاند FastAPI متصل میشود. این فایل تابع sendMessage را مدیریت میکند که فراخوانیهای واقعی fetch را به آدرس http://localhost:8000/api/query ارسال میکند.
مکانیزم حافظه
این سامانه طبق یک توالی دقیق عمل میکند:
- عامل ابتدا در میان ۳۰ حادثه ذخیرهشده در حافظه Hindsight جستوجو میکند.
- از cascadeflow برای انتخاب بهینهترین مدل هوش مصنوعی برای آن وظیفه استفاده میکند.
- برای استنتاج (Inference) سریع — لحظهای که مدل واقعاً جواب تولید میکند — از Groq کمک میگیرد تا پاسخها با سرعت بالا بازگردند.
- در نهایت، سیستم توصیه رفع خطا، حوادث مشابه، مدل استفادهشده و هزینه عملیات را بازمیگرداند.
کل این چرخه، از لحظه چسباندن متن خطا تا دریافت راهکار بر اساس دادههای واقعی تاریخی، تقریباً ۳ ثانیه زمان میبرد.
استراتژی توسعه
توسعهدهندگان از استراتژی «ابتدا دادههای ساختگی» (Mock data first) استفاده کردند. در روز اول، آنها رابط کاربری را با پاسخهای سختافزاری (Hardcoded) ساختند و استایلدهی کردند؛ این کار به آنها اجازه داد تا بدون اینکه توسط توسعه بکاند متوقف شوند، روی طراحی تکرار و بهبود دهند. در روز دوم، دادههای ساختگی را با فراخوانیهای واقعی API جایگزین کردند. این انتقال کمتر از یک ساعت زمان برد زیرا رابط کاربری از پیش برای ساختار دادهها آماده شده بود.
تجربه کاربر در سناریوهای پراسترس
تیم توسعه تعمداً از تم تیره استفاده کرد، زیرا پاسخ به حوادث معمولاً شبها رخ میدهد. برای مهندسانی که در ساعت ۲ بامداد تحت استرس شدید کار میکنند، یک صفحه سفید خیرهکننده یک مانع است؛ بنابراین حالت تیره یک ضرورت است، نه یک ترجیح ساده.
برای کاهش اضطراب، مکانیسمهای بازخورد دقیقی در چت قرار دادند:
- نشانگرهای تایپ: بهجای یک دایره چرخان (Spinner) ساده، کاربر پیامهای وضعیتی مانند «در حال جستوجوی تاریخچه حوادث...» و سپس «تطابق یافت شد — در حال پیشنویس راهکار» را میبیند.
- پرامپتهای پیشنهادی: برای جلوگیری از مشکل «ورودی خالی»، در حالت خالی، مثالهای پیشفرض مانند «ConnectionPoolTimeoutError در سرویس احراز هویت» با برچسب «۹۴٪ تطابق» نمایش داده میشوند.
این رویکرد، نقش هوش مصنوعی را از یک چتبات عمومی به ابزاری تخصصی تبدیل میکند که وضعیت مشترک (Shared State) را در یک رابط پیچیده مدیریت میکند. با استفاده از React Context، تیم اطمینان حاصل کرد که پنلهای مرکزی و راست بهطور همزمان با پرسوجوی کاربر بهروز میشوند.
برای هر مهندس، این یعنی تفاوت بین خیره شدن به یک صفحه خالی و دیدن یک مسیر concrete (ملموس) برای حل مشکل. این ابزار، حافظه سازمانی را از یک دارایی پنهان به یک پرامپت آنی برای هوش مصنوعی تبدیل میکند.
نقشه راه آینده
RecallOps به عنوان یک پروژه هکاتون شروع شد، اما بازار ابزارهای پاسخ به حوادث بسیار گسترده است. نسخههای آینده قصد دارند قابلیتهای خود را از طریق موارد زیر گسترش دهند:
- جذب خودکار دادهها: استخراج مستقیم اطلاعات حوادث از PagerDuty و Slack.
- تولید خودکار گزارش پسازحادثه (Postmortem): ابزاری که گزارشهای تحلیل شکست را بهطور خودکار بر اساس دادههای حوادث گذشته مینویسد.
- تحلیلهای تیمی: داشبوردهایی که نشان میدهد کدام سیستمها مکرراً شکست میخورند و کدام راهکارها بالاترین نرخ موفقیت را دارند.
باید منتظر انتقال این پروژه از یک دموی هکاتون به یک ابزار در سطح تولید (Production-grade) باشیم، در حالی که تلاش میکند با استکهای گستردهترِ مشاهدهپذیری (Observability) یکپارچه شود.
گام بعدی شما
- اگر مدیر فنی هستید، بررسی کنید که آیا دانش رفع خطاهای تیم شما در Slack دفن شده است یا در یک پایگاه دانش متمرکز قرار دارد.
- برای پیادهسازی حافظه سازمانی، ساختار «سه پنله» (درخواست، پاسخ، زمینه) را در ابزارهای داخلی خود امتحان کنید تا اعتماد کاربر به پاسخ AI جلب شود.
- ابزارهایی مانند Groq را برای کاهش زمان پاسخدهی در سیستمهای حساس بررسی کنید.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو