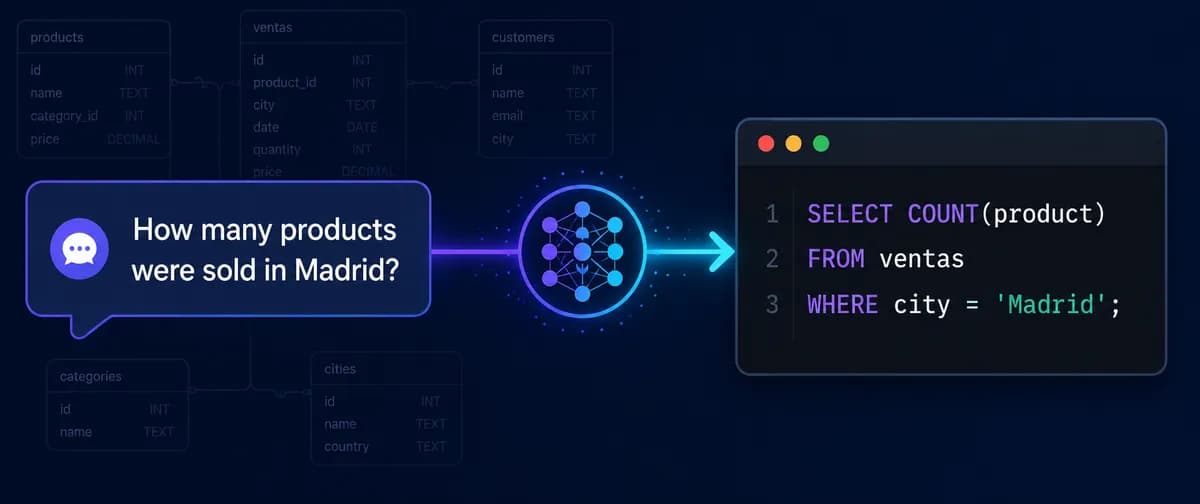
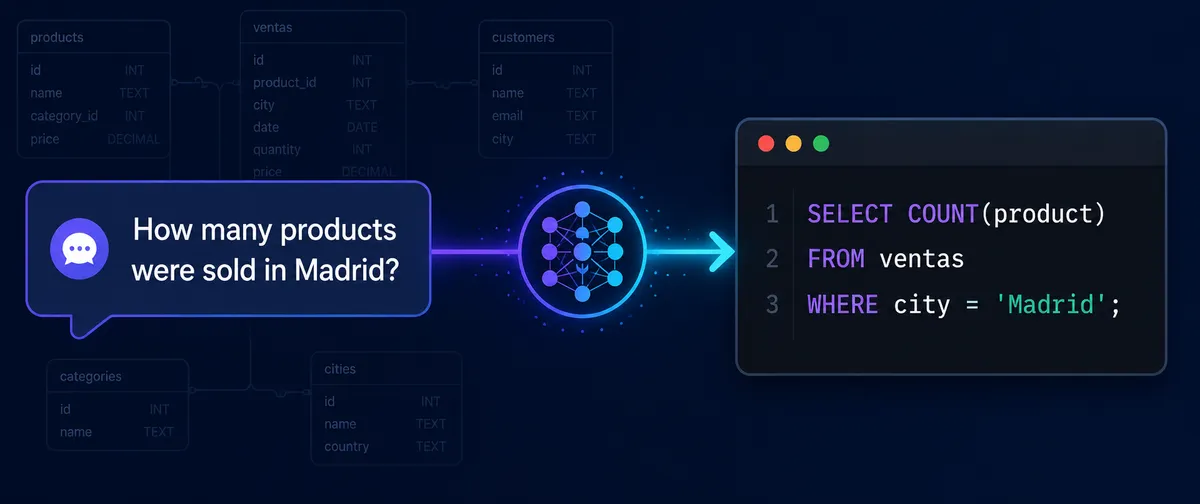
اگر امروز میخواهید دادههای شرکتتان را بدون نوشتن حتی یک خط کد استخراج کنید، امنیت سیستم شما تنها به یک لایهٔ اعتبارسنجی وابسته است. طبق مستندات منتشرشده از یک توسعهدهنده، رابطهای تبدیل متن به SQL (Text-to-SQL) بدون وجود یک خط لوله (Pipeline) نظارتی، درگاههای باز برای حملات سایبری و خطاهای مهلک هستند. برای اثبات این موضوع، یک توسعهدهنده پیادهسازی کاملی از یک رابط زبان طبیعی به SQL را به اشتراک گذاشته است که از مدل T5-base-finetuned-wikiSQL بهره میبرد.
برای اکثر مدیران کسبوکار، زبان SQL — که مانند یک دستورالعمل دقیق برای صحبت با بایگانیهای دیجیتال است — سدی بزرگ در برابر استقلال دادهای است. حتی یک درخواست ساده گاهی نیازمند دستورات پیچیده JOIN یا سینتکسهای خاصی است که بهرهوری را متوقف میکند. همین شکاف باعث رشد مدلهای زبانی بزرگ (LLM) شد تا پرسشهای انگلیسی را به کوئریهای قابل اجرا تبدیل کنند. اگرچه بسیاری از آموزشهای آنلاین تنها مثالهای ساده یا «اسباببازی» (Toy examples) را نشان میدهند، اما دادههای دنیای واقعی نامنظم هستند و اجرای کورکورانه آنها بسیار خطرناک است.
معماری هسته سیستم
این سیستم از یک خط لوله خطی برای تضمین دقت و ایمنی استفاده میکند. فرآیند به این ترتیب است:
- ورودی: یک پرسش به زبان انگلیسی که توسط کاربر ارائه میشود.
- مدل: مدل T5 (از طریق Hugging Face) یک رشته SQL «خام» تولید میکند.
- پردازش: یک لایه سازگارساز (Adaptation layer) نام جداول را اصلاح کرده و برای مقادیر، کوتیشن اضافه میکند.
- اعتبارسنجی: یک لایه امنیتی تضمین میکند که تنها دستورات
SELECTمجاز باشند. - اجرا: کوئری در حالت «فقط خواندنی» روی یک پایگاهداده SQLite اجرا میشود.
- خروجی: نتیجه بهصورت یک جدول (Tabular result) به کاربر نمایش داده میشود.
برای شبیهسازی یک سناریوی واقعی، این پیادهسازی از جدولی به نام ventas (فروش) استفاده میکند. طرح (Schema) پایگاهداده به شرح زیر تعریف شده است:
CREATE TABLE ventas (
id INTEGER PRIMARY KEY,
product TEXT NOT NULL,
category TEXT NOT NULL,
price REAL NOT NULL,
quantity INTEGER NOT NULL,
city TEXT NOT NULL,
customer TEXT NOT NULL,
sale_date TEXT NOT NULL
)
تحلیل مدل: Hugging Face و T5
نویسنده از مدل mrm8488/t5-base-finetuned-wikiSQL بهره برده که بهطور خاص روی مجموعه داده WikiSQL آموزش دیده است. در این پیادهسازی از کلاسهای T5ForConditionalGeneration و T5Tokenizer از کتابخانه transformers استفاده شده است.
مکانیسم داخلی مدل بر اساس یک فرمت پرامپت خاص عمل میکند: translate English to SQL: {question} </s>. برای مثال، برای پرسشی مانند «چند محصول در مادرید فروخته شد؟»، مدل خروجی خامی شبیه به این تولید میکند: SELECT COUNT(product) FROM table WHERE city = Madrid.
حل شکاف طرح (Schema Gap)
به گزارش توسعهدهنده، در هنگام تست با پرسشهای واقعی، سه شکست بحرانی شناسایی شد که در آموزشهای سادهشده دیده نمیشوند. اول، مدلها اغلب پرانتزهای توابع تجمیعی را حذف میکنند؛ مثلاً بهجای نوشتن SELECT COUNT(Product) FROM table عبارت SELECT COUNT Product FROM table را تولید میکنند.
دوم، مدل از جزئیات دقیق طرح پایگاهداده آگاه نیست. چون WikiSQL روی هزاران جدول مختلف آموزش دیده، مدل بر اساس پرسش، نام ستونهای «محتمل» را اختراع میکند. برای مثال، ستون city ممکن است بسته به پرامپت، به صورت City یا Location تولید شود.
سوم، حساسیت به حروف کوچک و بزرگ باعث «شکستهای خاموش» میشود. اگر پایگاهداده مقدار را به صورت Barcelona ذخیره کرده باشد، کوئری برای city = barcelona (با حروف کوچک) هیچ ردیفی را برنمیگرداند. این خطرناکترین نوع خطا است زیرا کوئری با موفقیت اجرا میشود اما نتایج نادرست ارائه میدهد.
لایه پاکسازی (Sanitization Layer)
اجرای مستقیم کدهای تولیدشده توسط هوش مصنوعی یک ریسک امنیتی است. توسعهدهنده ماژول sanitize.py را پیاده کرد که چهار اقدام مشخص برای پل زدن بین LLM و پایگاهداده واقعی انجام میدهد:
- ترمیم پرانتزها: یک عبارت منظم (
_AGG_NO_PARENS) پرانتزهای گمشده در توابعCOUNT،SUM،AVG،MINوMAXرا شناسایی کرده و پیش از اجرا آنها را اصلاح میکند. - نگاشت طرح: چون مدل طرح واقعی را نمیبیند، یک دیکشنری به نام
COLUMN_SYNONYMSکلمات مبهم را به ستونهای واقعی مینگارد. برای مثال:item$
ightarrow$productcostیاamount$
ightarrow$priceqty$
ightarrow$quantitylocationیاtown$
ightarrow$cityclientیاbuyer$
ightarrow$customersalesیاsale$
ightarrow$*(تبدیل «تعداد فروشها» بهCOUNT(*)).
- کوتیشنگذاری مقادیر: سیستم بهطور خودکار تککوتیشن را به مقادیر متنی اضافه میکند تا عبارت
city = Madridبه صورت استانداردcity = 'Madrid'درآید. - نرمالسازی: نامهای عمومی جدول مانند
table(که استاندارد آموزش WikiSQL است) با نام واقعی جدول یعنیventasجایگزین میشوند.
برای رفع مشکل حروف کوچک و بزرگ، سیستم از تابع _case_insensitive_compare استفاده میکند. این تابع هر دو طرف معادله را در تابع LOWER() قرار میدهد: LOWER(city) = LOWER('Madrid').
امنیت و اعتبارسنجی
برای جلوگیری از تزریق SQL (SQL Injection) یا دستورات تخریبی، تابع validate_select_only تضمین میکند که هر کوئری حتماً با کلمه کلیدی SELECT آغاز شود. هر کوئری که با SELECT شروع نشود، خطای UnsafeQueryError را ایجاد میکند.
سیستم از یک لیست سیاه سختگیرانه (FORBIDDEN_KEYWORDS) برای مسدود کردن کلماتی نظیر INSERT ،UPDATE ،DELETE ،DROP ،ALTER ،ATTACH ،DETACH ،PRAGMA ،CREATE ،REPLACE و VACUUM استفاده میکند. علاوه بر این، وجود نقطه-کاما (;) ممنوع است تا از اجرای چندین دستور در یک فراخوانی واحد جلوگیری شود.
به عنوان آخرین لایه حفاظتی، اتصال SQLite در حالت «فقط خواندنی» با استفاده از URI file:ventas.db?mode=ro باز میشود. این کار تضمین میکند که حتی اگر یک کوئری مخرب از تمام اعتبارسنجهای نرمافزاری عبور کند، محدودیتهای فیزیکی اتصال به پایگاهداده مانع از هرگونه تغییر در دادهها شود.
تبدیل ترمینال به دمو وب
کل این موتور در یک رابط وب Streamlit با کمتر از ۳۰ خط کد بستهبندی شده است. این رابط به کاربران اجازه میدهد پرسش انگلیسی را وارد کنند، کد SQL تولیدشده را از طریق st.code() مشاهده کرده و نتایج را در یک DataFrame بهصورت لحظهای با st.dataframe() ببینند.
عملکرد و محدودیتها
با استفاده از یک مجموعه داده مصنوعی ۱۲۰ سطری، سیستم با موفقیت پرسشهایی نظیر موارد زیر را مدیریت میکند:
- "how many products were sold in city Madrid" $
ightarrow$SELECT COUNT(product) FROM ventas WHERE LOWER(city) = LOWER('Madrid') - "how many sale in category Phones" $
ightarrow$SELECT COUNT(*) FROM ventas WHERE LOWER(category) = LOWER('Phones') - "what is the customer where product is Smartwatch" $
ightarrow$SELECT customer FROM ventas WHERE LOWER(product) = LOWER('Smartwatch')
با وجود این موفقیتها، چندین محدودیت سخت باقی مانده است:
۱. محدودیتهای واژگانی: اگر کاربر کلمهای به کار ببرد که در دیکشنری COLUMN_SYNONYMS نباشد، کوئری ممکن است شکست بخورد.
۲. پیچیدگی: مدل نمیتواند کوئریهای نیازمند چندین جدول یا زیر-کوئریها (Subqueries) را مدیریت کند، زیرا WikiSQL فقط روی مثالهای تکجدولی آموزش دیده است.
۳. زبان: مدل فقط انگلیسی است. ورودیهای اسپانیایی یا زبانهای دیگر نیازمند یک مرحله ترجمه خودکار پیش از پردازش هستند.
این پیادهسازی ثابت میکند که یک نمونه اولیه برای «صحبت با دادهها» را میتوان با حدود ۱۰۰ خط پایتون ساخت. چالش اصلی نه تولید خودِ SQL، بلکه تعریف یک لایه اعتبارسنجی سختگیرانه است تا توهم (Hallucination) — یعنی وقتی مدل با اطمینان چیزی را میگوید که وجود ندارد — منجر به دستورات تخریبی نشود.
توسعهدهندگان میتوانند کد منبع کامل را در گیتهاب به آدرس https://github.com/JhonyVargas/text-to-sql-ia بیابند.
گام بعدی شما
- کد منبع این پروژه را در گیتهاب بررسی کنید تا با ساختار لایهی
sanitize.pyآشنا شوید. - اگر از مدلهای بزرگتر مثل GPT-4 استفاده میکنید، همین لایههای اعتبارسنجی را برای جلوگیری از تزریق SQL در اپلیکیشن خود پیاده کنید.
- سعی کنید لیست
COLUMN_SYNONYMSرا بر اساس دامین تخصصی کسبوکار خود گسترش دهید.
اما داستان سختافزاری اجرای این مدلها در لبهٔ شبکه حتی شگفتانگیزتر است — به تحلیل ما دربارهی رایانش لبه مراجعه کنید.



گفتگو