
اگر خط لولهی دادههای شما در برابر میلیونها ردیف اطلاعات خفه میشود، در رقابت برای رسیدن به هوش مصنوعی آنی شکست خوردهاید. Forge-Core v4.3 اکنون با ادغام اعتبارسنجی و تحلیل در یک گذر واحد، بیش از ۵۰ میلیون ردیف را در ثانیه پردازش میکند.
بسیاری از سیستمهای درونریزی داده، چرخههای CPU را با پردازشهای تکراری و گرانقیمت تلف میکنند. این وضعیت باعث ایجاد یک «دیوار حافظه» میشود؛ جایی که بافرهای استاندارد ورودی-خروجی، پیش از آنکه CPU حتی به دادهها دست بزند، سرعت انتقال را میکُشند. در مسیر ساخت عاملهای هوش مصنوعی (AI Agents) — سیستمهایی شبیه دستیاران هوشمندی که میتوانند مستقلاً ابزارها را اجرا کنند — بزرگترین گلوگاه، پل ارتباطی بین دادههای سطح پایین و محیطهای پایتون است.
همانطور که در تحلیلهای قبلی ما دربارهی بهینهسازی لایههای انتقال داده اشاره کردیم، حذف کپیهای متوالی کلید موفقیت است. طبق گزارش dev.to، توسعهدهنده این موتور در ۱۴ مه ۲۰۲۶ با پیادهسازی چند بهینهسازی کلیدی به این رکورد رسید:
- استفاده از mmap برای درونریزی بدون کپی (Zero-copy) — مثل این است که کتابی را مستقیماً به دست خواننده بدهید، به جای اینکه ابتدا یک نسخه از آن بگیرید و بعد کپی را تحویل دهید.
- بهکارگیری دستورات AVX2 برای پردازش دادهها در قطعات ۳۲ بایتی از طریق SIMD (پردازش یک دستور برای چندین داده) — شبیه آشپزی است که با یک ضربهٔ چاقوی بزرگ، ده عدد هویج را همزمان خرد میکند، نه یکییکی.
- طراحی یک سازماندهنده چندرشتهای با استفاده از pthreads برای کاهش تأخیر در همگامسازی.
- استخراج آماری مسیرهای سریع (Hot-path) برای واریانس و انحراف معیار مستقیماً در حافظهی کش L1/L2.

این موتور اکنون سیگنالها را در قالب قراردادهای JSON قابل خواندن توسط ماشین سریالسازی میکند. به نقل از مستندات فنی، این قابلیت به عاملهای پایتونی اجازه میدهد دادههای موتور C را بهصورت آنی مصرف کنند، بدون آنکه نیاز به یک مرحلهی تحلیل مجدد باشد.
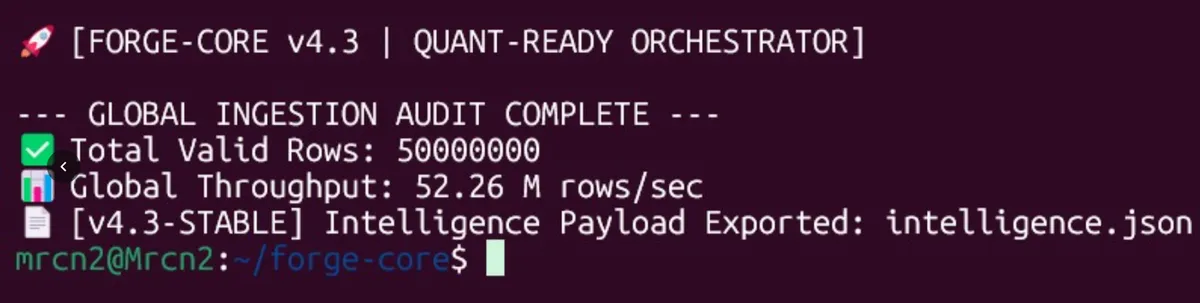
این تغییر، گلوگاه را از CPU به لایهی سازماندهی منتقل میکند و ثابت میکند تحلیلهای «مسیر سریع» میتوانند درست در لحظهی ورود دادهها رخ دهند. برای توسعهدهندگان، این یعنی عاملهای هوش مصنوعی میتوانند بدون تأخیرهای معمولِ پارس کردن در پایتون، روی جریانهای داده با دقت سطح مالی تصمیم بگیرند.
گام بعدی شما
- نرخ انتقال داده در سیستم فعلی خود را اندازهگیری کنید تا متوجه شوید آیا با «دیوار حافظه» مواجه هستید یا خیر.
- اگر از پایتون برای تحلیل دادههای حجیم استفاده میکنید، بررسی دستورات AVX2 برای تسریع پردازشها را در اولویت قرار دهید.
- معماریهای Zero-copy را برای کاهش سربار انتقال داده بین Kernel و User-space مطالعه کنید.
اما داستان سختافزاری این تحولات حتی شگفتانگیزتر است؛ برای درک چگونگی تعامل این موتورها با حافظههای نسل جدید، به تحلیل ما دربارهی معماریهای حافظهی یکپارچه مراجعه کنید.



گفتگو