تصور کنید به جای پرداخت هزاران دلار برای هر بار بهینهسازی یک کد، بتوانید با هزینهای ناچیز و در هر شب، الگوریتمهای سازمان خود را با سختافزار و ترافیک واقعی بهروز کنید. این دقیقاً همان چیزی است که LEVI در حوزهٔ پژوهشهای سیستمیِ مبتنی بر هوش مصنوعی (ADRS) ممکن کرده است. اکتشاف الگوریتمی با عملکرد بالا دیگر یک کالای لوکس نیست که فقط در اختیار کسانی با بودجههای عظیم باشد. طبق اعلام توسعهدهندگان، LEVI توانسته است عملکردهای پیشرو (SOTA) را در مسائل ADRS حفظ کند، در حالی که هزینههای عملیاتی را در مقایسه با خطبندیهای (Baselines) موجود، تقریباً ۳ تا ۷ برابر کاهش داده است.
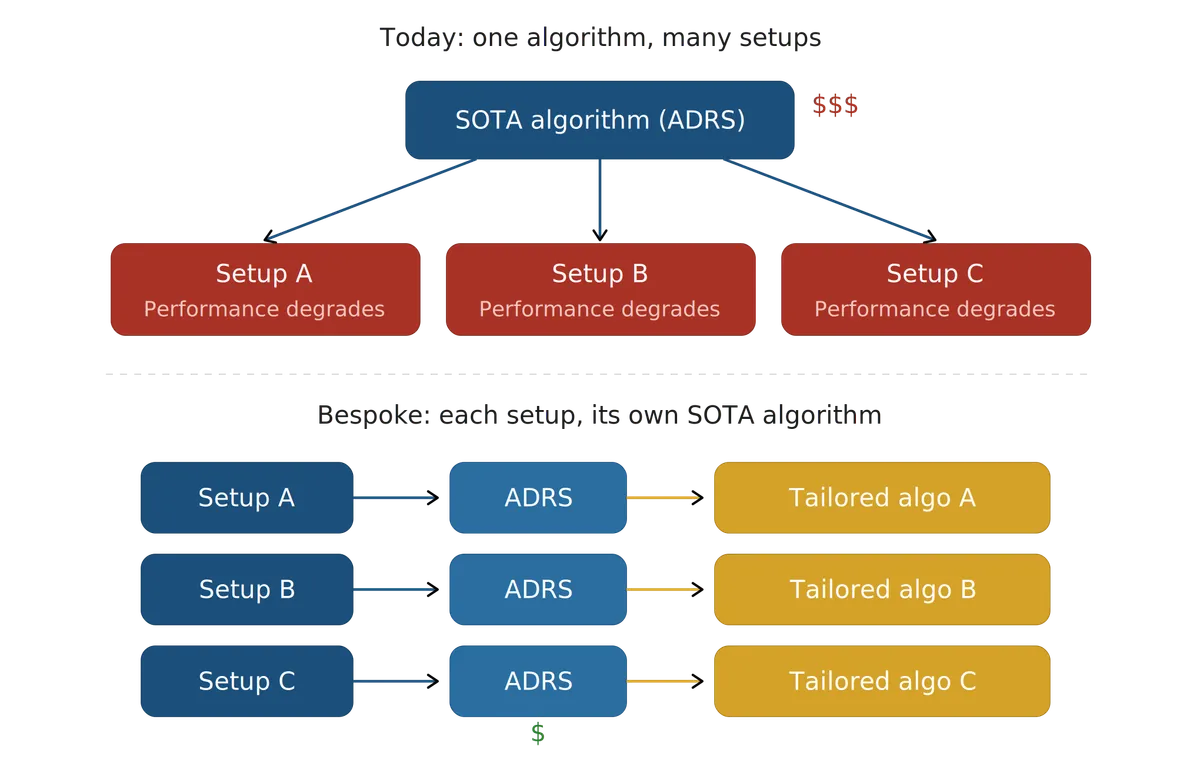
برای دههها، پژوهشگران سیستمها مجبور بودند برای بیرون کشیدن حداکثر توان از سختافزار، بهصورت دستی روی توابع اکتشافی (Heuristics) و الگوریتمها زمان بگذارند. صنعت معمولاً در مرحلهٔ بعد، این نتایج پژوهشی تکموردی را به محیطهای عملیاتی (Production) منتقل میکند. با این حال، هدف ADRS این است که به سمت بهینهسازیهای اختصاصی (Bespoke) حرکت کند؛ یعنی الگوریتمهایی که در لحظه با سختافزار، حجم کاری و توافقنامههای سطح خدمات (SLO) یک استقرار خاص سازگار شوند.
تا پیش از این، مانع اصلی این چشمانداز، هزینه بود. اکثر چارچوبهای موجود، مانند OpenEvolve و GEPA، برای هر تکتک جهشها یا تغییرات (Mutation)، بهشدت به گرانترین مدلهای پیشرو و بسته (Closed-source) تکیه میکنند. این موضوع یک سد ورودی بالا برای پژوهشگرانی ایجاد میکند که توان مالی انجام چنین آزمایشهایی را ندارند. مهمتر از آن، این رویکرد مانع از انتقال به بهینهسازی مستمر میشود. وقتی هزینه هر فراخوانی بالا باشد، بهینهسازی مجدد و شبانه در سطح یک ناوگان ابری جهانی — که باید با تغییر اولویتها یا تغییر نوع GPUها سازگار شود — از نظر مالی غیرممکن است.
چشمانداز: ADRS به عنوان CI/CD
ADRS نباید صرفاً به عنوان راهی برای تولید یک نتیجهٔ قوی برای یک مقالهٔ پژوهشی دیده شود. در عوض، باید به عنوان حرکتی به سمت راهکارهای کاملاً اختصاصی دیده شود که بیشترین بهره («آبگیری») را از محیط دقیق استقرار استخراج میکنند. اگر این منطق را به نتیجهٔ نهاییاش برسانیم، ADRS را باید شکلی پیشرفتهتر از CI/CD دانست. در این مدل، کاربر تابع امتیازدهی و تنظیمات استقرار خود را تعریف میکند. بهجای اینکه فقط ابزارهای Linter یا Formatter بهطور خودکار استایل کد را اصلاح کنند، خودِ الگوریتم بهطور خودکار بهینه میشود.
برای مثال، یک شرکت که امروز یک调度گر ابری چند-منطقهای (Multi-region cloud scheduler) را اجرا میکند، از همان الگوریتمی استفاده میکند که همهٔ دیگران استفاده میکنند. اما با ADRS ارزانقیمت، آنها میتوانند هر شب الگوریتم خود را بر اساس الگوهای ترافیکی واقعی، SLOهای واقعی و ترکیب سختافزاری واقعی خود بازبهینهسازی کنند. هرگاه منابع (مانند GPUهای جدید) یا اولویتها (SLOهای متفاوت) تغییر کنند، الگوریتمهای متناظر بهطور خودکار بهینه میشوند.
فلسفهٔ «ابتدا هارنس» (Harness-First)
LEVI تمرکز را از خودِ مدل به «هارنس جستوجو» (Search Harness) منتقل میکند. بینش اصلی این است که فرض دسترسی به بزرگترین مدلهای SOTA نباید به عنوان پیشفرض پذیرفته شود. در واقع، مقالهٔ اصلی FunSearch گزارش داده بود که نتوانسته است از مدلهای بزرگتر بهره ببرد؛ و تنها با AlphaEvolve بود که موفق شدند.
LEVI بر این premise استوار است که کمیت راهکارهای تولید شده توسط مدلهای کوچک میتواند برتری کیفیِ تعداد کمی فراخوانی گرانقیمت را خنثی کند. برای پیادهسازی این موضوع، LEVI از یک استراتژی تخصیص مدل لایهبندی شده (Stratified Model Allocation) استفاده میکند که ظرفیت مدل را با نیاز خاص وظیفه تطبیق میدهد:
- مدلهای کوچک (مثلاً QWEN 30B محلی): حجم اصلی جستوجو را بر عهده دارند. آنها اصلاحات محلی، بهبودهای تدریجی در یک خانوادهٔ الگوریتمی تثبیت شده، تنظیم ثابتها و بهینهسازی موارد خاص (Edge cases) را انجام میدهند. هدف این مدلها ایجاد وسعت (Breadth) و توان عملیاتی (Throughput) است.
- مدلهای مرزی (Frontier Models): برای «چرخشهای پارادایم» (Paradigm Shifts) کمتکرار رزرو میشوند. اینها جهشهایی هستند که هدفشان پیشنهاد رویکردهای ساختاری متفاوت است، نه صیقل دادن راهکارهای موجود. این مدلها استدلال خلاقانه و دانش گسترده را فراهم میکنند.
این رویکرد از Treating مدلها بهعنوان مجموعهای جایگزینپذیر (Interchangeable ensembles) جلوگیری میکند. برخی چارچوبها بهطور یکنواخت از یک مجموعه مدل نمونهبرداری میکنند یا فراخوانیها را بدون توجه به نیاز Mutation مسیریابی میکنند. LEVI یک عدم تقارن طبیعی را تشخیص میدهد: اصلاح کردن (Refining) آسان است، اما پیشنهاد یک مسیر بنیادین جدید نیازمند جهشی در استدلال خلاقانه است. هارنس باید از این تمایز آگاه باشد و منابع را بر این اساس تخصیص دهد.
حل مشکل فروپاشی تنوع (Diversity Collapse)
یک ریسک بزرگ در استفاده از مدلهای کوچکتر — که توزیع پیشآموزشی محدودتری دارند — «فروپاشی آرشیو» (Archive Collapse) است؛ وضعیتی که در آن جستوجو روی یک خانوادهٔ واحد از راهکارها همگرا میشود. چارچوبهای موجود اغلب برای حفظ تنوع به فضای خروجی وسیع مدلهای مرزی (مانند GPT-5 یا Claude Opus) تکیه میکنند، یا روشهای پیچیدهٔ نمونهبرداری ردکننده (Rejection Sampling) و مدلهای Embedding را به عنوان جبران اضافه میکنند. اینها صرفاً جبرانی برای یک بنیاد ضعیف هستند، نه راه حل.
LEVI این مشکل را با یکپارچهسازی تنوع ساختاری و رفتاری در یک مکانیسم واحد حل میکند. بهجای انتخاب یکی از این دو محور، LEVI هر دو را به عنوان ابعادی از یک «توصیفگر رفتاری» (Behavioral Descriptor) به کار میگیرد.
جزئیات مکانیسم تنوع
- تنوع ساختاری (Structural Diversity): ویژگیهای ساختاری کد مانند تعداد حلقهها و پیچیدگی سیکلوماتیک (Cyclomatic Complexity) را میسنجد. این فراتر از ابعاد سادهای مثل طول کد است؛ زیرا دو برنامه با تعداد حلقههای متفاوت ممکن است مسئله را به شکلی کاملاً یکسان حل کنند.
- تنوع رفتاری (Behavioral Diversity): نتایج عملکرد را در هر نمونه (Per-instance performance) اندازهگیری میکند. این ویژگی تفاوتهایی را میگیرد که تحلیل ساختاری از دست میدهد، چرا که راهکارهایی که در نمونههای فردی مشابه عمل میکنند، ممکن است در واقع به روشهای کاملاً متفاوتی کار کنند.
- اثر انگشت (Fingerprinting): هر راهکار به یک بردار «اثر انگشت» نگاشته میشود که ترکیبی از این ویژگیهای نرمال شده در بازه [0, 1] است. کاربران میتوانند ابعاد خاص خود را تعریف کنند اگر پیشفرضها با مسئله خاص آنها سازگار نباشد.
- آرشیو CVT-MAP-Elites: این اثر انگشت در آرشیوی قرار میگیرد که از تسلیخ ورونوی (Voronoi tessellation) برای حفظ ساختار هندسی در فضای ترکیبی استفاده میکند. این تضمین میکند که آرشیو جستوجو به یک خانوادهٔ واحد از راهکارها سقوط نکند.
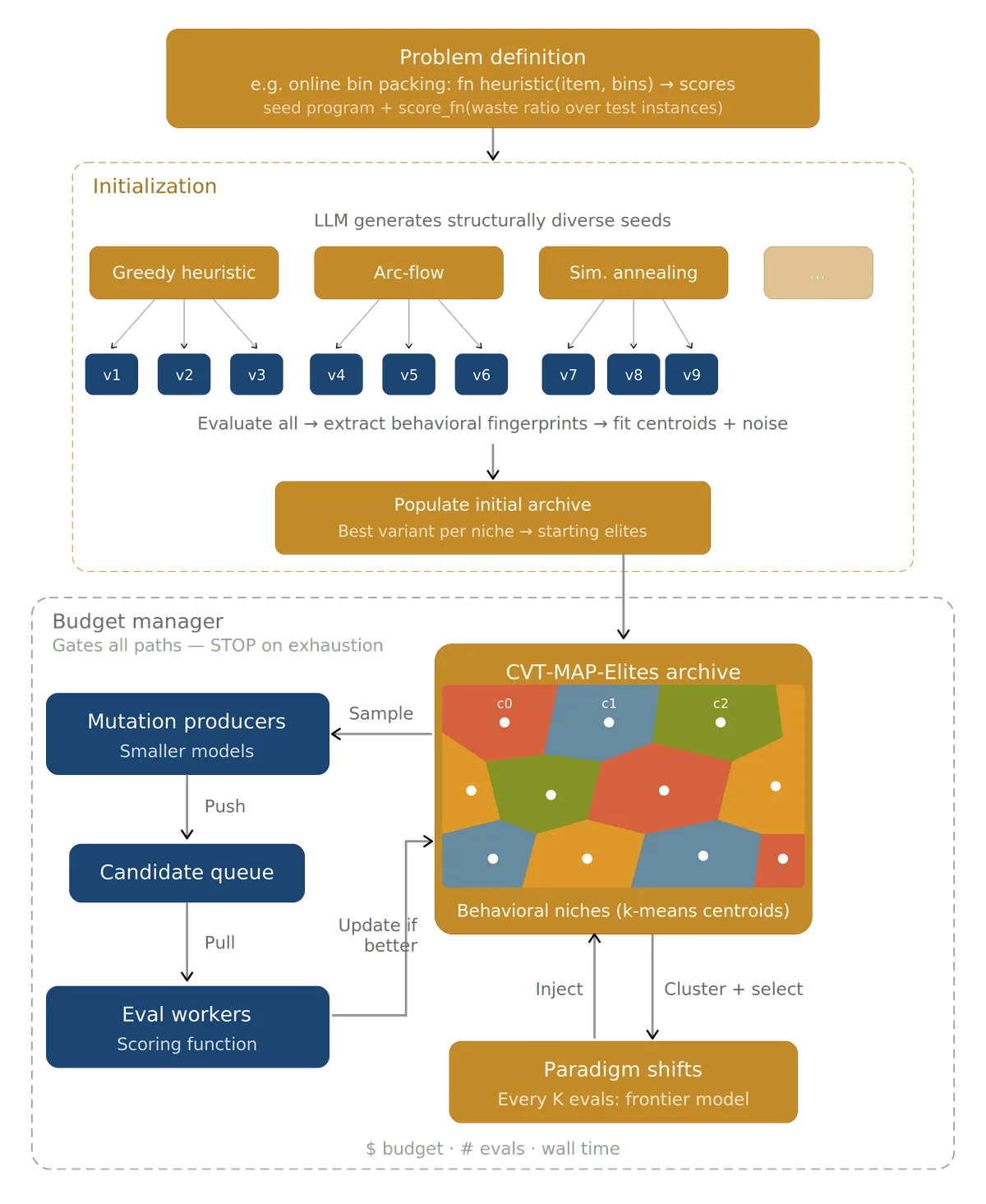
مقداردهی اولیه و انتخاب از آرشیو
برای جلوگیری از مشکلات مربوط به پراکندگی (Sparsity) در CVT-MAP-Elites سنتی — جایی که مقداردهی اولیه یکنواخت در ۶ تا ۱۰ بُعد منجر به بسیاری از مناطق بازدیدنشده میشود — LEVI یک رویکرد دادهمحور را اتخاذ میکند. این سیستم مجموعهای از رویکردهای عمداً منحصربهفرد را از طریق تولید متوالی، صرفنظر از امتیازات آنها، ایجاد میکند و از اینها برای ساخت مراکز (Centroids) اولیه استفاده میکند. این اطمینان میدهد که آرشیو بر اساس راهکارهایی بنا شده که شناخته شده است متفاوت هستند.
این آرشیو دو هدف دارد. اول، با تضمین حفظ مجموعهای متنوع از راهکارها، از همگرایی زودهنگام جلوگیری میکند. دوم، مناطق ورونوی بهطور طبیعی راهکارها را در خانوادههای الگوریتمی خوشهبندی میکنند. این به LEVI اجازه میدهد تا راهکارهای واقعاً نماینده از هر خانواده را انتخاب کرده و به مدلهای بزرگتر بدهد تا زمینه (Context) لازم برای آن چرخشهای پارادایمیِ کمتکرار فراهم شود.
مثال از API پایتون
LEVI پیچیدگیهای چارچوب را انتزاع میکند تا کاربران بتوانند بر روی مسئله تمرکز کنند. در ادامه مثالی برای بهینهسازی مسئلهٔ بستهبندی (Bin Packing) آمده است:
import levi
def score_fn(pack):
bins = pack([4, 8, 1, 4, 2, 1], 10)
wasted = sum(10 - sum(b) for b in bins)
return {"score": max(0.0, 100.0 - wasted)}
result = levi.evolve_code(
"Optimize bin packing to minimize wasted space",
function_signature="def pack(items, bin_capacity):",
score_fn=score_fn,
model="openai/gpt-4o-mini",
budget_dollars=2.0,
)
تحلیل عملکرد در بنچمارکها
در تستهای رودررو، LEVI در هر مسئلهای که امکان بهبود وجود داشت، بالاترین امتیاز را کسب کرد. این سیستم به میانگین امتیاز ۷۶.۵٪ رسید و از GEPA (۷۱.۹٪) و OpenEvolve (۷۰.۶٪) پیشی گرفت که نشاندهنده بهبود ۴.۶ امتیازی نسبت به SOTA قبلی است.
تفکیک دقیق عملکرد:
- Cloudcast: رسید به امتیاز کامل ۱۰۰.۰، که نشان میدهد مسئله تحت تابع امتیازدهی کاملاً حل شده است.
- LLM-SQL: افزایش ۵.۸ امتیازی نسبت به SOTA قبلاً.
- Spot Multi-Reg: افزایش ۵.۷ امتیازی.
- Transaction Scheduling: بهبود اندک ۱.۱ امتیازی، که بازتابدهنده فضای بهینهسازی سختتر است.
- Spot Single-Reg: بهبود اندک ۰.۳ امتیازی.
- Prism: در امتیاز ۸۷.۴ با تمام چارچوبها برابر ماند، که تأیید میکند فرمولبندی مسئله تنها یک راهکار غالب میپذیرد.
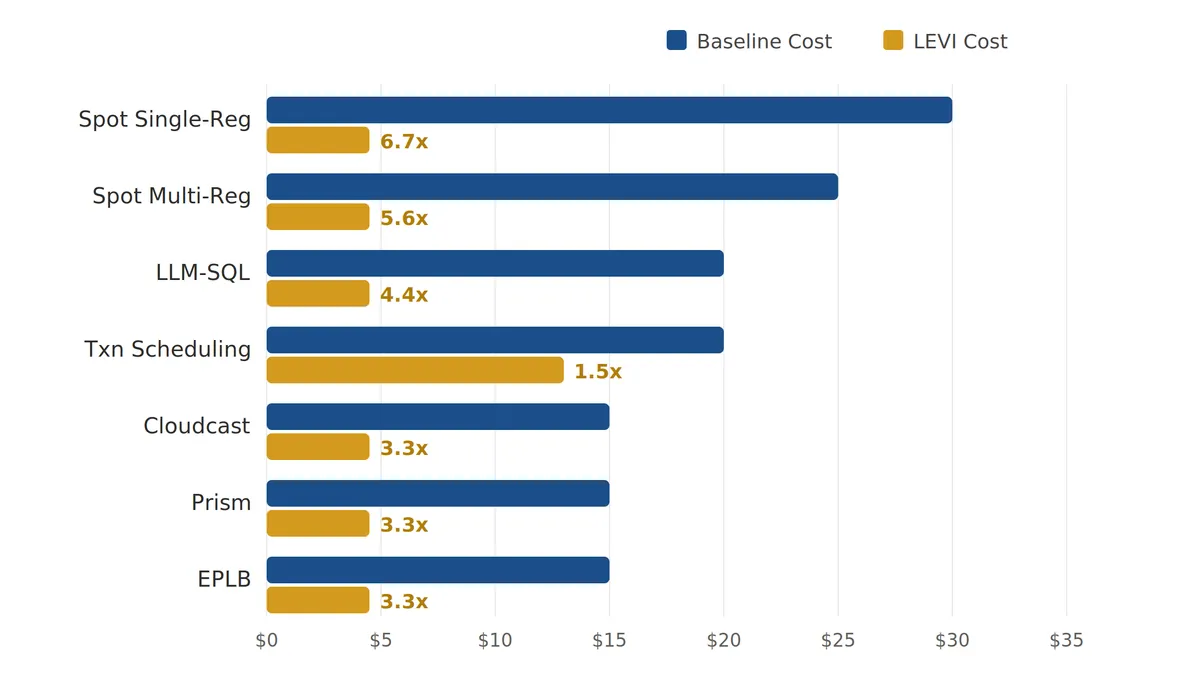
تحلیل هزینه و بهرهوری
تأثیر مالی رویکرد «ابتدا هارنس» بسیار چشمگیر است. در حالی که مدلهای پایه اغلب ۱۵ تا ۳۰ دلار برای هر مسئله هزینه میکنند، LEVI بهطور معمول حدود ۴.۵۰ دلار هزینه دارد (هرچند Transaction Scheduling ۱۳ دلار هزینه داشت). صرفهجوییها بین ۱.۵ تا ۶.۷ برابر است و در مجموع بیش از ۱۰۰ دلار ذخیره شده است. با مسیریابی اکثر جهشها از طریق مدلهای سبک، هزینه هر نسل در مقایسه با مدلهایی که برای هر فراخوانی از GPT-5 یا Gemini-3.0-Pro استفاده میکنند، تقریباً یک مرتبه بزرگی (Order of Magnitude) کاهش مییابد.
در تستهای کنترلشده برای جداسازی معماری (با استفاده از یک مدل محلی Qwen3-30B-A3B، ۷۵۰ ارزیابی موفق و سه Seed تصادفی)، LEVI بهرهوری نمونهبرداری برتری را نشان داد:
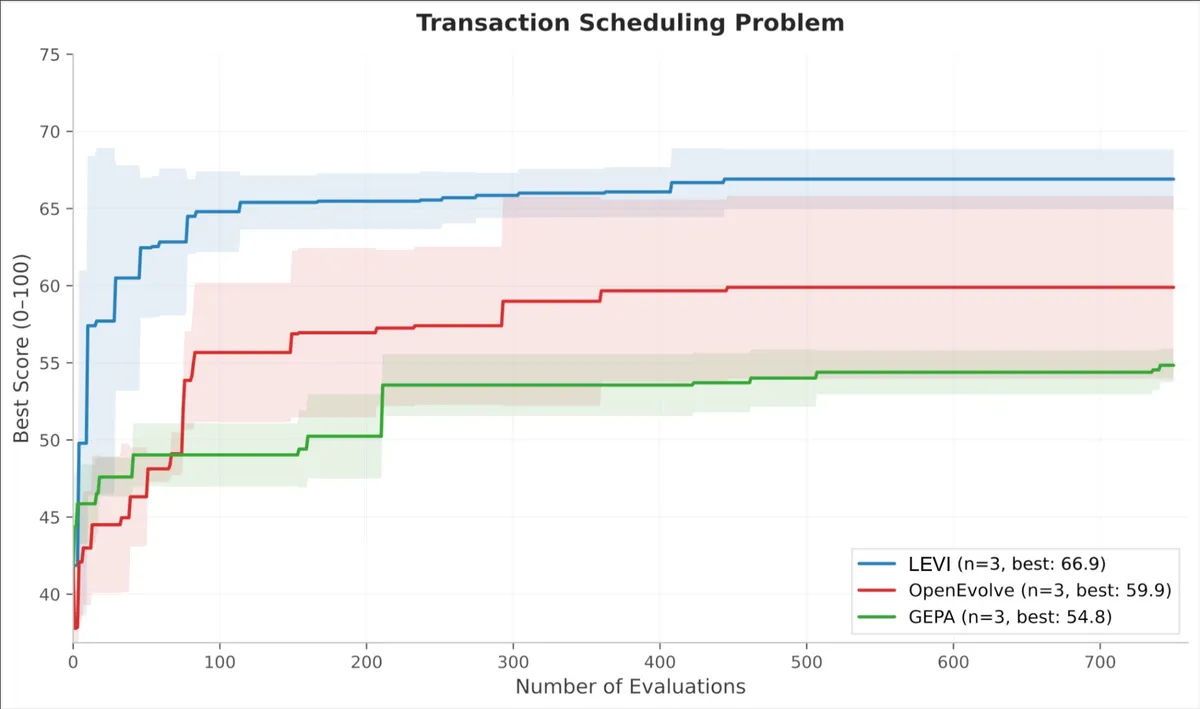
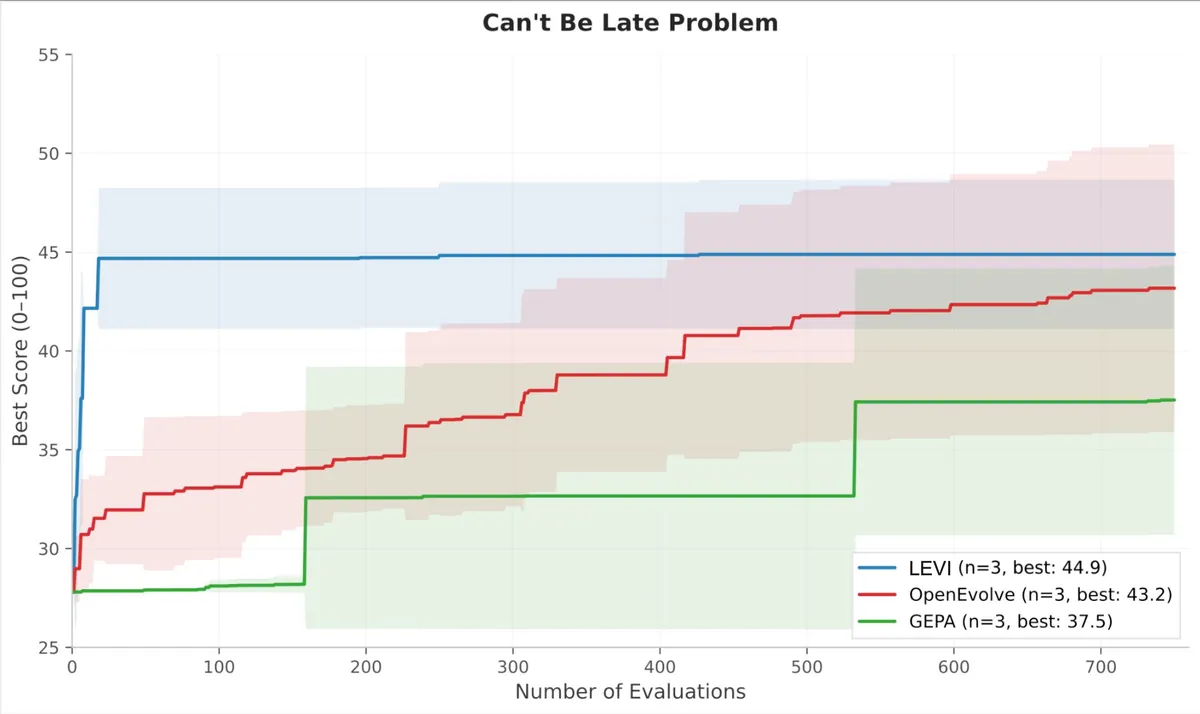
- Transaction Scheduling: این یک گونه از مسئله ترتیببندی NP-hard است که چندین خانواده الگوریتمی (Greedy, Simulated Annealing, Genetic) در آن viable هستند، اما عملکرد روی یک نمونه واحد سنجیده میشود. LEVI در ۱۰۰ ارزیابی اول به امتیاز ۶۲ رسید. مدلهای پایه هرگز به این سطح نرسیدند. امتیازات نهایی: LEVI 64.9، OpenEvolve 59.9، GEPA 54.4. هر دو مدل پایه به دلیل همگرایی زودهنگام بهشدت دچار پلاتو شدند.
- Can't Be Late: این مسئله در ۱۰۸۰ شبیهسازی امتیاز میگیرد و سیگنال غنیتری برای رویکردهای مبتنی بر Pareto فراهم میکند. LEVI در ارزیابی ۵۰ام به نزدیکی اوج عملکرد رسید، در حالی که OpenEvolve به بیش از ۶۰۰ ارزیابی نیاز داشت؛ یعنی یک مزیت ۱۲ برابری در بهرهوری نمونهبرداری.
درسهایی برای چارچوبهای آیندهٔ ADRS
ساخت سیستم حول مدلهای کوچک، توازنهای (Trade-offs) بحرانی را آشکار میکند که چارچوبهای مبتنی بر مدلهای مرزی هرگز با آنها مواجه نمیشوند:
- نرخ خطا در مقابل هزینه: مدلهای کوچکتر чаще کدهای خراب تولید میکنند. اما چون فراخوانیها بسیار ارزان هستند، سیستم میتواند دفعات بسیار بیشتری تلاش کند (Retry) و همچنان مقرونبهصرفهتر از یک فراخوانی واحد و گران باشد.
- سوءاستفاده از پاداش (Reward Hacking): مدلهای کوچک بیشتر مستعد بهرهبرداری از نقاط ضعف ارزیابها هستند. این نشان میدهد که بهبود ارزیابها یک ضرورت جهانی برای تمام چارچوبهای ADRS است.
- کد بهجای زبان طبیعی: هنگام هدایت مدلهای کوچک، یک اسکلت کد (Code Skeleton) بسیار مؤثرتر از متن است. پرامپتی مثل «تبرید شبیهسازی شده را امتحان کن» فضای زیادی برای تفسیر نادرست باقی میگذارد. مرحلهٔ چرخش پارادایم در LEVI، اسکلتهای کدی را تولید میکند که برنامهٔ سرد کردن (Cooling schedule) و معیار پذیرش را پیاده میکنند تا مدل چیز concrete برای کار داشته باشد.
- زمان ارزیابی: مزیت حجمی مدلهای کوچک به ارزیابیهای سریع وابسته است. برای مسائلی که یک ارزیابی یک ساعت زمان میبرد، هر فراخوانی ارزشمند است و مدلهای بزرگتر منطقیتر میشوند. LEVI این مشکل را برای اکثر مسائل با استفاده از یک مدل توزیعشده Producer-Consumer بهصورت async کاهش میدهد.
این تغییر نشان میدهد که خودِ مدل در حال تبدیل شدن به یک کالا (Commodity) است. برتری رقابتی واقعی اکنون در معماری جستوجو و توانایی حفظ تنوع بدون تکیه به هوش خام یک مدل تریلیون-پارامتری نهفته است.
اگر با ADRS به عنوان یک فرم پیشرفته از CI/CD برخورد شود، شرکتها میتوانند الگوریتمهای خود را هر شب با تغییر الگوهای ترافیکی و ترکیب سختافزاری بهطور خودکار بهینه کنند. این امر، انتخاب الگوریتم را از یک تصمیم ایستا به یک فرآیند پویا و تطبیقی تبدیل میکند.
توسعهدهندگان علاقهمند میتوانند پیادهسازی این پروژه را در گیتهاب به نشانی github.com/ttanv/levi بررسی کنند. ابتکار AI-Driven Research Systems (ADRS) یک تلاش باز است؛ همکاران میتوانند از طریق [email protected] یا در Slack و Discord با جامعهٔ آن ارتباط بگیرند.



گفتگو