
تصور کنید هر بار که بخواهید یک اشتباه کوچک در سازماندهی دادههایتان را اصلاح کنید، باید هزاران دلار از جیب خود خرج کنید. برای توسعهدهنده PodZeus، این کابوس مالی با خرید چند قطعه سختافزار و تبدیل اتاق خواب به یک مرکز داده کوچک به پایان رسید.
طبق گزارش منتشرشده در dev.to، پردازش ۱۹۰ هزار اپیزود پادکست روی یک سرور گرافیکی (GPU) شخصی، این سازنده را از صورتحسابی احتمالی بیش از ۲۵۰ هزار دلار نجات داد. در ۲۳ ژوئن ۲۰۲۶، این پروژه با تغییر استراتژی از «اجاره سرویس» به «مالکیت ماشین»، اقتصاد عملیاتی خود را بهطور کامل دگرگون کرد و یک پروژه دادهای که به دلیل هزینهها غیرممکن به نظر میرسید را به یک بکاند تجاری viable تبدیل کرد.
بسیاری از سازندگان محصولات هوش مصنوعی، تبدیل صوت به متن یا همان Transcription را هزینه اصلی میدانند. اما در واقعیت، این مرحله تنها تهیه مواد اولیه است. هزینه واقعی در گردشکار متناوب نهفته است: پاکسازی، تکهبندی (Chunking) — که شبیه بریدن یک غذای بزرگ به لقمههای کوچک برای بلع راحتتر مدل است — ایندکسگذاری و استخراج موجودات (Entities) از صدها هزار فایل. هر بار که ساختار دادهها (Schema) نیاز به تغییر داشته باشد، هر یک از فایلها باید دوباره پردازش شوند و این ضربدرِ هزینهای است که میتواند هر پروژه کوچکی را که به APIهای شخص ثالث متکی است، ورشکست کند. در این مسیر، مدیریت هوشمندانه خروجیهای متنی میتواند ارزش دادهها را چند برابر کند، مشابه رویکردی که در راهنمای تبدیل یک فایل صوتی به ۶ دارایی محتوایی بررسی کردیم.
تفاوت این دو رویکرد شبیه تفاوت پرداخت کرایه تاکسی برای هر سفر با مالکیت یک خودروی شخصی است. در مجموعههای داده عظیم، تاکسیمتر API هرگز متوقف نمیشود، فارغ از اینکه یک اجرای خاص با موفقیت به پایان رسیده باشد یا با شکست مواجه شده باشد. اما مالکان سختافزار محلی میتوانند «اشتباه کنند»؛ آنها میتوانند آزمایشهای زشت و ناقص انجام دهند و منطق خود را بدون جریمه مالی اصلاح کنند. همانطور که در تحلیلهای پیشین ما درباره مدیریت هزینه استنتاجات اشاره کردیم، مالکیت زیرساخت در مقیاس بالا، تنها راه دستیابی به آزادی تجربه و خطا است.
لایههای سختافزاری
این سرور با هزینهای بین ۳ تا ۴ هزار یورو ساخته شده است. این دستگاه یک تجهیزات لوکس سازمانی نیست، بلکه جعبهای کاربردی است که به مرور زمان بهینهتر و کمتر «نحس» شده است. قلب تپنده این سیستم یک مادربورد TRX40 Aorus Master و پردازنده Threadripper 3960X با ۶۴ گیگابایت رم و ۲ ترابایت فضای ذخیرهسازی است.

پیکربندی GPU محوریت اصلی ماشین است:
- سه کارت RTX 4060 Ti (هر کدام ۱۶ گیگابایت)
- یک کارت NVIDIA A30 (۲۴ گیگابایت) که در سال ۲۰۲۴ و پیش از آنکه هوش مصنوعی محلی به یک куль (فرقه) تبدیل شود، با قیمت حدود ۱ هزار یورو از eBay خریداری شد.
از منظر مالی، این سرمایه جایگزین هزینههای جاری اجاره شده است. بر اساس تحلیل توسعهدهنده در dev.to، هزینه اجاره یک GPU برای یک سال در RunPod (با قیمتگذاری On-demand) اغلب از قیمت کل این جعبه چهار-گرافیکی بیشتر است:
- A40 (۰.۴۴ دلار در ساعت): حدود ۳۲۱ دلار در ماه یا ۳۸۵۴ دلار در سال
- RTX A6000 (۰.۴۹ دلار در ساعت): حدود ۳۵۸ دلار در ماه یا ۴۲۹۲ دلار در سال
- RTX 4090 (۰.۶۹ دلار در ساعت): حدود ۵۰۴ دلار در ماه یا ۶۰۴۴ دلار در سال
- A100 SXM (۱.۴۹ دلار در ساعت): حدود ۱۰۸۸ دلار در ماه یا ۱۳۰۵۲ دلار در سال
دردسرهای نگهداری محلی
مالکیت سختافزار با «دردهای فیزیکی» همراه است. کارت A30 چون خنککننده فعال ندارد، در یک کیس معمولی شروع به پختن خودش میکند. توسعهدهنده مجبور شد فنهای دمنده را مستقیماً به سمت آن هدایت کند. این صحنه هیچ شباهتی به عکسهای تمیز «هوملبها» ندارد؛ اینجا جنگ واقعی برای جریان هوا و بقای قطعات است.
علاوه بر خنککنندگی، هوش مصنوعی محلی یعنی مدیریت پیچیده وابستگیها. این مسیر شامل کلنجار رفتن با نسخههای CUDA و درایورهای NVIDIA، مدیریت رفتار صفها و رسیدگی به دانلودهای ناقص است. برخی اپیزودهای پادکست سه ساعت طول میکشند و برای جلوگیری از کرش کردن سیستم، نیاز به تکهبندیهای خاصی دارند.
دسترسی از راه دور در اینجا حیاتی است. استفاده از Tailscale چندین بار پروژه را در زمان دوری توسعهدهنده از ماشین نجات داد. یک چیدمان پیشنهادی شامل VPN، سوئیچ برق از راه دور و نظارت مداوم است تا ماشین هنگام خرابیهای اجتنابناپذیر، ریبوت شود. اگر تمیزی میخواهید، از API استفاده کنید؛ اگر اهرم قدرت میخواهید، باید سختیهای مدیریت سختافزار را بپذیرید.
اقتصاد تبدیل صوت به متن
پردازش ۲۵۳,۳۳۳ ساعت صوت (حدود ۱۹۰ هزار اپیزود با میانگین ۸۰ دقیقه برای هر کدام) در ارائهدهندگان مختلف هزینههای متفاوتی دارد. برای مجموع ۱۵.۲ میلیون دقیقه صوت، هزینههای گام اول به این شرح است:
- Groq Whisper Large v3 Turbo (۰.۰۴ دلار در ساعت): حدود ۱۰,۱۳۳ دلار
- Groq Whisper V3 Large (۰.۱۱۱ دلار در ساعت): حدود ۲۸,۱۲۰ دلار
- OpenAI gpt-4o-mini-transcribe (۰.۰۰۳ دلار در دقیقه): حدود ۴۵,۶۰۰ دلار
- OpenAI gpt-4o-transcribe (۰.۰۰۶ دلار در دقیقه): حدود ۹۱,۲۰۰ دلار
- OpenAI gpt-realtime-whisper (۰.۰۱۷ دلار در دقیقه): حدود ۲۵۸,۴۰۰ دلار
در حالی که Groq نقطه ورود ارزانقیمتی برای بازشناسی گفتار (ASR) است، خطر واقعی در «گام دوم» نهفته است. تبدیل صوت به متن تنها شروع است؛ برای یافتن سیگنالهای واقعی مثل اشارات به برندها، مهمانان تکراری، جهشهای فرهنگی و موضوعاتی که در طول زمان تغییر میکنند، باید دادهها را دوباره پردازش کرد. این چالش مدیریت هزینهها در مقیاس بالا، یادآور استراتژیهای بهینهسازی است که در کاهش ۹۷ درصدی هزینه ترجمه در Global APIs مشاهده شد، جایی که مسیرهای هوشمند جایگزین پرداختهای بیرویه شدند.
در ۱۹۰ هزار اپیزود، هزینه بازپردازش بهشدت رشد میکند. هر اجرای ناموفق، اشتباه در ساختار داده یا ایده جدید برای استخراج، در کل مجموعه داده ضرب میشود:
- در نرخ ۳ سنت برای هر اپیزود: ۵,۷۰۰ دلار
- در نرخ ۱۰ سنت برای هر اپیزود: ۱۹,۰۰۰ دلار
- در نرخ ۳۰ سنت برای هر اپیزود: ۵۷,۰۰۰ دلار
- در نرخ ۱ دلار برای هر اپیزود: ۱۹۰,۰۰۰ دلار
یک بار بازپردازش با نرخ ۳۰ سنت، ۵۷ هزار دلار هزینه دارد که از کل هزینه ارزانترین تبدیل اولیه بیشتر است. وقتی پروژه برای اصلاح منطق استخراج ابتدایی به چندین تکرار نیاز دارد، مدل API دیگر پایدار نیست. صورتحساب اصلی، متن نبود؛ بلکه گردشکار (Workflow) بود.
خط لوله پردازشی ترکیبی
توسعهدهنده یک تفکیک جراحیگونه بین محاسبات محلی و ابری ایجاد کرد. او از «مذهبِ» اجرای همه چیز در خانه دوری میکند — زیرا ناکارآمد است — و فقط گلوگاههای حجیم را که هزینه اشتباه در آنها بالاست، محلی کرده است.
مکانیزمهای لایه محلی:
- ورودی: اپیزودها از طریق Feedهای RSS دریافت میشوند.
- نرمالسازی: صوتها دانلود شده و با استفاده از FFmpeg نرمالسازی میشوند.
- صفبندی: مدیریت کارها توسط RabbitMQ انجام میشود تا از فشار بیش از حد به سیستم جلوگیری شود.
- اجرا: ورکرهای زبان Go کارها را میگیرند و به هر GPU که آزاد باشد ارسال میکنند.
- تبدیل: مدل WhisperX تبدیل صوت به متن را همراه با خروجیهای زماندار (Timestamped) انجام میدهد.
- ایندکسگذاری: متنها ذخیره، پاکسازی، تکهبندی و برای جستوجوی متنی کامل (Full-text search) در Postgres ایندکس میشوند.
مکانیزمهای لایه ابری:
- کنترل کیفیت: مدلهای محلی در ابتدا تست شدند اما برای خروجیهای ساختاریافته (Structured output) «زباله» زیادی تولید میکردند. خروجی ساختاری بد، بدتر از نبودِ آن است چون بهطور نامحسوس پایگاه داده را مسموم میکند.
- استنتاج: برای استخراج باکیفیت مفاهیم، موجودات، اشارات به برند، پرسشها و خلاصهها، از مدلهای Qwen در سرویس Nebius AI استفاده میشود. این تفکیک وظایف میان مدلهای مختلف برای بهینهسازی هزینه، شباهگی زیادی به استراتژی لایهبندی مدلها در توسعه بازیها دارد که منجر به کاهش چشمگیر هزینههای استنتاج شد.
- پشتیبانی: کل پشته (Stack) برای میزبانی اپلیکیشن بر AWS و Postgres متکی است.
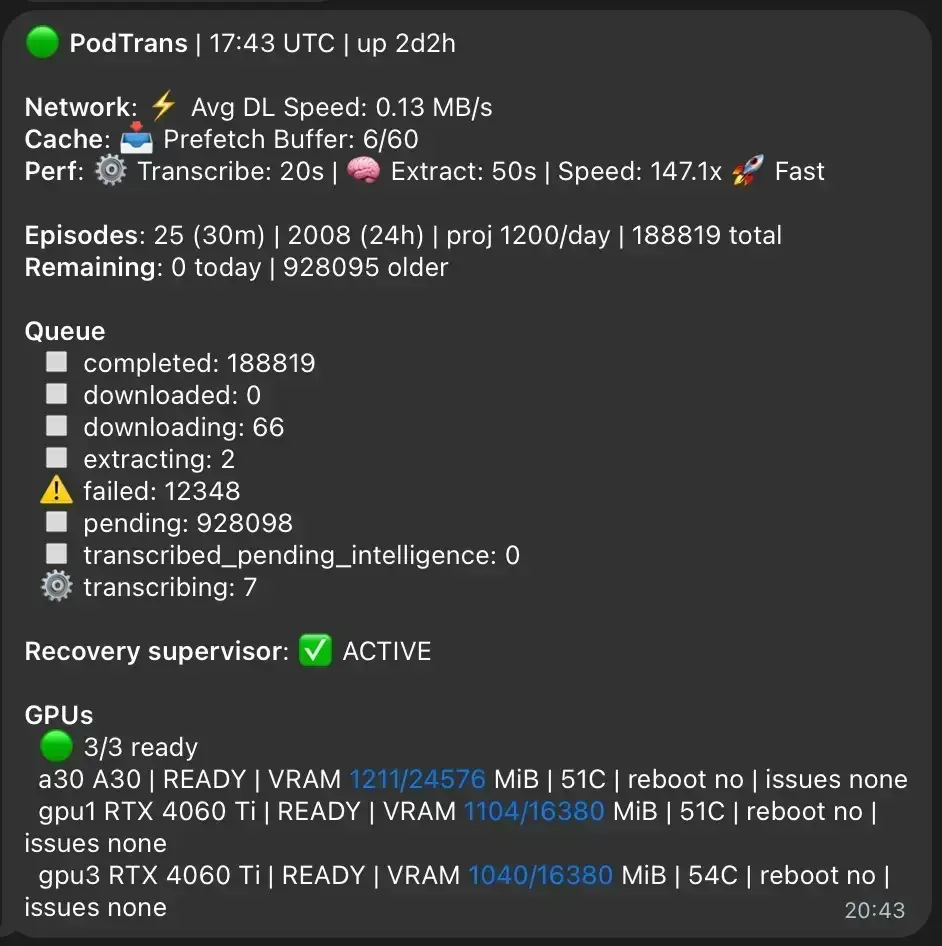
این رویکرد ترکیبی تضمین میکند هزینه فقط برای کارهایی پرداخت شود که واقعاً به یک مدل برتر نیاز دارند، در حالی که حجم عظیم پردازش صوت توسط سرور محلی جذب میشود. در حال حاضر، این دستگاه هر ۳۰ دقیقه بین ۵۰ تا ۱۲۰ اپیزود را پردازش میکند (بسته به طول و کیفیت صوت). مقیاسپذیری این سیستم پیشبینیپذیر است: اضافه کردن سرور دوم مشابه، توان عملیاتی را تقریباً دو برابر میکند. این پیشبینیپذیری بسیار مهم است زیرا پروژه را از حالت «نگاه کردن به تاکسیمتر» خارج میکند.
تبدیل زیرساخت به محصول
این بکاند بهینه، قدرتبخش PodZeus است؛ ابزاری برای تحلیل هوشمند پادکستها، رصد کلمات کلیدی یا برندها و دنبال کردن موضوعات در کل فضای پادکست. این ابزار به کاربران اجازه میدهد دقیقاً بفهمند در یک اپیزود چه گفته شده و آن را در طول زمان ردیابی کنند.
توسعهدهنده میپذیرد ابزارهای تکاملیافتهتری مثل Podscan یا کارهای Arvid Kahl وجود دارند، اما استراتژی او تمرکز بر یک نقطه میانی متمرکز با ساختار هزینهای منطقی است. مزیت اصلی در اینجا نه تکنولوژی است، بلکه «خندقِ اقتصادی» (Moat) حاصل از توانایی مالی است. در حالی که رقبایی که قیمت خردهفروشی API را میپردازند برای باز-ایندکس کردن کتابخانه خود به دلیل هزینه تردید میکنند، سازنده با پشته محلی بهراحتی این کار را انجام میدهد.
این موضوع اجازه میدهد تکرار سریعتر صورت گیرد و ساختار دادهها بدون ترس از صورتحسابهای کلان تغییر کند. او میتواند بردار معنایی (Embedding) را با Pinecone برای جستوجوی معنایی و بازرتبهبندی (Reranking) را با Cohere تست کند. هرچند این بخش از کار متوقف شد چون کاربران نسخهای «کاربردی» میخواستند (کجا ذکر شده، چه گفته شده، کدام اپیزود، قابلیت خروجی گرفتن و ردیابی زمانی) تا نسخهای «ظریف» (Elegant)، اما توانایی تست این موارد بدون صورتحسابهای سنگین وجود داشت.
درسهایی برای سازندگانی که تنها هستند
هر SaaS نیاز به سرور در اتاق خواب ندارد. برای حجمهای کم، اعتبارسنجی یک ایده جدید یا پردازش تعداد محدودی فایل، APIها همچنان انتخاب درست هستند. هیچ جایزهای برای خرید سختافزار پیش از اطمینان از اینکه آیا اصلاً کسی به محصول شما اهمیت میدهد یا خیر، وجود ندارد. کارهای زیرساختی هرگز نباید مانع از فروش و بازاریابی توسعهدهنده شوند.
هوش مصنوعی محلی تنها زمانی استراتژی برتر است که «حجم داده» خودش محصول باشد. وقتی موفقیت در گرو تبدیل دادههای نامنظم و عظیم به جداول ساختاریافته و ایندکسهای قابل جستوجو است، مالکیت گلوگاهها اهرم رقابتی لازم برای رقابت را فراهم میکند. این کار، ساختار هزینه را از یک پاورقی به خودِ محصول تبدیل میکند.
گامهای استراتژیک برای شما
- از محافظهکاری در API دوری کنید: وقتی هر اصلاح کوچک از طریق API گران به نظر برسد، توسعهدهنده ناخودآگاه از یادگیری محافظت میکند. شما باید در ابتدا سریع اشتباه کنید. ساختار داده را تغییر دهید و آزمایشهای زشت را اجرا کنید. به خروجیها خیره شوید و بپذیرید که نیمی از فرضهای شما احمقانه بوده است.
- جاذبه ساختار داده را مدیریت کنید: یک بار که مجموعه داده عظیمی پردازش شد، ساختار استخراج مانند یک نیروی گرانشی عمل میکند. تغییر آن در آینده ممکن است اما هرگز رایگان نیست؛ پیش از پردازش حجمهای جدی، ساختار استخراج را تثبیت کنید تا از بازپردازشهای غیرضروری جلوگیری شود.
- مدیریت از راه دور را جدی بگیرید: برای ماشینهایی که کنارشان نیستید، از Tailscale و سوئیچهای برق هوشمند استفاده کنید. اگر اهرم قدرت میخواهید، باید سختیهای مدیریت سختافزار را بپذیرید.
- مالکیت جراحیگونه: هوش مصنوعی محلی به معنای اجرای همه چیز زیر میز (مثل یک purist یا خاستهگرا) نیست. نسخه کاربردی آن «جراحیگونه» است: گلوگاه (Bottleneck) را مالک شوید و بقیه موارد را اجاره کنید.
این پروژه ثابت میکند که ارزشمندترین دارایی در عصر هوش مصنوعی لزوماً بهترین «پرومپت» نیست، بلکه توانایی تحمل هزینه اشتباه کردن است. با کاهش قیمت شکست، توسعهدهنده سریعتر حرکت کرد و محصولی مقاومتر از یک رویکرد کاملاً ابری ساخت. هوش مصنوعی محلی فقط برای چتباتها نیست؛ بلکه ماشینی برای پردازش دادههای دردناک است — از صوت و ویدیو گرفته تا PDFها، اسناد حقوقی، گزارشهای بازار، مقالات علمی و کاتالوگهای محصول — در مقیاسی که در غیر این صورت از نظر مالی غیرممکن میبود.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما درباره مدیریت حافظه در GPUهای سری ۴۰ مراجعه کنید.



گفتگو