
اگر قابلیتهای هوش مصنوعی شما «بیشتر اوقات» درست کار میکند اما در محیط واقعی شکست میخورد، احتمالاً به جای مهندسی، به شهود تکیه کردهاید. باید بدانید که تکیه بر حدس و گمان در طراحی دستورات، بزرگترین مانع برای تبدیل یک دموی جذاب به یک محصول تجاری قابلاعتماد است.
بسیاری از توسعهدهندگان به مدل زبانی بزرگ (LLM) — مثل کتابخانهداری که میلیاردها صفحه را خوانده و حالا با همان لحن جواب میدهد — به چشم یک ابزار ساده مینگرند و پرامپتنویسی را به عنوان یک اقدام تکمیلی میبینند. همانطور که در تحلیلهای پیشین ما دربارهی پایداری عاملهای هوش مصنوعی اشاره کردیم، این رویکرد در محیطهای حساس تجاری شکست میخورد. در این شرایط، سازگاری خروجی مدلها، بهخصوص در مدلهایی مثل gpt-4o-mini، غیرقابلمذاکره است.
به نقل از گزارش MarkTechPost، پایداری خروجیها زمانی افزایش مییابد که پنج مکانیسم مهندسی جایگزین آزمون و خطا شوند:
- پرامپتنویسی نقشمحور: استفاده از شخصیتهای خاص برای تغییر وزن دانش مدل؛ تا پاسخ از یک جواب کلی به یک تحلیل تخصصی تبدیل شود.
- پرامپت منفی: محدود کردن عبارات حشو، زبانهای تبلیغاتی و جملات محتاطانه برای رسیدن به حداکثر دقت.

- پرامپت JSON: تحمیل یک ساختار سختگیرانه برای تبدیل متنهای آزاد به دادههای ماشینخوان.
- پرسوجوابهای استدلالی متمرکز (ARQ): جایگزینی زنجیره تفکر باز با یک چکلیست ثابت از سؤالات ضروری برای تضمین پوشش کامل موضوع.
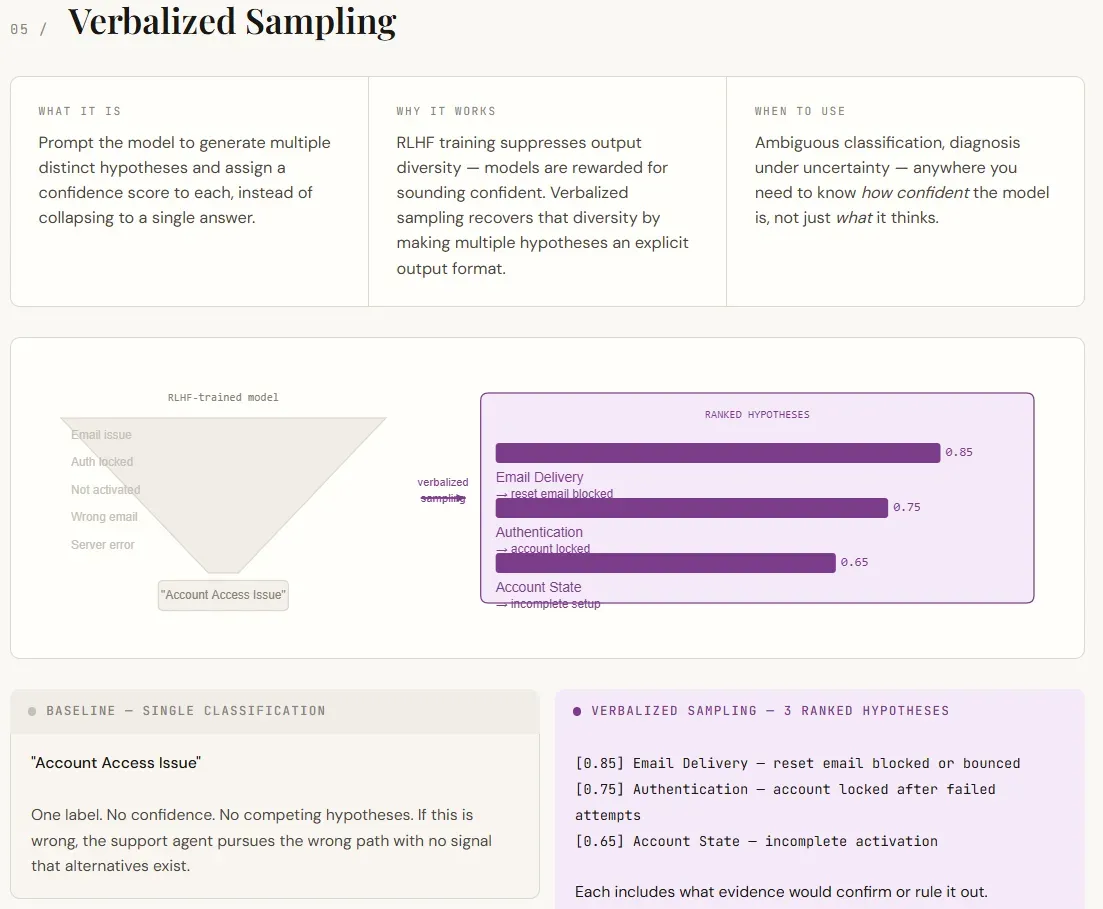
- نمونهبرداری کلامی: آشکار کردن تردیدهای داخلی مدل از طریق درخواست چندین فرضیه رتبهبندی شده و ارائه شواهد.

این تغییر رویکرد برای مدیران کسبوکار معنای مهمی دارد. دیگر نیازی به «نجارهای پرامپت» که با جادوگری دستورات را تغییر میدهند نیست. با اجرای ARQ و محدودیتهای JSON، تیمها میتوانند استدلال AI را ممیزی کنند. این کار نیاز به تنظیم دقیق (Fine-tuning) — که شبیه دادن تخصص پوست به یک پزشک عمومی است و هزینه زیادی دارد — را بهشدت کاهش میدهد.
گام بعدی شما
- تکنیکهای ARQ و JSON را در یک حلقه مقایسهای ساده با استفاده از OpenAI API تست کنید.
- این دستورات ساختاریافته را به چارچوبهای ارزیابی خودکار متصل کنید.
- نرخ خطای خروجیها را در مجموعهدادههای واقعی خود اندازه بگیرید.
اما این تنها بخشی از مسیر است؛ اثر این ساختارها بر کاهش هزینههای استنتاج (Inference) را در گزارش بعدی بررسی خواهیم کرد.



گفتگو