
تصور کنید یک عامل صوتی را که هیچ شباهتی به ماشین ندارد و احساسات را دقیقاً مانند یک انسان منتقل میکند. اگر هنوز فکر میکنید مدلهای کوچک نمیتوانند طبیعی باشند، Voxtral تمام باورهای شما را تغییر میدهد.
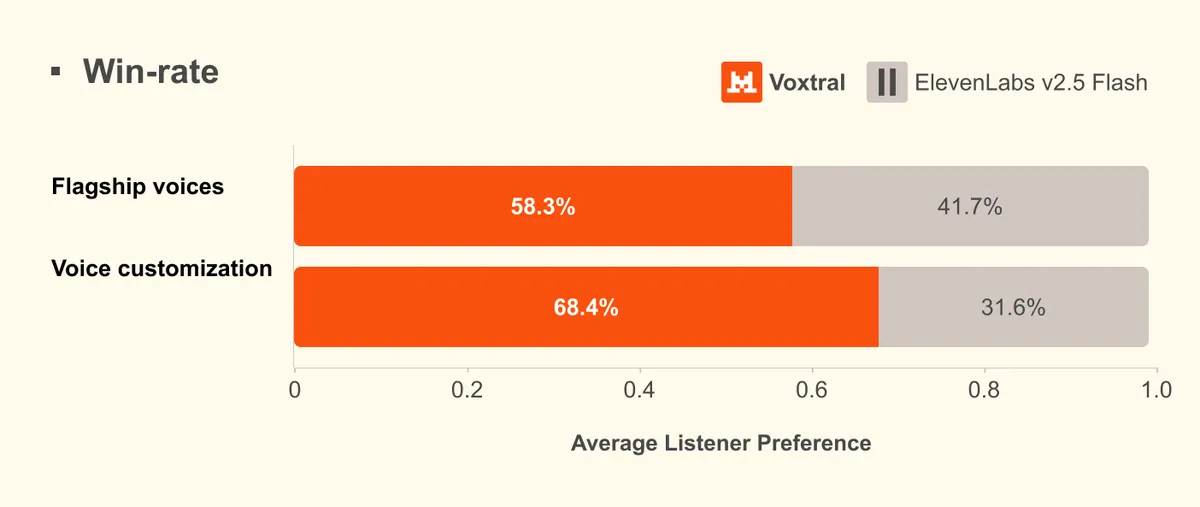
در ۲۸ آوریل ۲۰۲۶، شرکت Mistral AI از مدل Voxtral TTS پردهبرداری کرد؛ یک مدل سبک برای تولید گفتار که بهطور خاص برای عامل (Agent)های صوتی در مقیاس سازمانی طراحی شده است. به نقل از وبلاگ رسمی این شرکت، Voxtral در زمینه طبیعی بودن صدا از ElevenLabs Flash v2.5 پیشی گرفته و در کیفیت نهایی با نسخه v3 این رقیب برابری میکند.
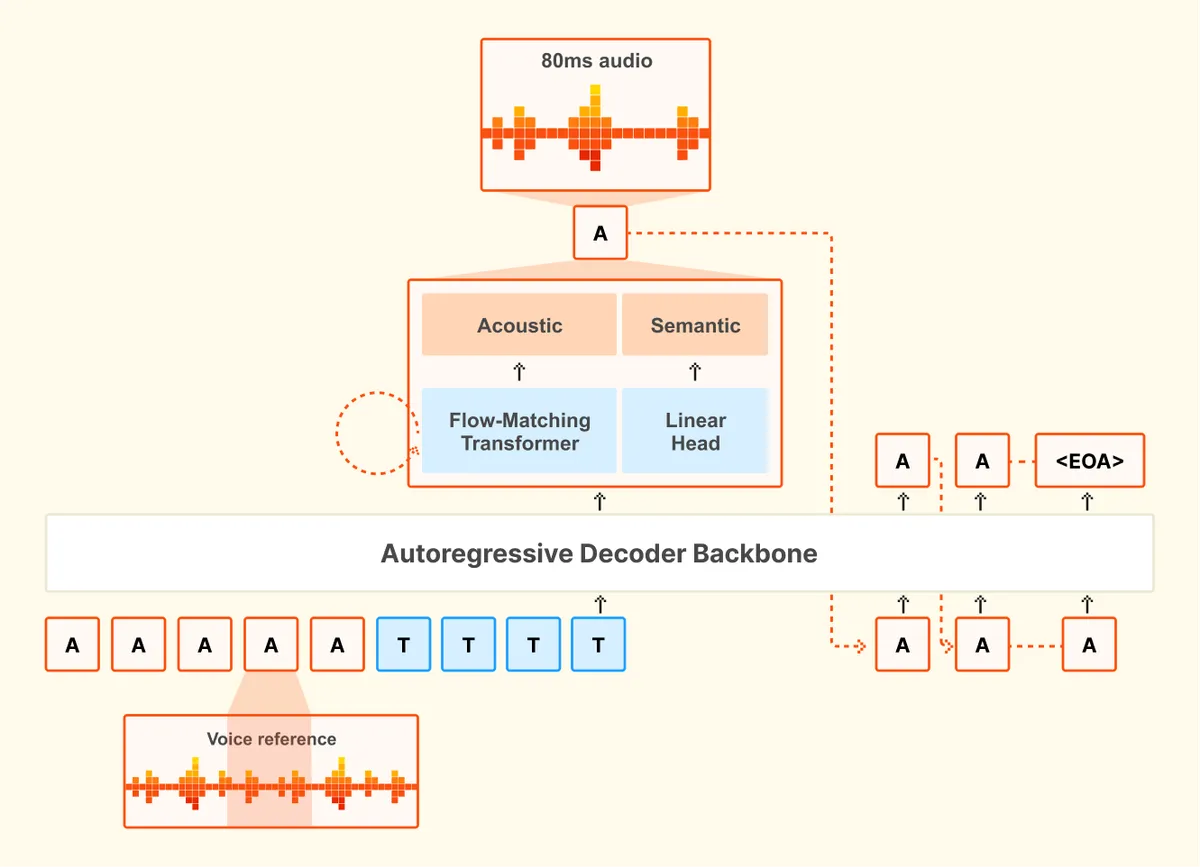
این مدل بر پایه معماری هوش مصنوعی زاینده (Generative AI) و با استفاده از ساختار autoregressive و flow-matching توسعه یافته است. مشخصات فنی این سیستم عبارت است از:
- یک بدنه دکودر transformer با ۳.۴ میلیارد پارامتر
- یک transformer صوتی flow-matching با ۳۹۰ میلیون پارامتر
- یک کدک صوتی عصبی (Neural Audio Codec) با ۳۰۰ میلیون پارامتر
طبق اعلام Mistral، این مدل برای سرعت خیرهکننده مهندسی شده است؛ بهطوری که برای یک ورودی ۵۰۰ کاراکتری، تأخیر استنتاج (Inference) تنها ۷۰ میلیثانیه است و نرخ زمان واقعی (RTF) آن حدود ۹.۷ برابر است. Voxtral از ۹ زبان از جمله انگلیسی، فرانسوی، آلمانی و عربی پشتیبانی میکند و میتواند تنها با یک کلیپ ۳ ثانیهای، صدای کاربر را شبیهسازی کند.
یکی از خیرهکنندهترین قابلیتهای این مدل، تطبیق صدای «صفر-شات» (Zero-shot) بینزبانی است. برای مثال، مدل میتواند متنی انگلیسی را با همان لهجه و ویژگیهای صوتی یک نمونه فرانسوی بخواند، حتی اگر برای این کار آموزش ندیده باشد. این ویژگی، Voxtral را به ابزاری قدرتمند برای سیستمهای ترجمه گفتار-به-گفتار تبدیل میکند.
همانطور که در تحلیل قبلی ما دربارهی استراتژی جسورانهی Mistral برای به چالش کشیدن سلطهی سیلیکونولی اشاره کردیم، این عرضه بخشی از یک نقشه راه بزرگتر است. Mistral با ارائه وزنهای باز (Open weights) تحت لایسنس CC BY NC 4.0 در Hugging Face، خود را به عنوان جایگزین اصلی برای سازمانهایی معرفی میکند که میخواهند مالکیت کامل زیرساخت صوتی خود را داشته باشند و به APIهای خارجی وابسته نباشند.
با حرکت به سمت خودمختاری کامل در صدا، نبرد بعدی بر سر ادغام این مدلهای باکیفیت در سختافزارهای رایانش لبه (Edge computing) با توان مصرفی پایین خواهد بود.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.
گام بعدی شما
- مدل Voxtral را در Hugging Face تست کنید تا کیفیت تطبیق صدا را بسنجید.
- قابلیت تطبیق بینزبانی را برای سناریوهای ترجمه آنی امتحان کنید.
- اثر کاهش تأخیر به ۷۰ میلیثانیه بر تجربه کاربری (UX) عاملهای صوتی خود را بررسی کنید.



گفتگو