
تصور کنید مدل زبانی کوچکی داشته باشید که بتواند پیچیدهترین مسائل ریاضی سطح دکترا را حل کند، آن هم در حالی که هزینه اجرای آن کسری از مدلهای غولپیکر است. اگر به دنبال جایگزینی برای سیستمهای بسته و گرانقیمت در حوزه تأیید رسمی کد هستید، Leanstral 1.5 دقیقاً برای همین هدف طراحی شده است.
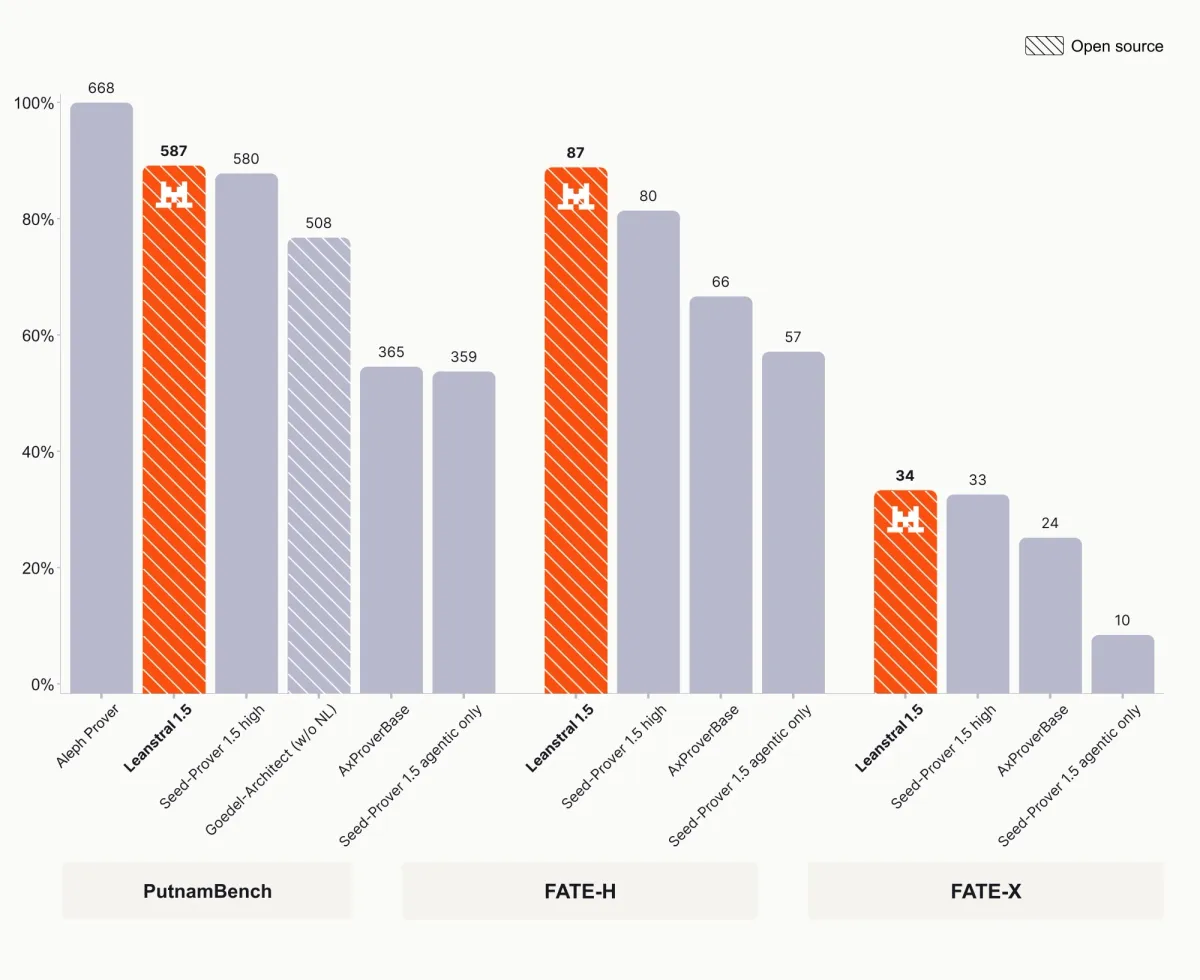
در ۳ جولای ۲۰۲۶، شرکت Mistral AI مدل Leanstral 1.5 را تحت لایسنس رایگان Apache-2.0 منتشر کرد. این مدل یک مدل تخصصی است که هدف آن کاربردی کردن تأیید رسمی (Formal Verification) برای کدهای دنیای واقعی و ریاضیات سطح بالا است. این مدل توانست ۵۸۷ مسئله از ۶۷۲ مورد در محک ریاضی PutnamBench را حل کند؛ دستاوردی که پیشتر تنها در اختیار سیستمهای بسیار بزرگتر و بسته بود.
تأیید رسمی (Formal Verification) — شبیه به داشتن یک حسابرس سختگیر که خطبهخط کد را با قوانین منطق چک میکند تا هیچ اشتباهی باقی نماند — به برنامهنویسان اجازه میدهد بهصورت ریاضی ثابت کنند کد دقیقاً همانطور که قصد شده عمل میکند و بدین ترتیب کل دستههای خاصی از باگها را بهطور کامل حذف کنند. طبق اعلام Mistral AI، در حالی که ابزارهایی مثل Lean 4 زبان لازم برای نوشتن این اثباتها را فراهم میکنند، اما تلاش دستی مورد نیاز برای نوشتن آنها یک مانع عظیم برای اکثر مهندسان بوده است. Leanstral 1.5 به عنوان یک عامل (Agent) تخصصی وارد میدان شده تا این فرآیند خستهکننده را خودکار کند.
همانطور که در تحلیلهای قبلی ما دربارهی امنیت مدلهای بازمتن اشاره کردیم، کاهش وابستگی به مدلهای بسته، دسترسی به ابزارهای دقیقتر را ممکن میکند. این مدل از معماری ترکیب خبرهها (Mixture of Experts) — مثل تیمی از متخصصان که فقط فرد لایق برای هر سؤال فراخوانده میشود — با مجموع ۱۱۹ میلیارد پارامتر بهره میبرد، اما در لحظهی استنتاج (Inference) — یعنی همان لحظهای که مدل واقعاً جواب تولید میکند، شبیه به خودِ آشپزی نه دورهی آموزش آن — تنها ۶ میلیارد پارامتر فعال هستند.
بر اساس مستندات Mistral، این بهرهوری باعث کاهش شدید هزینهها شده است. برای مثال، هزینه حل هر مسئله در PutnamBench برای Leanstral 1.5 حدود ۴ دلار است، در حالی که برای Seed-Prover 1.5 High، که برای هر مسئله از بودجهای معادل ۱۰ روز پردازشی H20 استفاده میکند، هزینه تخمینی ۳۰۰ دلار است. این رویکرد بهینه در مدیریت منابع، یادآور تلاشهای اخیر برای بهبود عملکرد عاملهای هوشمند با هزینهای بهمراتب کمتر است تا دسترسی به مدلهای پیشرو تسهیل شود.
آموزش و گردشکار عاملمحور
این مدل طی یک خط لوله سه مرحلهای شامل آموزش میانی (Mid-training)، تنظیم نظارتشده (SFT) — شبیه وقتی به یک پزشک عمومی تخصص پوست میدهیم تا در یک حوزه دقیق شود — و یادگیری تقویتی با استفاده از CISPO آموزش دیده است. مدل در دو محیط مجزای یادگیری تقویتی (RL) فعالیت گستردهای داشته است:
- محیط چند-پاسخی (Multiturn): در این محیط، صورت یک قضیه به مدل داده میشود و مدل باید آن را اثبات یا رد کند. مدل یک اثبات را ارسال میکند، بازخوردی از کامپایلر Lean دریافت میکند و رویکرد خود را بهصورت تکرارشونده اصلاح میکند تا زمانی که موفق شود یا بودجهی پردازشیاش تمام شود.
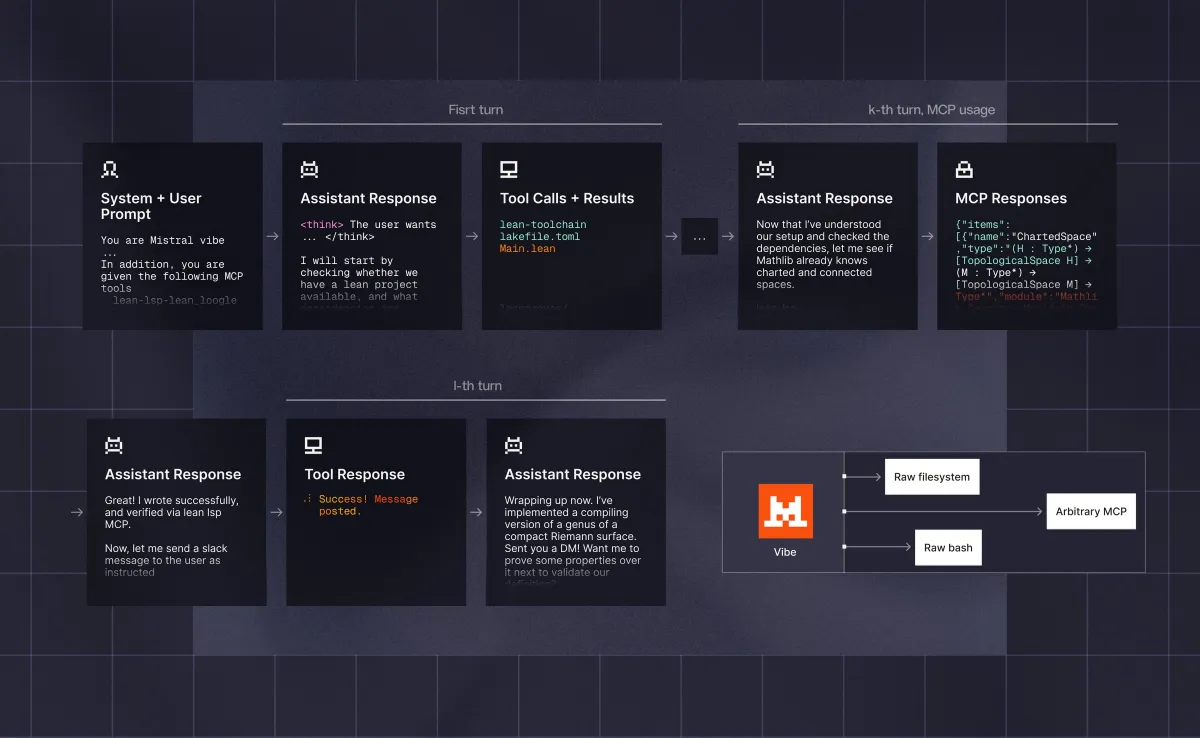
- محیط عامل کدنویسی (Code Agent): در اینجا Leanstral مانند یک توسعهدهنده در یک سیستم فایل خام عمل میکند. مدل میتواند فایلها را ویرایش کند، دستورات bash را اجرا نماید و از Lean Language Server برای بررسی اهداف (Goals)، خطاها و اطلاعات تایپ (Type Information) در زمان واقعی استفاده کند.
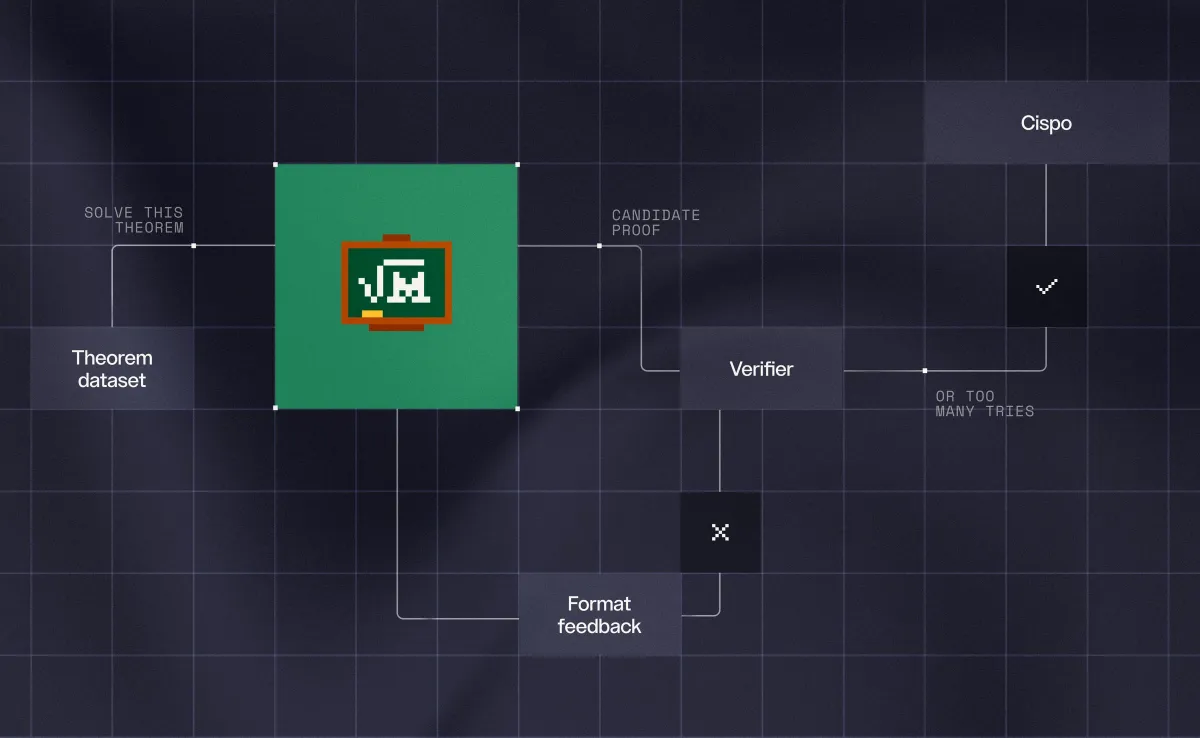
این رویکرد عاملمحور (Agentic) به مدل اجازه میدهد وظایف طولانیمدت (Long-horizon) را مدیریت کند؛ کارهایی مانند ساخت لمهای کمکی (Auxiliary Lemmas) و تکمیل اثباتهای ناقص در یک مخزن کد. با این حال، پیچیدگیهای این مدلهای عاملمحور میتواند نقاط ضعفی ایجاد کند که تلاشهایی برای شناسایی تقلب در بنچمارکهای آنها از طریق متدهای اصلاحی صورت گرفته است. برای تضمین صحت، خروجی نهایی توسط نسخهای شخصیسازی شده (Fork) از SafeVerify در برابر لیستی از قضایای هدف بررسی میشود.
عملکرد در محکهای جهانی
طبق گزارش Mistral، این مدل محک miniF2F را کاملاً اشباع کرده است. این محک یک تست بین-سیستمی برای ریاضیات رسمی است که طیفی از مسائل ابتدایی تا چالشهای سطح IMO در جبر و ترکیبیات را پوشش میدهد. Leanstral 1.5 در هر دو مجموعه اعتبارسنجی و آزمون به دقت ۱۰۰٪ رسیده است. همچنین در محکهای جبر انتزاعی پیشرفته که بر نظریه گروهها، حلقهها و مدلها تمرکز دارند، رکوردهای جدیدی ثبت کرده است:
- FATE-H (سطح تحصیلات تکمیلی): ۸۷٪ صحت.
- FATE-X (سطح دکترا): ۳۴٪ صحت.
در PutnamBench، که نیازمند استدلال عمیق و زنجیرههای اثباتی طولانی است، Leanstral 1.5 با اختلاف ۷ مسئله از Seed-Prover 1.5 High پیشی گرفت. در حالی که سایر اثباتگرها مانند Aleph Prover ممکن است رتبههای بالاتری داشته باشند، اما آنها تحت شرایط متفاوتی عمل میکنند؛ مثلاً راهنماییهای زبان طبیعی دریافت میکنند یا هزینه بسیار بیشتری دارند (۵۴ تا ۶۸ دلار برای هر مسئله). این نتایج در حالی به دست آمده که برخی بنچمارکهای ریاضی نشان میدهند مدلهای زبانی اغلب در مواجهه با براهین سادهتر دچار سوگیریهای خاصی میشوند.
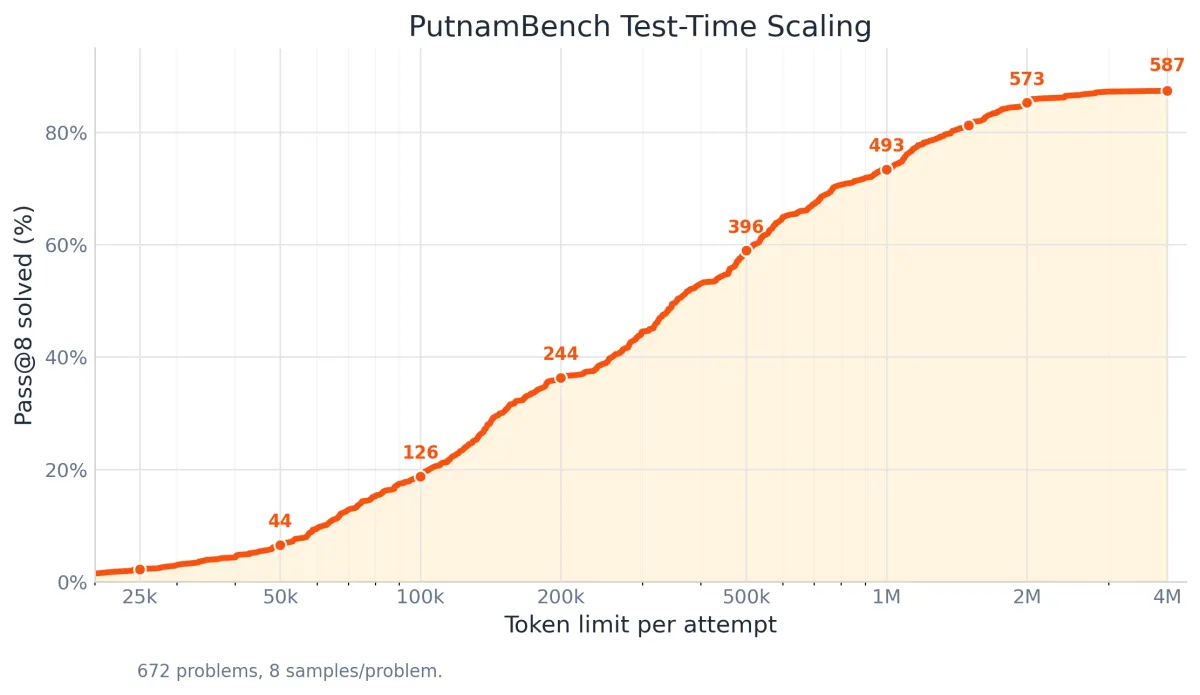
یکی از خیرهکنندهترین یافتهها، مقیاسبندی زمان استنتاج (Test-time Scaling) در این مدل است. با افزایش بودجهی توکن (Token) — تکههای کوچکی از متن شبیه برشهای کیک — تعداد مسائل حلشده بهصورت یکنواخت (Monotonically) افزایش یافت: در بودجه ۵۰ هزار توکنی، ۴۴ مسئله حل شد؛ در ۲۰۰ هزار توکن، ۲۴۴ مسئله؛ در یک میلیون توکن، عدد ۴۹۳ و در نهایت در بودجه ۴ میلیون توکنی، این رقم به ۵۸۷ مورد رسید. این نشان میدهد که دادن «زمان بیشتر برای فکر کردن» به مدل، مستقیماً به دقت بالاتر تبدیل میشود.
تأیید کد در دنیای واقعی
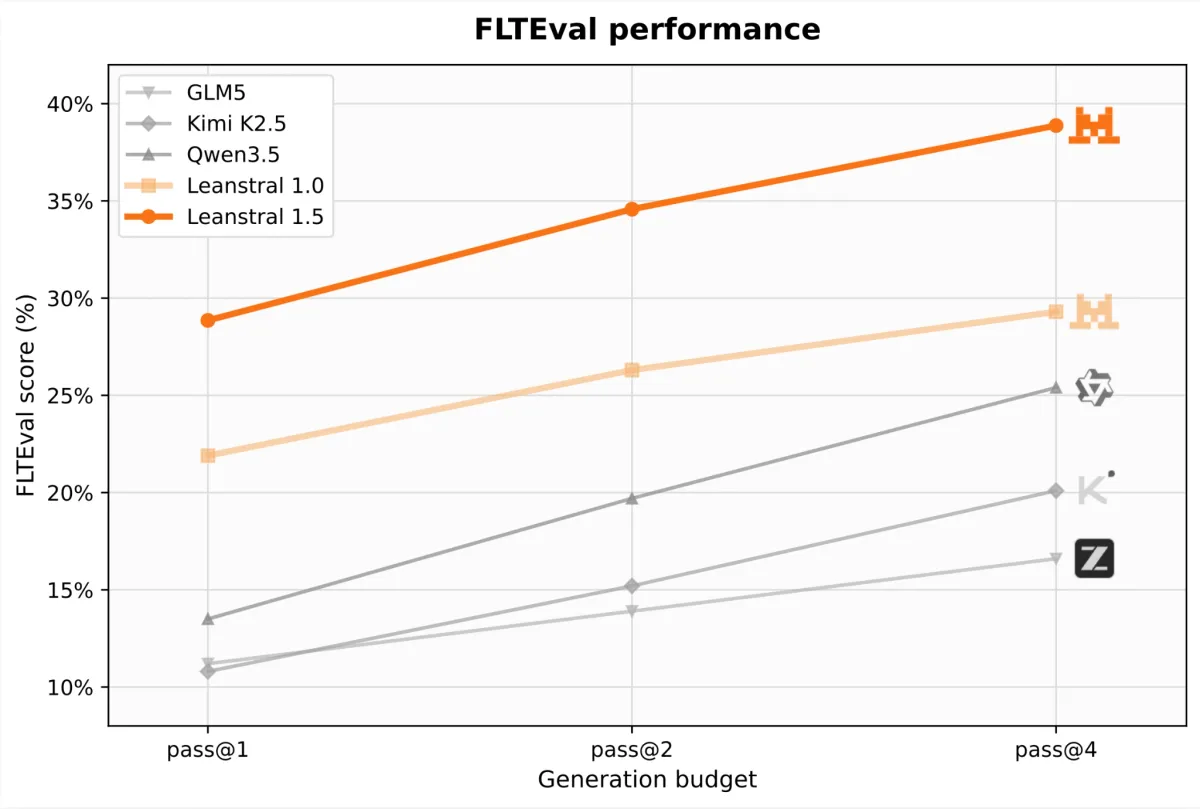
فراتر از ریاضیات نظری، Leanstral 1.5 روی مهندسی نرمافزار کاربردی نیز آزمایش شد. Mistral همچنین ابزار FLTEval را که بر اساس درخواستهای واقعی (Pull Requests) از مخزن قضیه آخر فرمات طراحی شده، بهصورت کاملاً بازمتن منتشر کرد. Leanstral 1.5 در این محک، معیار pass@1 را از ۲۱.۹ به ۲۸.۹ رساند و در pass@8 به ۴۳.۲ دست یافت؛ این نتیجه حتی از مدل Opus 4.6 با دقت ۳۹.۶ پیشی گرفت، در حالی که هزینه آن تنها یک هفتم بود.
در یک مورد مطالعه خاص، مدل پیچیدگی زمانی O(log n) را برای یک پیادهسازی واقعی درخت AVL تأیید کرد. این کار نیازمند استقراء ساختاری (Structural Induction) برای بازتاب دادن ساختار بازگشتی درخت و تحلیل جامع موارد برای مسیرهای بازتعادل (Rebalancing Paths) بود. طی ۲.۷ میلیون توکن و ۲۲ بار فشردهسازی بافت (Context Compaction)، مدل بهطور سیستماتیک TimeM monad را باز کرد تا کرانی معادل ۴۸ گام به ازای هر واحد ارتفاع بهعلاوه یک مقدار ثابت برای درج (Insertion) ایجاد کند.
برای شکار باگها، Mistral از یک خط لوله خودکار شامل Aeneas برای تبدیل کد Rust به Lean استفاده کرد و سپس از Leanstral برای استنباط قصد کاربر و تولید ویژگیهای correctness بهره برد. مدل سعی میکند هر ویژگی را چهار بار اثبات کند؛ اگر هر چهار تلاش شکست بخورند، مدل سعی میکند «نقیض» آن ویژگی را چهار بار اثبات کند. در بررسی ۵۷ مخزن تست شده، این روش ۴۷ مورد نقض ویژگی و ۱۱ باگ واقعی را شناسایی کرد:
- کشف باگ: ۵ مورد از این باگها پیشتر در گیتهاب گزارش نشده بودند.
- مثال: یک باگ در تابع sign برای رمزگشایی zigzag در کتابخانه
datrs/varinteger. در ورودی Std.U64.MAX، عبارت (value + 1) دچار سرریز (Overflow) میشد که باعث کرش در حالت debug و تخریب خاموش (Silent Corruption) در حالت release میگشت.
تحلیل: گذار به نرمافزارهای تأیید شده
برای حوزه هوش مصنوعی، Leanstral 1.5 تمرکز را از تولید کد «محتمل» (Plausible) به صحت «اثباتشده» (Proven) تغییر میدهد. اکثر دستیاران کدنویسی قطعه کدهایی را پیشنهاد میدهند که «به نظر» درست میرسند؛ اما Leanstral 1.5 طراحی شده تا تضمین کند که آنها «واقعاً» درست هستند. این امر معیار جدیدی برای قابلیت اطمینان در نرمافزارهای حساس (Mission-critical) مانند سیستمهای هوافضا یا مالی ایجاد میکند.
شرکت Mistral با باز کردن وزنهای مدل و محک FLTEval، در تلاش است تا تأیید رسمی را به یک کالای تجاری و دسترسپذیر (Commoditize) تبدیل کند. اگر ۶ میلیارد پارامتر فعال بتوانند مدلهای ۳ تا ۱۰ برابر بزرگتر را شکست دهند، مانع ورود به توسعه نرمافزارهای تأیید شده بهشدت کاهش مییابد. دیگر توسعهدهندگان برای بهرهگیری از این ابزارها نیازی به داشتن مدرک دکترا در منطق رسمی ندارند.
گام بعدی شما
- مدل را از طریق Hugging Face یا API رایگان
leanstral-1-5امتحان کنید. - Mistral توصیه میکند از مدل در محیط «Vibe» استفاده نمایید.
- برای فعالسازی قابلیتهای کامل عاملمحور، سرور
lean-lspرا با افزودن آن به تنظیمات~/.vibe/config.tomlو تعیینtool_timeout_secروی ۶۰۰ نصب کنید. - بودجه توکنهای استنتاج را افزایش دهید تا قدرت استدلال مدل در مسائل دشوار را مشاهده کنید.
اما تأثیر این مدل بر آینده توسعه نرمافزار و جایگزینی تستهای سنتی با اثباتهای ریاضی تازه در آغاز است؛ برای درک بهتر این روند، تحلیل ما درباره پروتکلهای جدید همکاری مدلها را بخوانید.



گفتگو