
اگر هنوز تصور میکنید تحلیل ۱۰۰ صفحه سند فنی یا یک ساعت ویدئو نیازمند مدلهای غولپیکر است، سخت در اشتباهید. طبق اعلام رسمی انویدیا (NVIDIA) در ۲۸ آوریل ۲۰۲۶، مدل Nemotron 3 Nano Omni معرفی شد تا ثابت کند هوشمندی لبه میتواند بر ابعاد مدل غلبه کند.
به نقل از گزارش منتشر شده در HuggingFace، این مدل چندوجهی (Multimodal) با وزنهای باز (Open Weights)، در تحلیل اسناد با تراکم بالا و تعاملات عاملمحور (Agentic) با رابطهای گرافیکی، بهطور مداوم از رقیبی چون Qwen3-Omni پیشی گرفته است.
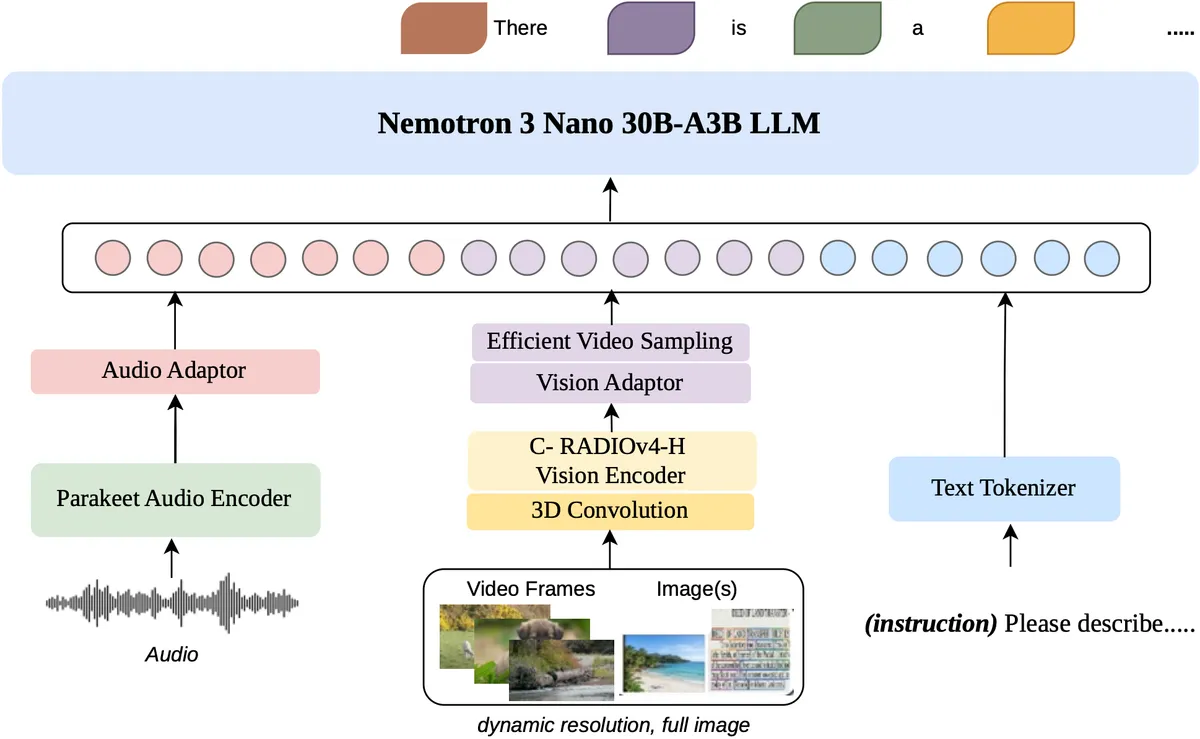
قلب تپنده این مدل، یک معماری ترکیبی از Mamba-Transformer-MoE است. این ساختار شامل ۲۳ لایه Mamba برای پردازش بهینه متون طولانی، ۲۳ لایه MoE و ۶ لایه توجه پرسوجوی گروهی است تا قدرت بیان جهانی مدل حفظ شود.
برای مدیریت ورودیهای متنوع، انویدیا از رمزگذارهای تخصصی استفاده کرده است:
- بینایی: رمزگذار C-RADIOv4-H با رزولوشن پویا، جزئیات دقیق در اسناد متنی (OCR) را حفظ میکند.
- صوت: رمزگذار Parakeet-TDT-0.6B-v2 پردازش بومی صوت را برای محتواهای بیش از ۵ ساعت ممکن ساخته است.
- ویدئو: مسیر Conv3D tubelet به همراه نمونهبرداری بهینه ویدئو (EVS)، توکنهای ایستا و تکراری را حذف کرده تا تأخیر در استنتاج (Inference) به شدت کاهش یابد.
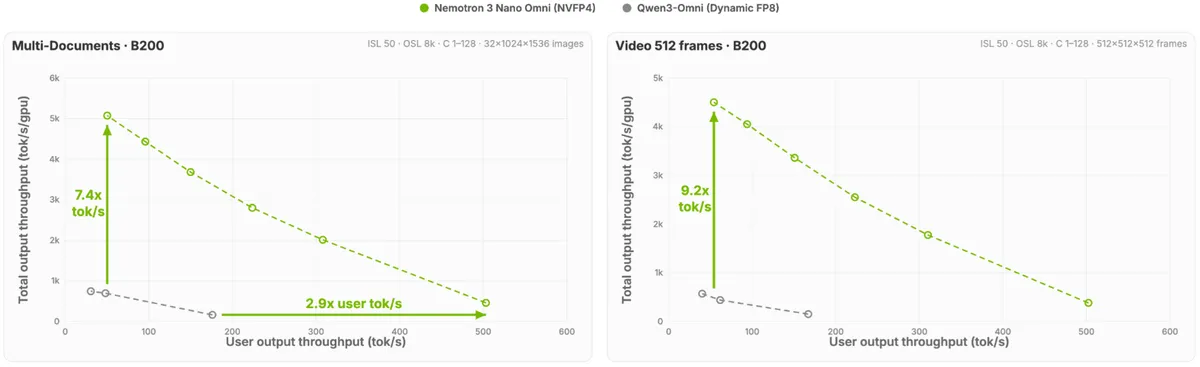
همانطور که در تحلیل قبلی ما دربارهی مدلهای زبانی کوچک (SLM) اشاره کردیم، بهینهسازی برای سختافزار لبه، اولویت اصلی سال ۲۰۲۶ است. این رویکرد در Nemotron 3 منجر به افزایش ۷.۴ برابری کارایی در تحلیل اسناد چندگانه و ۹.۲ برابری سرعت در وظایف ویدئویی شده است.
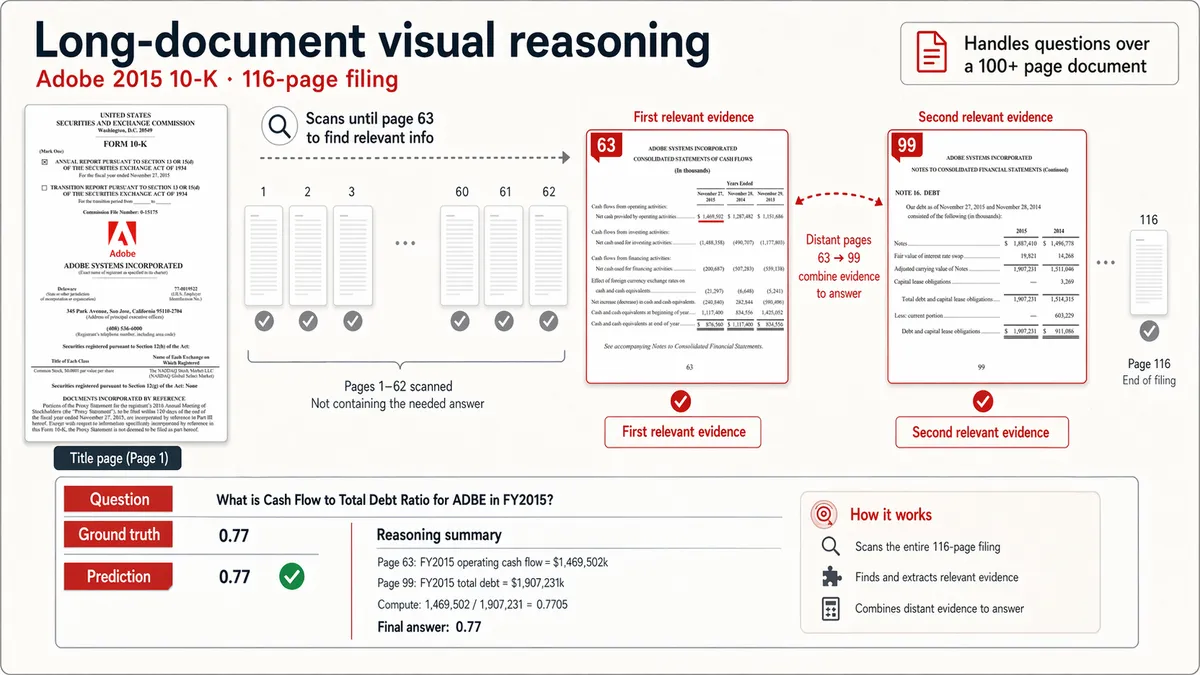
این مدل بهویژه برای اسناد «آشفته» مانند قراردادهای حقوقی و بستههای انطباق طراحی شده است؛ جایی که درک چیدمان صفحه و ارجاعات متقاطع، کلید موفقیت است.
بر اساس مستندات فنی، استفاده از دادههای مصنوعی (شامل ۱۱.۴ میلیون جفت پرسش و پاسخ) از طریق NeMo Data Designer، دقت استدلال مدل در تحلیل اسناد را ۲.۱۹ برابر افزایش داده است.
اما این تنها بخشی از پازل است؛ تأثیر این معماری بر کاهش هزینههای استنتاج در مراکز داده را در گزارش بعدی بررسی خواهیم کرد.
گام بعدی شما
- بررسی مدل Nemotron 3 در HuggingFace برای تحلیل اسناد پیچیده سازمانی.
- تست قابلیتهای Agentic مدل در محیطهای GUI برای اتوماسیون گردش کار.
- مقایسه خروجیهای تحلیل ویدئویی این مدل با Qwen3-Omni در پروژههای واقعی.



گفتگو