
دقت در طراحی سختافزار دیگر یک گمان یا احتمال نیست، بلکه به یک واقعیت قابل اثبات تبدیل شده است. تیم پژوهشی انویدیا (NVIDIA Research) با معرفی HORIZON ثابت کرد که میتوان توالیهای پیچیده طراحی مدارات مجتمع را بدون دخالت انسان و با دقت مطلق به سرانجام رساند. این سیستم، وعدهی طراحی سختافزار خودکار را از مرحلهی «تولید کدهای محتمل» به مرحلهی «صحت تأیید شده» منتقل کرده است.
بر اساس گزارش فنی منتشر شده در arXiv (شماره ۲۶۰۶.۲۸۲۷۹)، این چارچوب یک «عامل بدون دست» (hands-free agent) است که با طراحی سطح انتقال ثبات (RTL) نه به عنوان یک پاسخ تکمرحلهای به یک دستور (prompt)، بلکه به عنوان یک تکامل مستمر از یک مخزن گیت (Git repository) برخورد میکند. سیستم HORIZON در تمامی مجموعههای محک RTL که مورد ارزیابی قرار گرفتند، به نرخ موفقیت ۱۰۰٪ دست یافت.
طراحی سختافزار برای مدلهای زبانی بزرگ (LLM) چالشی منحصربهفرد ایجاد میکند؛ زیرا صحت در اینجا بر اساس نحو یا سینتکس کد نیست، بلکه بر رفتار در سطح کلاک (cycle-level behavior)، قراردادهای ریست و عرض دقیق بیتها استوار است. تولید کدهای سنتی در یک مرحله (single-turn) اغلب منجر به تولید کدهای Verilog «پlausible» یا محتمل میشود که در مرحله شبیهسازی با شکست مواجه میگردند. HORIZON این مشکل را با پیادهسازی یک حلقه بسته حل میکند که در آن عامل با ابزارهای واقعی EDA، شبیهسازها و سیستمهای کنترل نسخه تعامل دارد تا به صورت تکرارشونده کارهای خود را اصلاح کند. این رویکرد تکرارشناسانه در تضاد با مدلهای zero-shot است؛ برای مثال، سیستم ASPIRE در اجرای تکالیف پیچیده روباتیک تنها به موفقیت ۳۱ درصدی دست یافته بود که نشان میدهد برای وظایف حساس، تکیه بر یک پاسخ واحد کافی نیست.
مکانیسم: مخزن به عنوان وضعیت (State)
برخلاف دستیارهای کدنویسی هوش مصنوعی استاندارد، HORIZON روی یک فایل واحد عمل نمیکند. این سیستم هر مسئله طراحی را به عنوان یک مخزن تحت کنترل نسخه با استفاده از درختهای کاری ایزوله گیت (isolated git worktrees) میزبانی میکند. این فرآیند با یک بستر (harness) ساختاریافته در قالب Markdown آغاز میشود که شامل چهار جزء حیاتی است:
- یک هدف یا مقصد مشخص برای طراحی.
- دستورالعملهای مربوط به دانش دامنه (مانند قراردادهای خاص برای ریست).
- مشخصات ارزیاب (جریان دقیق کامپایل و شبیهسازی).
- یک عبارت پذیرش (Acceptance Predicate) که دقیقاً شرط «پاس کردن» را تعریف میکند.
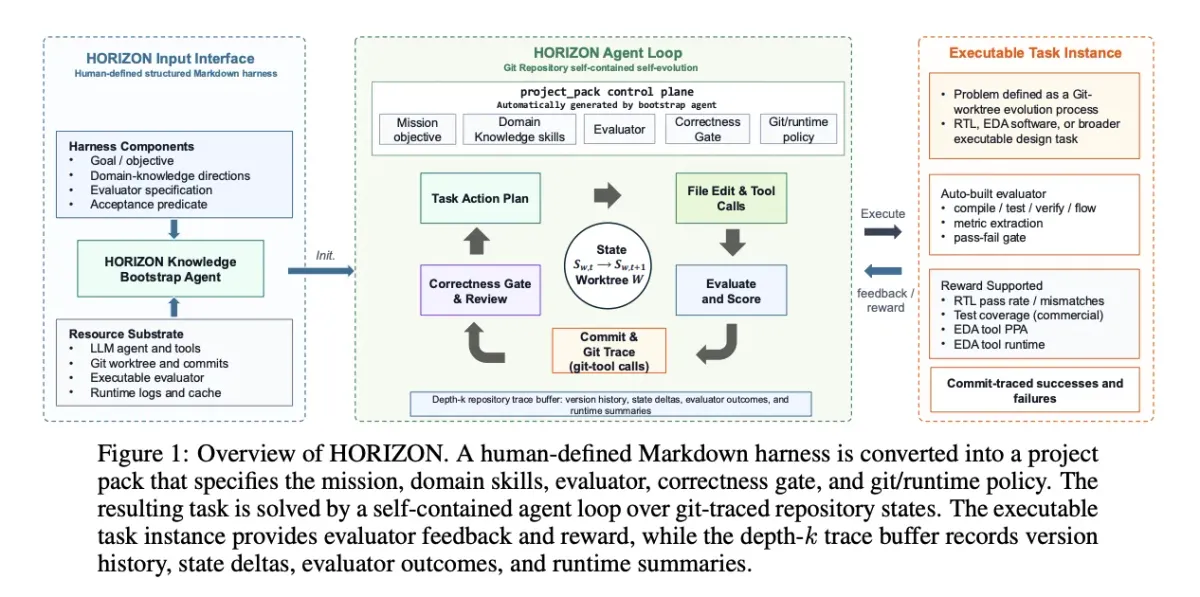
یک عامل پیشراه انداز (bootstrap agent)، این بستر را به یک «بسته پروژه» تبدیل میکند. تیم پژوهشی این بسته را به صورت ریاضی به شکل $p = (\pi_{agent}, E_p, A_p, \Gamma_p, \Omega_p)$ تعریف میکنند. در این فرمول، هر عبارت به یک رکن اشاره دارد: $\pi_{agent}$ سیاست عامل، $E_p$ ارزیاب اجرایی، $A_p$ عبارت پذیرش، $\Gamma_p$ سیاست کنترل نسخه و $\Omega_p$ مهارتهای تخصصی دامنه است.
در وظایف RTL، ارزیاب ($E_p$) معمولاً شامل مراحل کامپایل، شبیهسازی، استخراج پوشش (coverage extraction) و بررسیهای مربوط به assertion یا تستبنچها است. معماری این سیستم بسیار انعطافپذیر است؛ به گونهای که در دامنههای دیگر، همین بخش ارزیاب میتواند جایگاه اثباتکنندههای قضایا (theorem provers)، پروفایلرها یا ابزارهای سنتز را داشته باشد. این بدان معناست که مسائل به طور کلی بر روی درختهای کاری گیت تعریف میشوند و محدود به یک نوع مخزن خاص نیستند. این استفاده از رابطهای کد-محور برای تعامل با ابزارها، یادآور رویکرد مدل SpatialClaw است که در آن رابطهای کد-محور باعث افزایش دقت فضایی در مدلهای بینایی-زبانی شدهاند.
حلقه در سطح مخزن (Repository-Level Loop)
پس از راهاندازی، این حلقه بدون هیچ دخالت انسانی اجرا میشود. در هر چرخه، عامل ابتدا یک هدف را برنامهریزی میکند، سپس درخت کاری (worktree) را ویرایش کرده، ابزارها را فرا میخواند و در نهایت ارزیاب را اجرا میکند. عبارت پذیرش سپس یک نتیجه واحد را تعیین میکند: اگر عملیات موفق بود، نسخه جدید کامیت (commit) میشود و در غیر این صورت، شکست در گزارشها ثبت میگردد.
گیت در اینجا نه تنها یک ابزار برای ثبت وقایع، بلکه زیربنای بنیادین سیستم است. سیستم از دستورات بومی گیت برای ارزان کردن ردیابی تغییرات استفاده میکند:
- Diffs: برای نمایش تغییرات پیشنهادی در وضعیت کد (مثلاً استفاده از
git diff --cached). - Commits: برای تعریف نقاط بازرسی (checkpoints) پذیرفته شده.
- Notes: برای پیوست کردن شواهد ارزیاب و احکام نهایی (مثلاً:
git notes add -m "pass=1 mismatches=0"). - Logs: برای بازیابی کامل مسیر تکامل از طریق دستور
git log --oneline.
این معماری باعث میشود تاریخچه مخزن به یک «بافر تجربه» تبدیل شود. کامیتهای موفق به عنوان نمونههای اصلاحی مثبت و تلاشهای رد شده به عنوان نمونههای منفی ثبت میشوند. سیستم برای نامگذاری این قراردادها از واژگان «فرآیند تصمیمگیری نیمهمارکوف» (semi-Markov decision process) استفاده میکند: یک «وضعیت» (state) همان snapshot نسخهبندی شده از مخزن است و یک «گزینه» (option) هر اپیزود بین دو نقطه بازرسی است. نکته قابل توجه این است که مدل پشتیبان یا همان GPT-5.3 در طول تمام عملیات ثابت میماند و سیستم هیچ پالیسی یادگیری تقویتی (RL) را آموزش نمیدهد یا بهروزرسانی نمیکند.
عملکرد در محکها و اقتصاد توکنها
سیستم HORIZON روی یک میزبان AMD EPYC 9334 با ۳۲ هسته پردازشی و ۵۱۲ گیگابایت رم آزمایش شد. ارزیابیها بر روی مجموعههای ChipBench، RTLLM-2.0، Verilog-Eval-v2 و ۹ دسته از مجموعه CVDP (از CID 002 تا 016) انجام شد که شامل ۷۸۳ مسئله طراحی شده توسط انسان (Pinckney et al., 2025) است.
یک «تکرار» (iteration) به عنوان یک گام خارجی خودکار تعریف میشود: ویرایش درخت کاری، اجرای ارزیاب و در نهایت کامیت یا رد کردن تغییرات. نتایج نشاندهنده اشباع کامل صحت در تمامی موارد است:
- ChipBench: از نرخ ۲۰.۰٪ در تکرار صفر به completion ۱۰۰٪ رسید.
- RTLLM-2.0: از نرخ ۷۸.۰٪ به completion ۱۰۰٪ رسید.
- Verilog-Eval-v2: از نرخ ۸۶.۲٪ به completion ۱۰۰٪ رسید.
- CVDP CID 013 (تولید بررسیکننده): از ۳.۸٪ شروع شد و با پیشروی تدریجی در تکرار ۱۹ام به ۱۰۰٪ رسید.
- CVDP CID 002 (تکمیل کد): به ۱۰۰٪ رسید اما به ۸۲ تکرار نیاز داشت.
در حالی که صحت کد به ۱۰۰٪ رسید (به جز یک مورد باقیمانده که ناشی از نقص در بستر مشخصات ChipBench بود)، هزینه توکنی به شدت متغیر بود. دشواری همگرایی بسته به دسته مسئله متفاوت است؛ در حالی که RTLLM-2.0 در دو تکرار همگرا میشود، «دم بلند» (long tail) تکمیل کد در CID 002 بیشترین هزینه توکنی را ایجاد کرد.
مصرف توکن اصلیترین حوزهای است که نیاز به بهبود دارد. سه مجموعه قدیمی مجموعاً ۶ میلیون توکن مصرف کردند، اما ۹ دسته از CVDP حدود ۲۰۳.۹ میلیون توکن بلعیدند (یعنی ۹۷.۱٪ از کل هزینه). تنها مورد CID 002 حدود ۵۶ میلیون توکن مصرف کرد. برای کاهش این فشار، HORIZON یک نشست مدل (model session) پایدار را در طول تکرارها نگه میدارد. بستر (harness) و بسته پروژه از حافظه موقت (prompt cache) ارائهدهنده سرویس خوانده میشوند، به گونهای که ۹۱٪ از توکنهای ورودی کش شدهاند و هزینههای جدید عمدتاً مربوط به diff فعلی و آخرین خروجی ارزیاب است.
کاربردهای عملی در جریانهای کاری RTL
قابلیتهای HORIZON مستقیماً با وظایف روزمره مهندسی RTL التطبیقی همراستا است:
- تکمیل کد RTL (CID 002): تبدیل تکمیلهای شکستخورده به طراحیهای سالم و پاسکننده.
- تبدیل مشخصات متنی به RTL (RTLLM-2.0, CID 003): پیادهسازی یک ماژول بر اساس یک مشخصه نوشتاری.
- اصلاح و بازاستفاده (CID 004, CID 005): ویرایش یا تطبیق RTLهای موجود تحت آزمایش.
- Linting و بهبود کیفیت نتایج/QoR (CID 007): پاکسازی کدهایی که توسط بستر شناسایی شدهاند.
- تولید محصولات تأییدیه (CID 012 تا 014): تولید محرکهای تستبنچ (stimulus)، بررسیکنندهها و assertions.
- عیبیابی/Debugging (CID 016): مکانیابی و رفع باگهای عملکردی با استفاده از بازخورد شبیهساز.
به عنوان مثال، در تولید بررسیکنندهها (checker generation) که مدلهای تکگامه (single-shot) معمولاً در آن شکست میخورند، HORIZON تا زمانی که بررسیکننده عبارت پذیرش تعریفشده را پاس نکند، در برابر شبیهسازیهای EDA تجاری تکرار میکند و بدین ترتیب خستهکنندهترین بخشهای چرخه تأییدیه را خودکار میسازد.
تحلیل: تغییر در استانداردهای محک سختافزار
این تغییر رویکرد از «Pass@1» (موفقیت در اولین تلاش) به «نرخ همگرایی» (Convergence Rate)، فرض بنیادین هوش مصنوعی در EDA را تغییر میدهد. HORIZON در واقع ادامه زنجیرهای از تکامل خودکار در مقیاس مخزن است. در حالی که سیستمهای پیشین مانند AlphaEvolve (2025) روی هستههای الگوریتمیک و SATLUTION (2025) روی مخازن SAT-solver تکامل یافتند، HORIZON مستقیماً روی مصنوعات سختافزاری (Artifacts) اثر میگذارد.
| سیستم | شیء تکاملیافته | دامنه | سیگنال ارزیابی |
|---|---|---|---|
| AlphaEvolve | هستههای الگوریتمیک | اکتشافات علمی | ارزیابهای خودکار |
| SATLUTION | مخازن SAT-solver | حل SAT | صحت و زمان اجرا |
| ABCEvo (2026) | سنتز منطقی ABC | نرمافزارهای EDA | صحت و QoR |
| HORIZON | منابع RTL / تستبنچها | طراحی سختافزار | کامپایل، شبیهسازی، پوشش |
در میدان فنی، این پژوهش ثابت میکند که گلوگاه دیگر دانش اولیه مدل نیست، بلکه کیفیت حلقه بازخورد است. با این حال، تیم پژوهشی اذعان میکنند که طراحی سختافزاری عاملمحور هنوز «حل» نشده است. ریسک «سوءاستفاده از پاداش» (reward hacking) همچنان وجود دارد؛ یعنی ممکن است یک عامل بتواند شرطهای ظاهری بستر را پاس کند بدون اینکه واقعاً تمام مشخصات فنی را برآورده سازد.
علاوه بر این، در حالی که بازخورد شبیهسازی سریع است، حلقههای مربوط به توان، عملکرد و مساحت (PPA) میتوانند روزها یا هفتهها زمان ببرند. پوشش فعلی سیستم مشاهدهای است؛ برای مثال، CID 012 با پوشش متوسط ۹۷.۹٪ پاس میشود چون به محض پاس کردن، فرآیند متوقف میشود. کیفیت نتایج سنتز (QoR) هنوز بهینه نشده است. برای پیشرفت در این مسیر، محققان یک پروتکل دو سطحی را پیشنهاد میدهند: استفاده از بازخوردهای تشخیصی برای تعمیر کد، و رزرو تستهای تصادفی پنهان و بررسیهای رسمی (formal checks) برای امتیازدهی نهایی.
گام بعدی شما
- اگر مهندس سختافزار هستید، جریانهای کاری خود را از تولید تکگامه به مدلهای تکرارشونده (Iterative) تغییر دهید.
- ابزارهای شبیهسازی خود را به گونهای پیکربندی کنید که خروجیهای ساختاریافته برای مصرف توسط مدلهای زبانی فراهم کنند.
- برای کاهش هزینهها، از استراتژیهای Prompt Caching در ابزارهای Agentic استفاده کنید.
اما تأثیر این رویکرد بر طراحی تراشههای نسل بعد و بهینهسازی مصرف انرژی حتی پیچیدهتر است — به بررسی ما درباره معماریهای جدید شتابدهنده مراجعه کنید.



گفتگو