
گلوگاه استدلال مکانی در مدلهای بینایی-زبانی (VLMs)، نه در هوش مدل، بلکه در رابطهای است که برای اقدام استفاده میکند. NVIDIA Research با معرفی SpatialClaw، یک چارچوب بدون نیاز به آموزش (Training-free)، فراخوانیهای سخت JSON را با یک هسته پایتونی پویا و دارای وضعیت (Stateful) جایگزین کرد تا عاملها بتوانند کد را بهعنوان رابط اصلی اقدام خود ببینند.
این پیشرفت، وصلهای حیاتی برای مدلهایی است که بهطور تاریخی در تشخیص روابط سهبعدی اشیاء و تحلیل حرکت آنها در طول زمان مشکل داشتند. با تکیه بر پوشش قبلی ما درباره اینکه چگونه مدل Gemma3-4B از طریق تفکر مبتنی بر بینایی با مدلهای بزرگتر رقابت کرد، SpatialClaw نشان میدهد که نحوه تعامل یک عامل با ابزارهای ادراکی به اندازه خودِ مبنیسازی (Grounding) اهمیت دارد. این رویکرد تکاملیافته برای بهبود درک محیطی است که پیشتر در چارچوب AlloSpatial با تغییر نگاه از دوربین به نقشه مورد بررسی قرار گرفته بود تا دقت استدلال مکانی افزایش یابد. برای توسعهدهندگان، این تغییر شبیه انتقال از یک منوی محدود و ثابت از دستورات به یک محیط توسعه یکپارچه (IDE) کامل است که در آن هوش مصنوعی میتواند منطق هندسی خود را بنویسد، اجرا کند و در صورت بروز خطا، آن را اشکالزدایی نماید.
به نقل از مقاله پژوهشی منتشرشده در spatialclaw.github.io، این چارچوب بهعنوان یک حلقه عامل (Agent Loop) عمل میکند که در اطراف یک هسته Jupyter دائمی بستهبندی شده است. این سیستم اساساً «بدون نیاز به آموزش» است؛ به این معنا که همان پرامپتها و ابرپارامترها (Hyperparameters) بدون نیاز به تنظیم دقیق (Fine-tuning) روی مدلهای پایه (Backbones) مختلف جواب میدهند. این ویژگی به تیمها اجازه میدهد مدلهای مستقر شده را بدون نیاز به جمعآوری مجموعهدادههای جدید، گسترش دهند.
معماری فنی و توابع اولیه
SpatialClaw بر یک حلقه پنجمرحلهای متکی است: برنامهریزی، تولید کد، اجرای کد، مجموع بازخوردهای دریافتی (Feedback Assembly) و ارسال پاسخ نهایی. هسته سیستم پیشازاین با فریمهای ورودی و مجموعهای از توابع اولیه (Primitives) بارگذاری شده است که در آن ابزارهای ادراکی صرفاً بهعنوان توابع قابل فراخوانی پایتون (Python Callables) تعریف شدهاند. این هسته ۶ نقطه دسترسی عمومی را در اختیار مدل قرار میدهد:
- InputImages: نگهدارنده فریمهای نمونهبرداری شده از ویدئو یا تصاویر.
- Metadata: حامل دادههای حیاتی مانند نرخ فریم (Frame Rate)، مدتزمان و شاخصهای فریم.
- tools: ارائه ابزارهای ادراکی و توابع پایه هندسی.
- show(): درج یک تصویر در زمینه (Context) بعدی عامل برای بررسی بصری.
- vlm: ارسال پرسوجوها به یک نشست (Session) مجزای مدل بینایی-زبانی.
- ReturnAnswer(): ارسال و ثبت پاسخ نهایی.
برای مدیریت ادراک، این سیستم چندین ابزار کلیدی را یکپارچه میکند:
- tools.Reconstruct: این ابزار Depth Anything 3 را در بر میگیرد تا عمق هر فریم، پارامترهای داخلی (Intrinsics) و خارجی (Extrinsics) دوربین و نقشههای نقطهای متراکم (Dense Point Maps) را فراهم کند.
- tools.SAM3: بهرهگیری از مدل SAM 3 برای تولید ماسکهای تصویری یا ویدئویی از طریق پرامپتهای متنی، نقاط یا کادرهای مشخص (Box Prompts).
- Utility Modules: شامل ابزارهای سبکوزن برای محاسبات هندسه، مدیریت ماسکها، زمان، گرافها و ترسیمات.
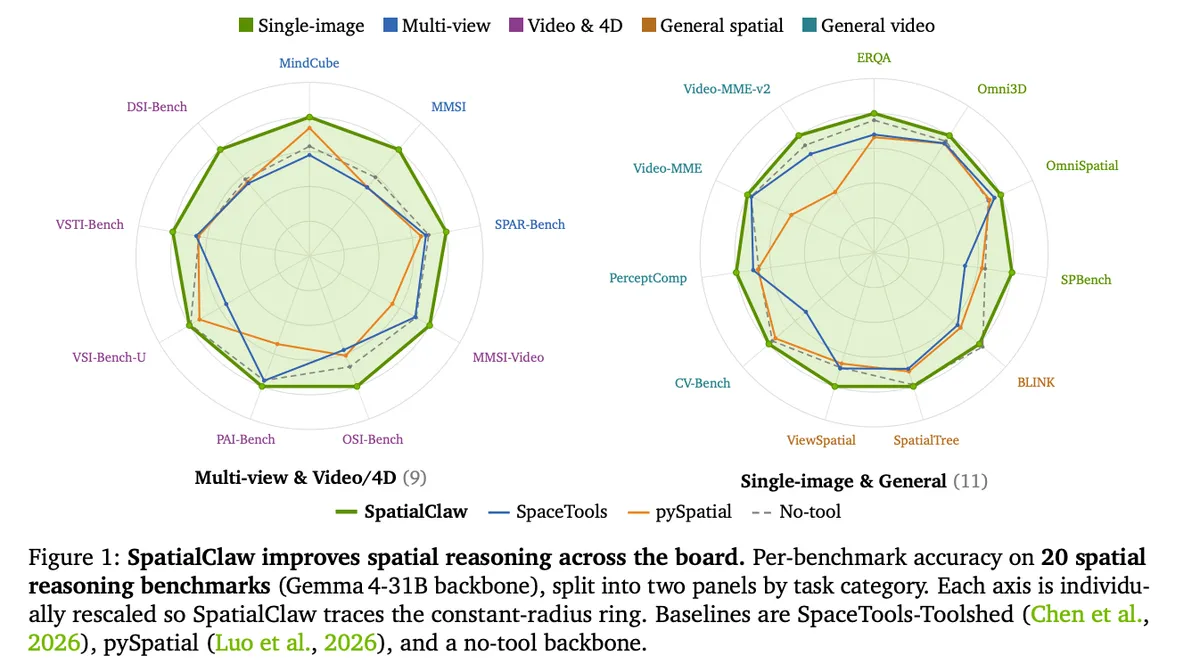
این سیستم از یک بررسیکننده AST استاتیک استفاده میکند تا کدهای ناامن را پیش از اجرا رد کند. حلقه تکرار تا زمانی ادامه مییابد که دستور ReturnAnswer() فراخوانی شود یا ۳۰ گام زمانی بگذرد. این چارچوب از طیف وسیعی از مدلهای پایه، از ۲۶ میلیارد تا ۳۹۷ میلیارد پارامتر، شامل خانوادههای Qwen3.5/3.6 و Gemma4 پشتیبانی میکند. طبق گزارش انویدیا، در مدل Gemma4-31B، این سیستم به میانگین صحت ۵۹.۹٪ در ۲۰ محک (Benchmark) رسید که نشاندهنده افزایش ۶.۵ امتیازی نسبت به حالت پایه بدون ابزار است.
اثر ترکیب کدها
تیم انویدیا برای ایزوله کردن «اثر رابط»، سه روش مختلف را روی یک پرسش واحد مقایسه کرد: تولید کد تکمرحلهای (Single-pass)، فراخوانیهای ساختاریافته ابزار (Structured tool-calls) و ترکیب تکرارشونده کدهای SpatialClaw. در سناریویی برای اندازهگیری فاصله بین یک بخاری و یک در، رویکرد تکمرحلهای پیش از دیدن ماسک مربوطه، استراتژی خود را تثبیت میکند و به آن پایبند میماند، در حالی که فراخوانیهای ساختاریافته نمیتوانند خروجیها را آزادانه با استفاده از کتابخانههایی مانند NumPy یا SciPy ترکیب کنند.
اما SpatialClaw میتواند ابزارها را ترکیب کند، نتایج را بازرسی نماید و در صورت نیاز کد را اصلاح کند. به عنوان مثال، این عامل ممکن است ابتدا فاصله مرکز ثقل (Centroid distance) را محاسبه کند، سپس متوجه شود که محاسبه مرکز ثقل از «میانه» استفاده میکند و برای یافتن نزدیکترین نقطه واقعی، رویکرد خود را به scipy.spatial.KDTree تغییر دهد. در این آزمایش خاص، مدل مقدار ۰.۹۴۳۹ متر را در برابر داده مرجع (Ground Truth) ۰.۹ متر ثبت کرد.
نتایج بهدستآمده بسیار واضح بود. در حالی که فراخوانیهای ساختاریافته به صحت ۵۶.۷٪ رسیدند، SpatialClaw این عدد را به ۵۹.۹٪ رساند. مقایسه عاملهای مختلف روی مدل Gemma4-31B شکاف عمیقی را نشان میدهد:
- VADAR (تکمرحلهای): ۴۰.۵٪ (۱۹.۴- نسبت به SpatialClaw)
- pySpatial (تکمرحلهای): ۴۷.۸٪ (۱۲.۱- نسبت به SpatialClaw)
- SpaceTools-Toolshed (فراخوانی ساختاریافته): ۴۸.۷٪ (۱۱.۲- نسبت به SpatialClaw)
- SpatialClaw (کد بهمثابه اقدام): ۵۹.۹٪
تحلیلهای صورتگرفته توسط مدل زبانی بهمثابه داور (LLM-as-a-judge) نشان داد که ۵۲.۲٪ از این پیروزیها مستقیماً به دلیل قابلیت «ترکیب کدها» (Code Composition) بوده است. جریان کنترل (Control Flow) ۱۹.۵٪ و موارد خنثی از نظر رابط ۲۸.۳٪ اثر داشتند.
عملکرد در محکها و کاربردهای عملی
SpatialClaw در ۲۰ محک در پنج دسته مختلف آزمایش شد: تک-تصویر، چند-نمایی، عمومی، ویدیو/۴D و درک کلی ویدیو. این قابلیت در وظایف پویا مشهودتر است. در DSI-Bench صحت ۱۷.۶ امتیاز و در MindCube ۱۵.۳ امتیاز افزایش یافت؛ چراکه این بنچمارکها نیازمند محاسبات هندسی زنجیرهای در چندین فریم و زاویه دید مختلف هستند.
از منظر فنی، این موضوع این فرضیه قدیمی را میشکند که شکستهای مکانی صرفاً مربوط به ضعف در ادراک (Perception) هستند. اگرچه ادراک همچنان سقف نهایی عملکرد است، اما «شکاف رابط» توضیح میدهد چرا بسیاری از مدلها در وظایفی شکست میخورند که از نظر تئوریک ابزارهای لازم برای حل آنها را در اختیار دارند. انویدیا با اجازه دادن به عامل برای تامل روی یک نقشه عمق یا ماسک و سپس بازنویسی رویکرد خود، استدلال مکانی را از یک مشکل پرامپتنویسی به یک مسئله مهندسی نرمافزار تبدیل کرده است.
کاربردهای عملی و عینی این معماری عبارتند از:
- رباتیک: عاملهای تجسمیافته (Embodied Agents) که پیش از اقدام فیزیکی، فواصل متری دقیق بین اشیاء را اندازه میگیرند.
- بازرسی چند-نمایی: بازیابی دقیق جهت قرارگیری یا زاویه یک شیء با استفاده از چندین زاویه دوربین.
- تحلیل ۴D: ردیابی دقیق حرکت اشیاء یا جابجایی دوربین در طول فریمهای زمانی.
- پرسشوپاسخ داخلی: تعیین روابط مکانی پیچیده، مانند «در نسبت به سینک در چه موقعیتی قرار دارد؟»
برای کسانی که در حوزه هوش مصنوعی تجسمیافته یا رباتیک فعالیت میکنند، این به معنای آن است که فواصل متری و مسیرهای دوربین (Camera Trajectories) را میتوان با دقت بالاتر و بدون هزینه سنگین بازآموزی مدل بازیابی کرد. شما اکنون میتوانید مدل بینایی-زبانیای مستقر کنید که پیش از هر اقدام فیزیکی، درک سهبعدی خود از محیط را بهصورت تکرارشونده اصلاح و پالایش کند.
برای بررسی پیادهسازی، مخزن رسمی در گیتهاب تحت عنوان NVlabs/SpatialClaw در دسترس است که یک گردشکار مبتنی بر LangGraph و یک سرویس FastAPI برای ابزارهای ادراکی GPU فراهم میکند. کاربران میتوانند با کلون کردن مخزن، تنظیم محیط از طریق اجرای spatial_agent/scripts/setup.sh و استفاده از ماژول spatial_agent.entrypoints.run بنچمارکها را اجرا کنند.
گام بعدی شما
- بررسی مخزن
NVlabs/SpatialClawدر گیتهاب برای پیادهسازی ابزارهای ادراکی در پروژههای رباتیک. - تست مدلهای خانواده Gemma4 در ترکیب با هسته پایتون برای کاهش خطای تخمین فاصله.
- مطالعه مستندات Depth Anything 3 برای درک بهتر نحوه تولید نقشههای عمق در این چارچوب.
اما تأمین سختافزاری این حجم از استنتاج تکرارشونده چالش جدیدی است؛ برای درک معماری شتابدهندههای جدید انویدیا، تحلیل ما درباره تراشههای Blackwell را بخوانید.



گفتگو