
تصور کنید در یک اتاق اورژانس شلوغ، تصمیم نهایی را نه یک پزشک با ۲۰ سال تجربه، بلکه یک مدل زبانی بگیرد. این دیگر یک سناریوی علمی-تخیلی نیست، بلکه واقعیت جدیدی است که OpenAI خلق کرده است.
در ۳ مه ۲۰۲۶، یک مقاله پیشچاپ فاش کرد که مدل استدلالی (Reasoning Model) o1 در چندین بنچمارک پزشکی و مواجهههای واقعی در اتاق اورژانس، عملکرد بهتری نسبت به پزشکان انسانی داشته است.
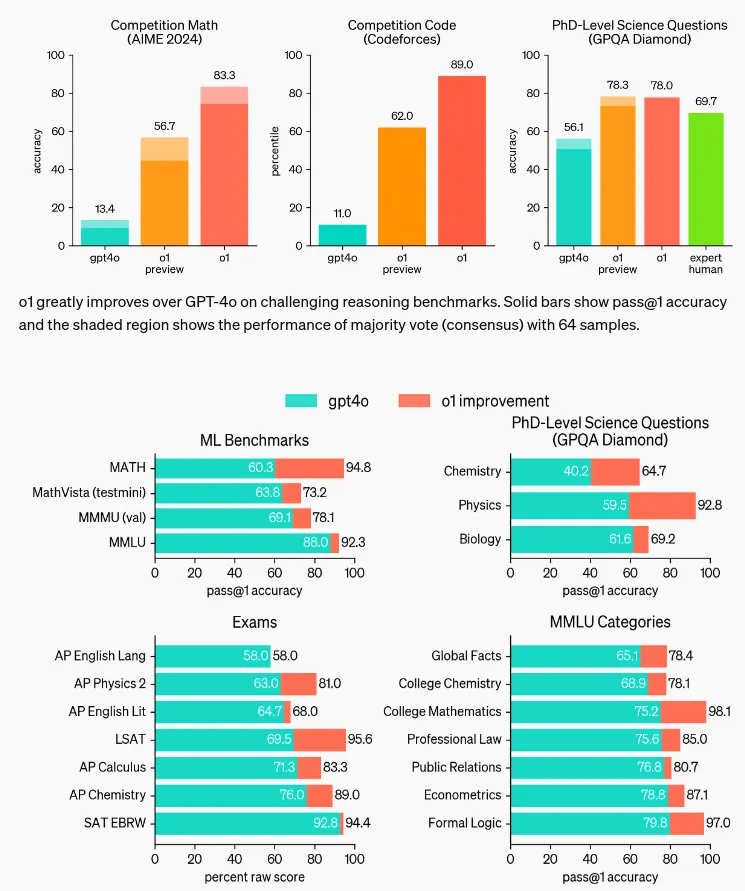
به نقل از مقالهای که توسط @emollick به اشتراک گذاشته شد، این مدل در زمینههایی چون دقت تشخیص، توصیههای درمانی و وظایف استدلال بالینی درخشیده است. نکته حیاتی این است که این نتایج صرفاً یک تمرین آزمایشگاهی نبودند، بلکه شامل پروندههای واقعی بیماران میشدند که به نتایج، اعتبار بالینی مستقیم میبخشد.
یافتههای کلیدی این مطالعه عبارتاند از:
- o1 در تمامی سناریوهای آزمایششده، هم از پزشکان انسانی و هم از مدلهای قدیمیتر پیشی گرفت.
- این موفقیت از طریق استنتاج (Inference) در زمان اجرا به دست آمده، نه از طریق تنظیم دقیق (Fine-tuning) تخصصی پزشکی.
- معماری زنجیره تفکر (Chain-of-Thought) یک مزیت ساختاری در محیطهای بالینی ایجاد میکند، جایی که منطق گامبهگام حیاتی است.
همانطور که در تحلیلهای پیشین ما دربارهی گذار از مدلهای پیشبینیکننده به مدلهای استدلالی اشاره کردیم، قدرت این سیستمها در «فکر کردن» پیش از پاسخ دادن نهفته است. با این حال، بر اساس مستندات این مقاله، پژوهشگران در مورد دادهها کاملاً شفاف نبودند؛ نه امتیازات دقیق بنچمارکها ذکر شده و نه تعداد پزشکان گروه کنترل مشخص است. همچنین، هیچ گزارشی از تحلیل خطاها یا احتمال وقوع اشتباهات فاجعهبار در موارد خاص (Edge Cases) ارائه نشده است.
این تحول، تغییری بنیادین در مسیر پیشرفت AI است. در حالی که مدلهای پیشین مانند GPT-4 یا Med-PaLM 2 گوگل تنها در وظایف خاص به سطح پزشکان نزدیک میشدند، o1 با اولویت دادن به استدلال بهجای تطبیق الگو، از این مرز عبور کرده است.
به دلیل اینکه بنچمارکها جایگزین استقرار واقعی نیستند، نویسندگان بر «نیاز فوری به آزمایشهای آیندهنگر» تأکید دارند. شما باید منتظر انتشار کامل این مقاله در arXiv باشید تا ببینید آیا استدلال این مدل در برابر اعتبارسنجیهای سختگیرانه بالینی دوام میآورد یا خیر.
اما این پیروزی فنی، تنها نیمی از داستان است؛ چالشهای اخلاقی و حقوقی این جایگزینی را در گزارش بعدی بررسی خواهیم کرد.
گام بعدی شما
- انتشار کامل مقاله در arXiv را دنبال کنید تا جزئیات نرخ خطا (Error Rate) را بررسی کنید.
- عملکرد o1 را در تحلیل پروندههای پیچیده پزشکی (در محیطهای شبیهسازی شده) تست کنید.
- منتظر معرفی نسخهی تخصصی پزشکی o1 توسط OpenAI باشید.



گفتگو