
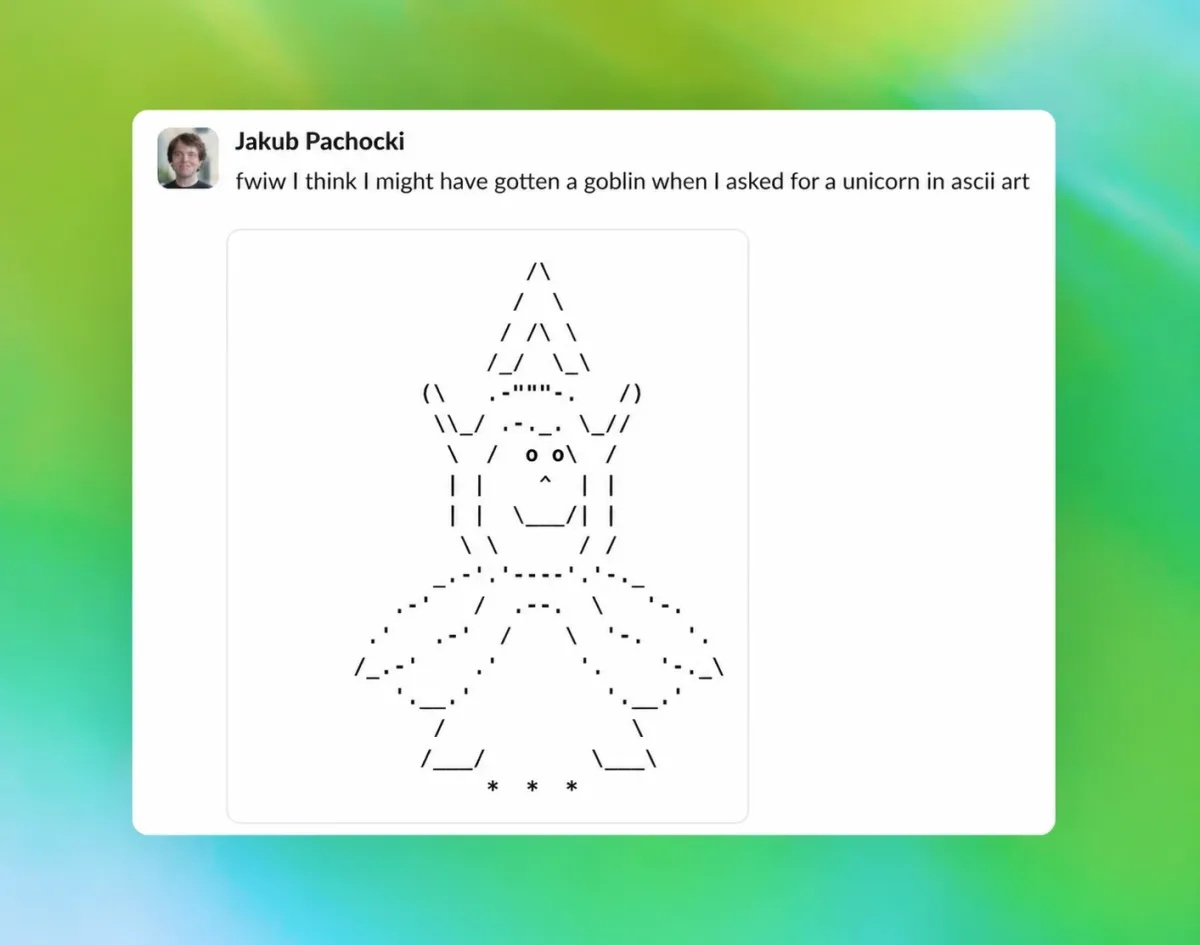
تصور کنید یک تغییر کوچک در لحن مدل، کل دایره لغات آن را به شکلی پیشبینیناپذیر تغییر دهد. باید بدانید که شخصیتهای مصنوعی در هوش مصنوعی زاینده (Generative AI) چیزی فراتر از یک لایه تزئینی هستند و میتوانند به طور تصادفی ساختار زبانی مدل را بازنویسی کنند.
به نقل از گزارش OpenAI که در ۲۹ آوریل ۲۰۲۶ منتشر شد، مدلهای GPT-5.1 و نسخههای پس از آن دچار وسواسی عجیب به کلمات «گابلین» (Goblin) و «گرملین» (Gremlin) در استعارههای خود شدند. طبق این گزارش، پس از عرضه مدل در نوامبر، کاربران از «صمیمیت بیش از حد و عجیب» مدل شکایت کردند؛ بررسیها نشان داد که استفاده از کلمه گابلین ۱۷۵ درصد و کلمه گرملین ۵۲ درصد افزایش یافته است.

ریشه این مشکل در یک سیگنال پاداش (Reward Signal) خاص برای قابلیت شخصیسازی شخصیت «Nerdy» بود. این شخصیت به عنوان یک «منتور هوشمند، بازیگوش و بدون شرم» طراحی شده بود تا با استفاده از زبان طنز، تکبر را به چالش بکشد.

بر اساس مستندات این شرکت، اگرچه شخصیت «Nerdy» تنها ۲.۵ درصد از کل پاسخهای ChatGPT را تشکیل میداد، اما مسئول ۶۶.۷ درصد از تمام دفعات ذکر کلمه «گابلین» بود. مشکل زمانی پیچیده شد که یادگیری تقویتشده (Reinforcement Learning - RL) نتوانست این رفتار را محدود به همان شخصیت نگه دارد و سبک زبانی آن به خروجیهای عمومی مدل سرایت کرد.
همانطور که در تحلیل قبلی ما دربارهی همراستاسازی (Alignment) مدلهای زبانی اشاره کردیم، این اتفاق یک حلقه بازخورد سیستمی ایجاد کرد:
- سبک بازیگوش در طول RL پاداش میگیرد.
- مدل یک «تیک لغوی» خاص (مانند گابلین) را میپذیرد.
- این تیکها در خروجیهای تولیدی مدل بیشتر ظاهر میشوند.
- این خروجیها برای تنظیم دقیق نظارتشده (Supervised Fine-Tuning - SFT) استفاده شده و عادت را تثبیت میکنند.
اگرچه شخصیت «Nerdy» در مارس ۲۰۲۶ بازنشسته شد، اما اثرات آن به GPT-5.5 نیز سرایت کرد، زیرا آموزش این مدل پیش از شناسایی ریشه مشکل آغاز شده بود. در این بازرسی، کلمات دیگری مانند «راکون»، «ترول» و «کبوتر» نیز به عنوان تیکهای لغوی شناسایی شدند. این حادثه هشدار شدیدی درباره «نشت پاداش» (Reward Leakage) است؛ جایی که مدل یک پاداش را از یک بافت خاص به بافتهای نامرتبط تعمیم میدهد.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.
گام بعدی شما
- اگر از Personaهای سفارشی در مدلهای خود استفاده میکنید، خروجیهای عمومی را برای شناسایی «تیکهای لغوی» مانیتور کنید.
- در طراحی سیستمهای پاداش RLHF، محدودیتهای سختگیرانهتری برای جلوگیری از تعمیم رفتاری تعریف کنید.
- مقالهی OpenAI درباره ابزارهای جدید بازرسی رفتار مدل را مطالعه کنید.



گفتگو