
باید بدانید که بخش بزرگی از قدرت محاسباتی مدلهای زبانی بزرگ صرف پردازش مقادیر صفر میشود؛ اتلافی که تا امروز در معماریهای استاندارد GPU نادیده گرفته میشد. تصور کنید در هر گام محاسباتی، منابع سختافزاری برای دادههایی هزینه شود که عملاً هیچ تأثیری در خروجی ندارند.
این شکاف بهرهوری حتی در حالی رخ میدهد که صنعت به سمت ابزارهای قابلیت اطمینان قطعی (Deterministic Reliability) حرکت میکند؛ موضوعی که همانطور که در تحلیلهای پیشین ما دربارهی استقرار مدلهای صنعتی اشاره کردیم، برای مقیاسپذیری حیاتی است. چالش اصلی این بود که هزینه تبدیل دادههای متراکم به فرمتهای پراکنده (Sparse)، معمولاً تمام سود سرعت را میبلعید.
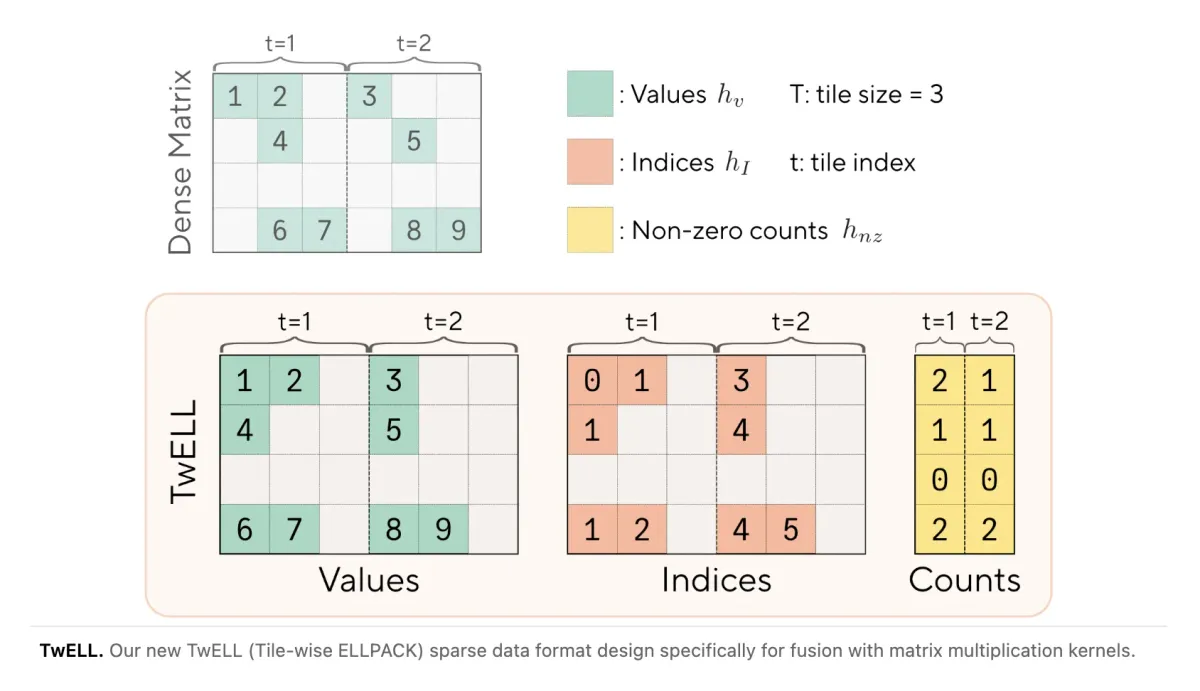
به نقل از گزارش MarkTechPost، تیم مشترک Sakana AI و NVIDIA این مشکل را با انتقال فرآیند تبدیل مستقیماً به بخش اپیلوگ (Epilogue) کرنل GPU حل کردهاند. این همکاری بخشی از استراتژی گستردهتر انویدیا برای حذف گلوگاههای محاسباتی است؛ مشابه آنچه در تلاشهای اخیر این شرکت برای شتابدهی به مدلهای استدلالی از طریق Speculative Decoding مشاهده کردیم. آنها TwELL (Tile-wise ELLPACK) را معرفی کردند؛ فرمتی که ستونها را به کاشیهای افقی متناسب با اندازه کرنل ضرب ماتریسی تقسیم میکند. این سازوکار به سیستم اجازه میدهد بدون نیاز به خواندن مجدد حافظه یا ایجاد سربار همگامسازی، از نورونهای با مقدار صفر عبور کند.
بر اساس مستندات منتشر شده، برای پیادهسازی این روش، دو تغییر جزئی در دستورالعمل آموزش اعمال شده است:
- جایگزینی تابع فعالساز SiLU با ReLU برای تولید صفرهای دقیق.
- افزودن یک ترم ضرر L1 (با ضریب ۲ در ۱۰ به توان منفی ۵) به تابع ضرر استاندارد برای القای پراکندگی.
بنچمارکهای اجرا شده روی یک نود شامل هشت پردازنده H100 PCIe GPU نشان میدهد که بهرهوری با افزایش اندازه مدل رشد میکند. برای یک مدل ۲ میلیارد پارامتری، تیم موفق به ثبت ۲۰.۵ درصد افزایش سرعت در استنتاج (Inference) و ۲۱.۹ درصد افزایش سرعت در آموزش شد. این تلاش برای بهینهسازی استنتاج، در راستای رویکردهای مشابهی است که تیم Qwen برای کاهش هزینههای پردازشی در کانتکستهای بلند به کار گرفت.
این دستاورد فرضیه قدیمی را که «پراکندگی بدون ساختار» تنها برای استنتاجات تک-توکنی (GEMV) مفید است، میشکند. TwELL ثابت میکند که رژیمهای با توان عملیاتی بالا را میتوان بدون تغییر در معماری ترنسفورمر بهینه کرد. نکته کلیدی این است که افزایش سرعت در پردازندههای RTX PRO 6000 حتی بیشتر است، که نشان میدهد سد ورود برای کسانی که از سختافزارهای کمتر تخصصی استفاده میکنند، بهشدت پایین آمده است.
گام بعدی شما
- بررسی مقالات فنی TwELL برای پیادهسازی ReLU و L1 Loss در مدلهای کوچک خود.
- رصد کارهای آتی این تیم در زمینه تنظیم دقیق (Fine-tuning) پراکندگی برای مدلهای پیشآموزشدیده متراکم.
- تحلیل اثر این بهینهسازی بر کاهش هزینههای عملیاتی در محیطهای ابری.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell و معماری جدید انویدیا مراجعه کنید.



گفتگو