
اگر تصور میکنید عاملهای هوش مصنوعی میتوانند بهسادگی کدهای قدیمی سازمان شما را به نسخههای مدرن منتقل کنند، اعداد جدید چیز دیگری میگویند. نرخ موفقیت رفتاری عاملهای پیشرو در مهاجرت اپلیکیشنهای واقعی جاوا، کمتر از ۱۰ درصد است.
طبق تحلیل فنی منتشر شده در ۳۰ ژوئن ۲۰۲۶، محک جدیدی به نام ScarfBench (Self-Contained Application Refactoring Benchmark) افشا کرد که شکاف عمیقی میان «تولید کد» و «استقرار عملیاتی» وجود دارد. در واقع مدلها میتوانند کدهایی بنویسند که خطا ندهند (Compile شوند)، اما تضمین نمیکنند که برنامه پس از تغییر چارچوب (Framework)، واقعاً کار کند. این چالش با مسئلهی انحراف کدهای تولید شده توسط هوش مصنوعی از استانداردهای پروژهای همسو است که در آن کیفیت خروجی مدلها با نیازهای واقعی توسعه فاصله میگیرد.
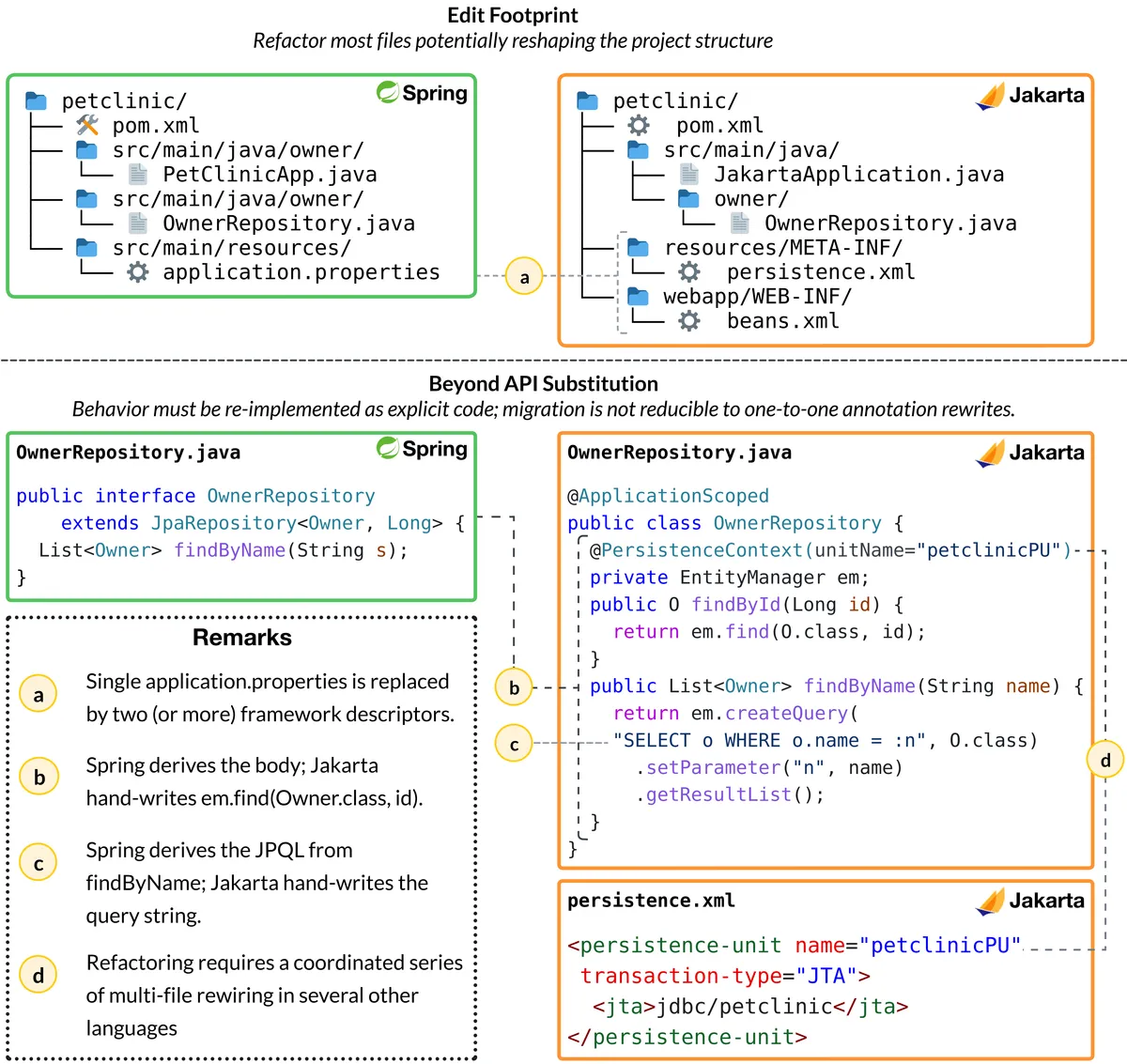
مدرنسازی نرمافزارهای سازمانی یکی از هزینهبرترین فعالیتهای مهندسی در سازمانهاست. هدف این تغییرات، افزایش آمادگی برای محیطهای ابری و بهبود بهرهوری توسعهدهندگان است. همانطور که در تحلیلهای قبلی ما دربارهی محدودیتهای استدلال در مدلهای زبانی اشاره کردیم، کدنویسی در محیطهای ایزوله با مدیریت یک سیستم پیچیده متفاوت است.
به گزارش IBM Research، توسعهدهندگان ScarfBench این ابزار را برای ارزیابی توانایی عامل (Agent) در مهاجرت میان سه اکوسیستم اصلی Spring، Jakarta EE و Quarkus طراحی کردند. برخلاف آزمونهای متنی که خروجی مدل را با یک متن مرجع مقایسه میکنند، ScarfBench مدل را مجبور میکند برنامه را بسازد، مستقر کند و از لایهی اعتبارسنجی رفتاری عبور دهد.
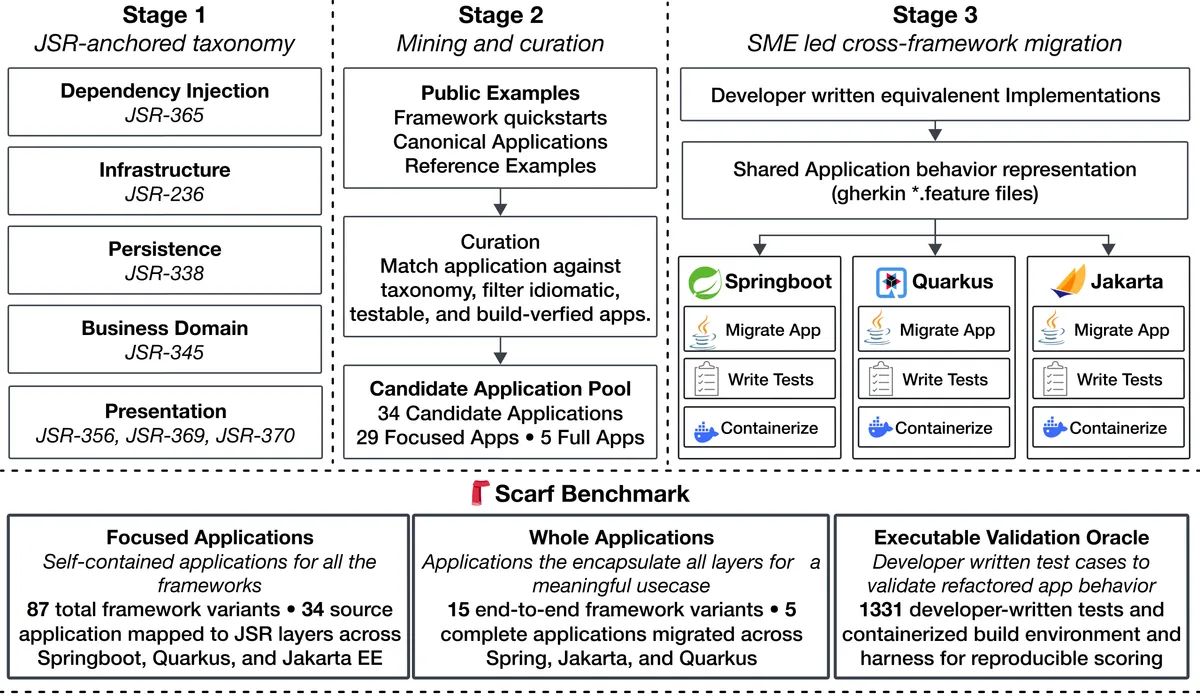
مشخصات فنی این محک عبارت است از:
- تعداد کل اپلیکیشنها: ۳۴ مورد
- پیادهسازیهای چارچوب: ۱۰۲ مورد
- مجموع وظایف مهاجرت: ۲۰۴ مورد
- تعداد خطوط کد: حدود ۱۵۱,۰۰۰ خط
- فایلهای منبع و تست: حدود ۲,۰۰۰ مورد
- تستهای تخصصی نوشته شده: ۱,۳۳۱ مورد
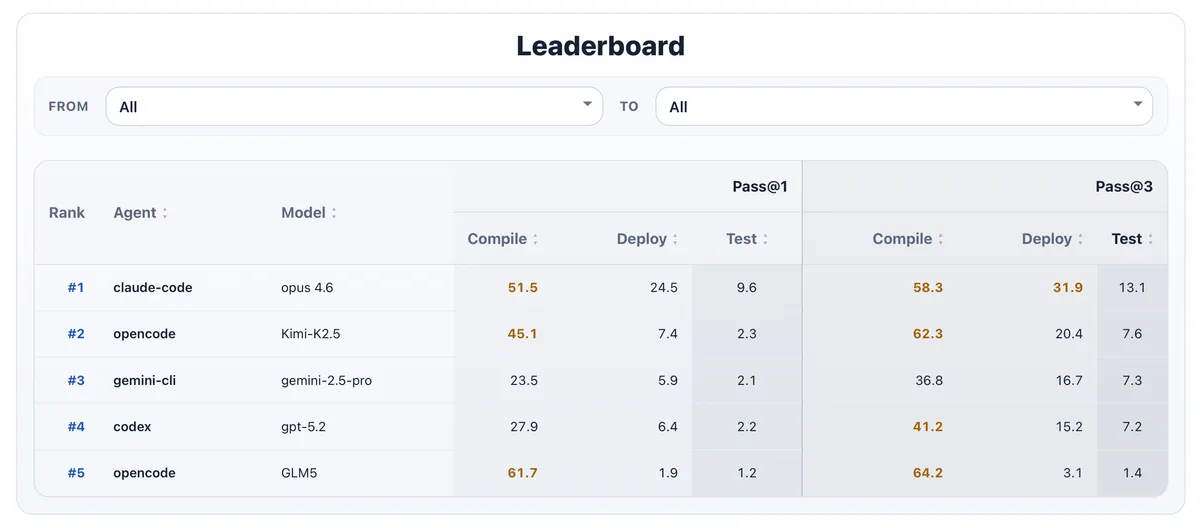
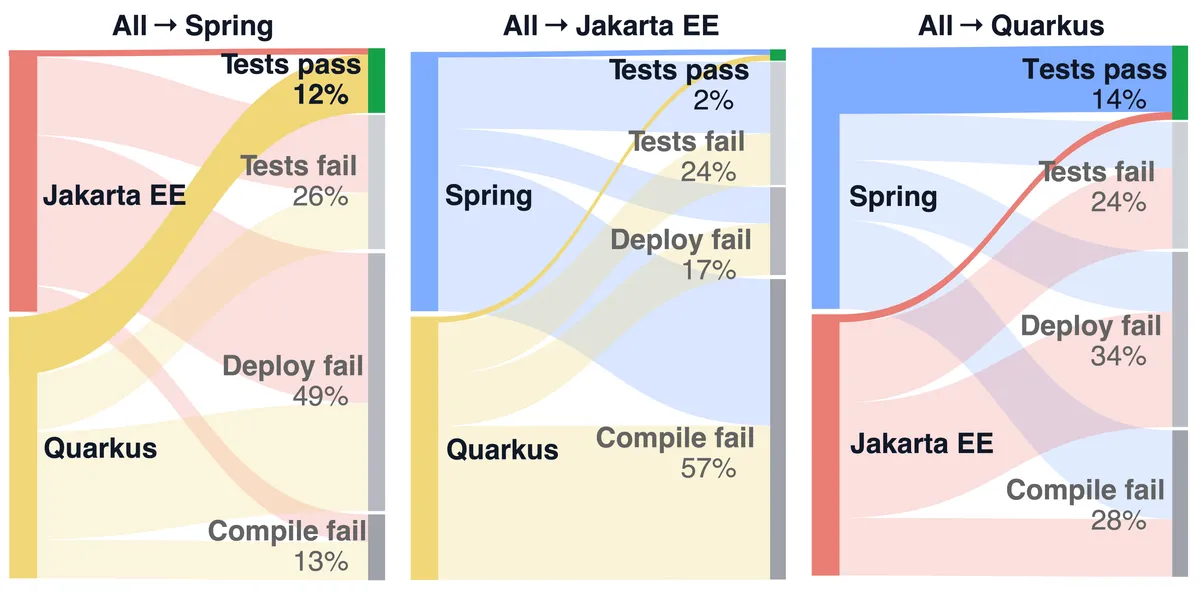
دادههای جدول ردهبندی نشاندهنده ریزش شدید کیفیت در مسیر «کامپایل $\rightarrow$ اجرا» است. موفقیت در مرحلهی Build رایجترین نتیجه است، اما موفقیت در استقرار (Deployment) بهمراتب کمتر و موفقیت رفتاری (Behavioral Success) نادرترین حالت است. این یعنی تکیه بر موفقیت در کامپایل، تخمینی بهشدت خوشبینانه و غلط از کیفیت مهاجرت است. همچنین، چارچوب Jakarta EE دشوارترین هدف برای عاملهای فعلی بود.
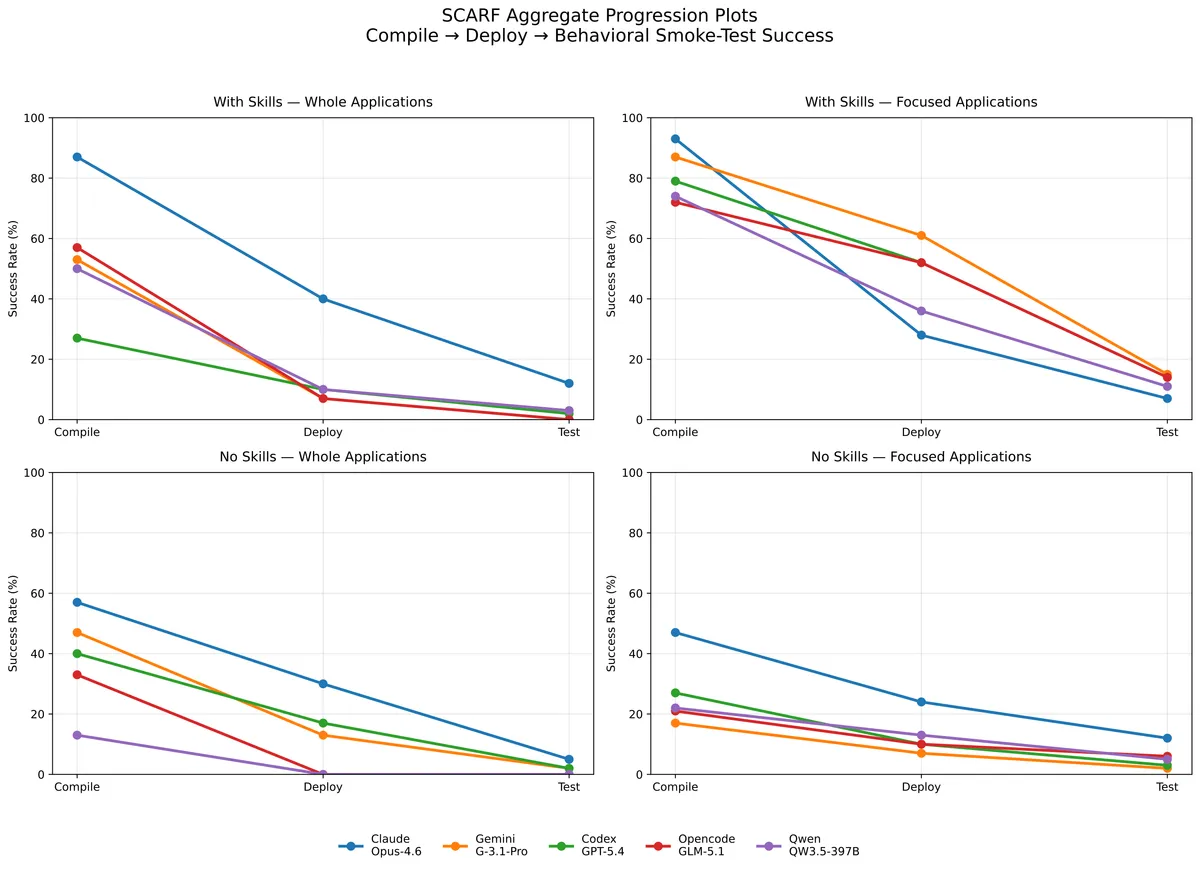
یکی از تکاندهندهترین یافتهها، «اعتمادبهنفس کاذب» مدلهاست. بر اساس مستندات تست مدل Claude Code، این عامل در ۲۹ مورد از ۳۰ اپلیکیشن گزارش داد که Build با موفقیت انجام شده است؛ اما در واقعیت تنها ۲۲ مورد موفق بودند. جالبتر آنکه تنها موردی که مدل آن را شکست اعلام کرد، در واقع بهدرستی Build شده بود. این یعنی خودارزیابی عاملها برای محیطهای عملیاتی کاملاً غیرقابل اعتماد است.
تحلیل گردش کار عاملها نشان میدهد مهاجرت، یک فرآیند خطی نیست، بلکه یک چرخه تکرارشونده برای حل وابستگیهاست. عاملها مدام بین لایههای زیر جابهجا میشدند:
- انتقالات اصلی: پیکربندی $\leftrightarrow$ وب و سرویس $\leftrightarrow$ پایگاهداده.
- توزیع تلاش: لایههای پیکربندی (Configuration) بیشترین نیاز به بازبینی را داشتند.
- لایههای مرکزی: بیشترین بازدیدها مربوط به بخشهای پیکربندی، وب، دیتابیس و سرویس بود.
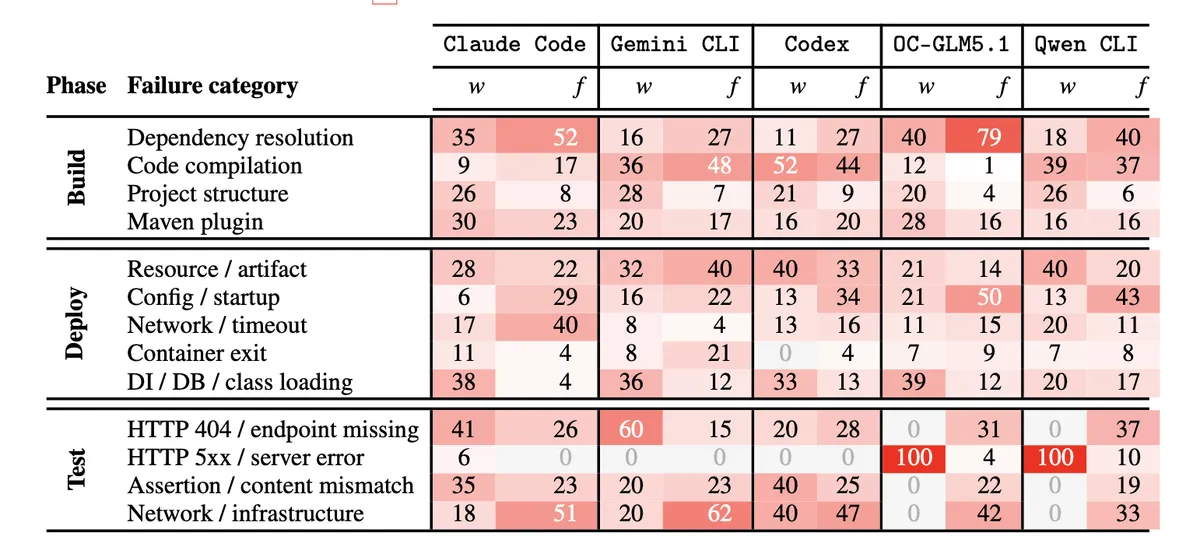
علاوه بر کد، اصطکاکهای محیطیe مانع اصلی هستند. بسیاری از شکستها ناشی از خطای کد نبودند، بلکه مشکلاتی نظیر ناسازگاری حافظه موقت (Cache) در Docker، مشکلات اتصال پورتها و ابزارهای Maven باعث توقف فرآیند میشدند. این دشواریها یادآور چالشهای استقرار اپلیکیشنهای AI در پلتفرمهای ابری است که نشان میدهد تعامل کد با زیرساخت، نقطه ضعف مشترک بسیاری از ابزارهای اتوماسیون است. برای جامعه فنی، این یعنی تمرکز باید از «مدلهای زبانی بهتر» به «استدلال معماری بهتر» تغییر کند. چالش اصلی، ترجمه کد جاوا نیست، بلکه مدیریت شبکهی وابستگیها در کل استک سازمانی است.
گام بعدی شما
- اگر از عاملهای کدنویسی برای بازنویسی سیستمها استفاده میکنید، هرگز به گزارش «موفقیت» مدل اعتماد نکنید و خط لولهی اعتبارسنجی مستقل بسازید.
- مجموعهدادههای ScarfBench را در Hugging Face بررسی کنید تا نقاط ضعف مدل خود را شناسایی کنید.
- تمرکز خود را بر ابزارهای تحلیل ایستا (Static Analysis) برای بررسی وابستگیها پیش از سپردن کار به AI بگذارید.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو