
اگر در حال ساخت یک پایگاه دانش برای عاملهای هوش مصنوعی هستید، میدانید که با افزایش حجم دادهها، سرعت پاسخگویی مدل به طرز عجیبی افت میکند. شما باید بدانید که این «افت خاموش»، دقیقاً همان جایی است که بسیاری از پروژههای اتوماسیون در مقیاس واقعی شکست میخورند.
بهروزرسانی نسخهی ۰.۴.۰ Synthadoc این مشکل را حل کرده است. بر اساس مستندات این نسخه، تأخیر جستوجو در ویکیهای ۱۰ هزار صفحهای از ۱۹۱ میلیثانیه به ۲۴ میلیثانیه رسید. این یعنی سرعت پاسخگویی تقریباً ۸ برابر شده است.
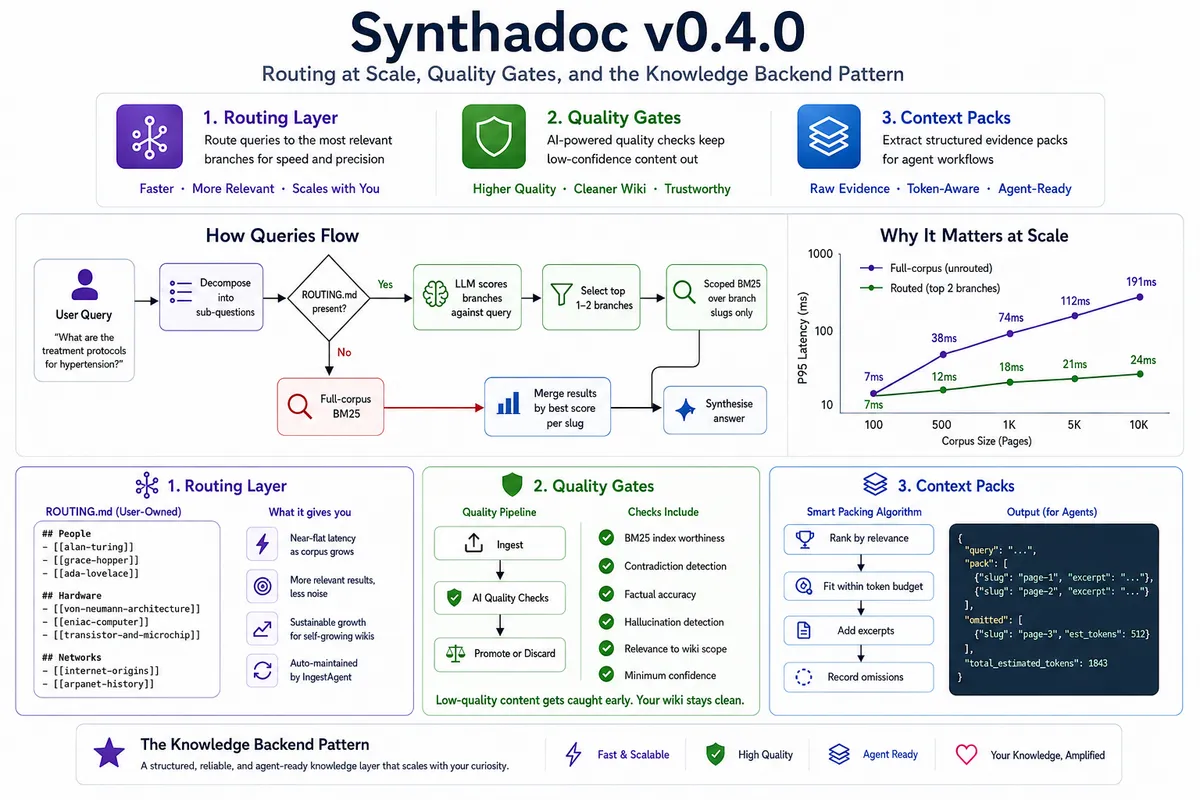
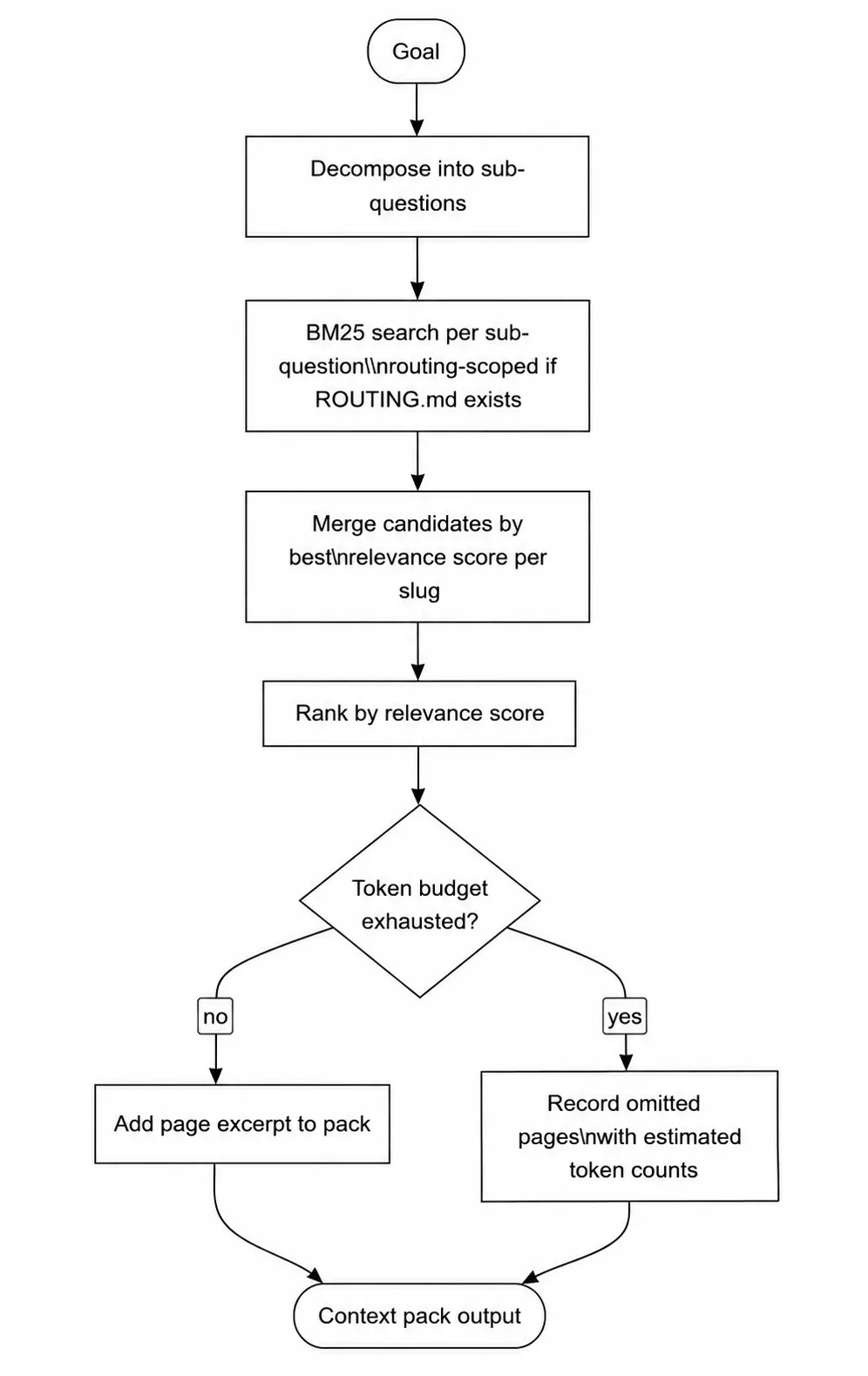
بیشتر ویکیهایی که به صورت خودکار رشد میکنند، در نهایت به دیواری میرسند که در آن سرعت جستوجو پایین میآید و نویز افزایش مییابد. طبق گزارش dev.to در ۱۱ مه ۲۰۲۶، دلیل این اتفاق این است که جستوجوی استاندارد BM25 تمام صفحات را بدون توجه به مربوط بودن اسکن میکند. این موضوع باعث میشود استنتاج (Inference) — که شبیه خودِ آشپزی است نه دورهی آموزش آشپز — در هر مرحله از پرسوجوی یک عامل (Agent) هزینهبر و کند شود.
همانطور که در تحلیلهای قبلی ما دربارهی بهینهسازی حافظه مدلها اشاره کردیم، جداسازی دادههای حیاتی از نویز، کلید افزایش دقت است. این رویکرد به تلاشهای گستردهتر برای ساختارهای دادهای دقیق شباهت دارد؛ مشابه پروژهی ATLAS شرکت متا که در آن صوریسازی دادههای ریاضی برای رسیدن به دقت حداکثری در مدلهای استدلالی دنبال شده است. Synthadoc برای حل این چالش، سه مکانیسم جدید معرفی کرده است:
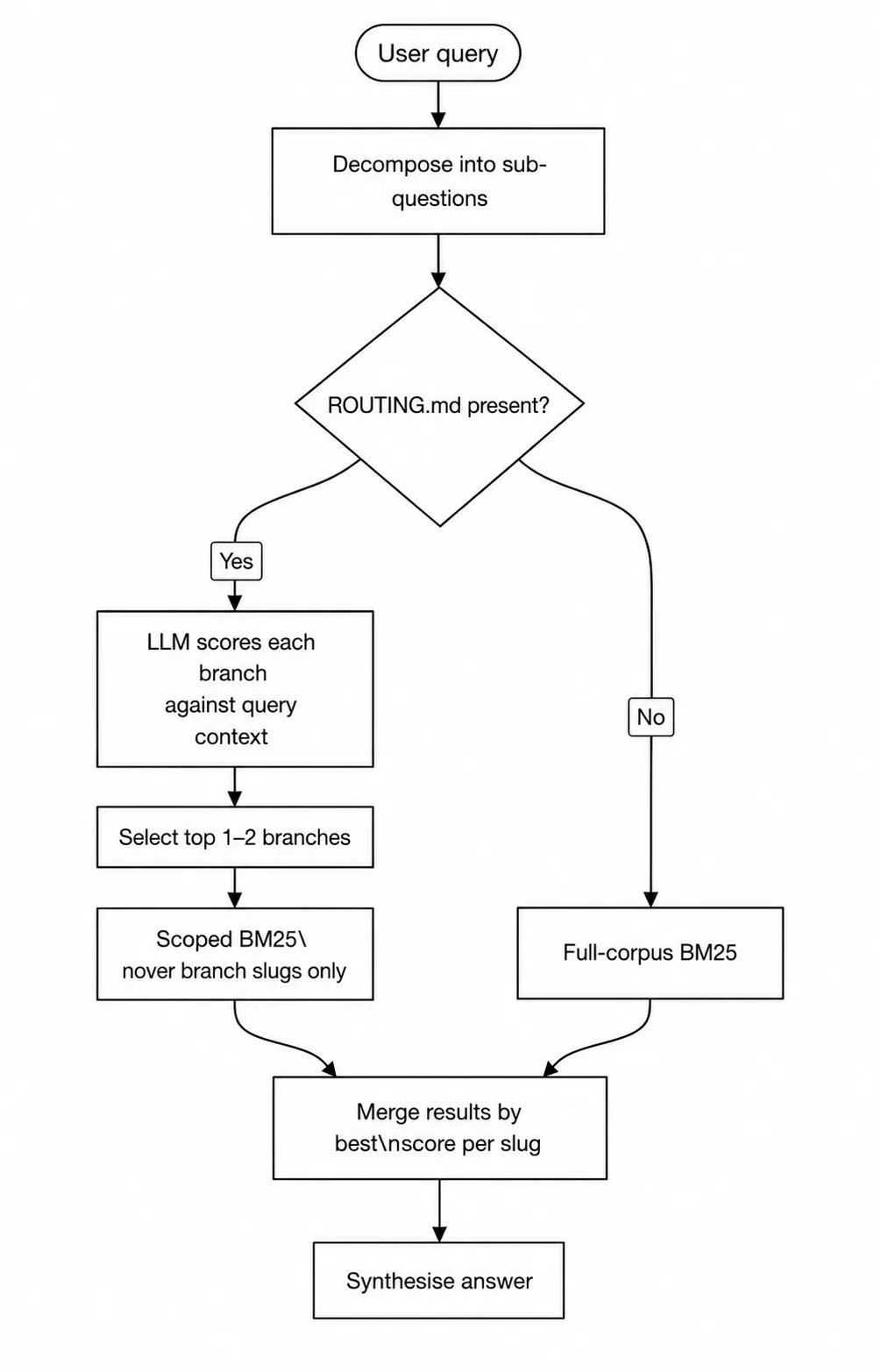
- لایهی مسیریابی (Routing Layer): استفاده از فایل
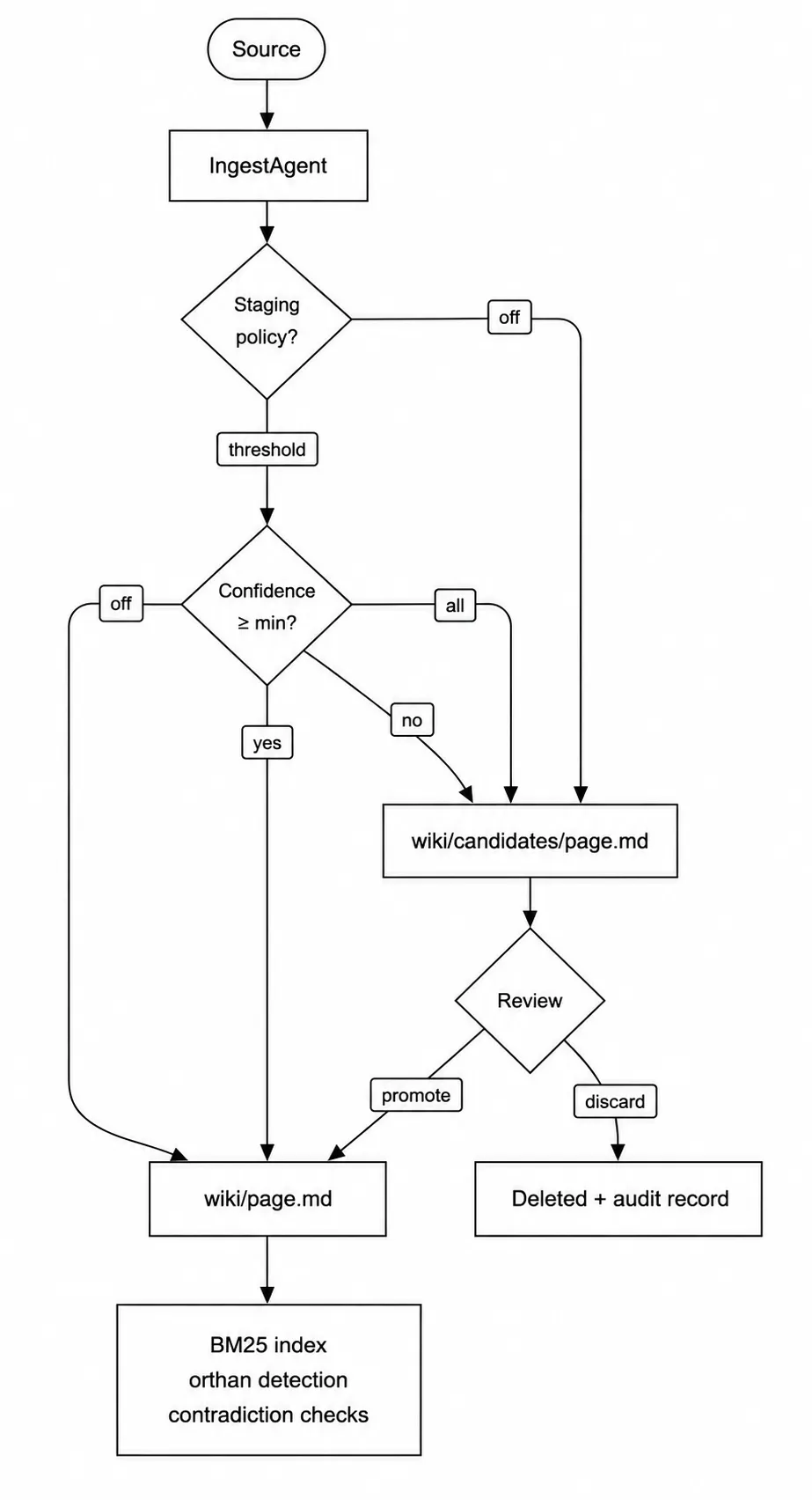
ROUTING.mdبرای محدود کردن جستوجو به شاخههای خاص. این کار باعث میشود سرعت جستوجو با رشد حجم دادهها، تقریباً ثابت بماند. - مرحلهبندی کاندیدها (Candidates Staging): صفحات جدیدی که سطح اطمینان پایینی دارند، ابتدا در یک ناحیه انتظار قرار میگیرند تا توسط انسان بررسی و تایید شوند.
- بستههای متنی (Context Packs): استخراج قطعات دقیق و رتبهبندی شده با کنترل سختگیرانه روی تعداد توکن (Token) — که شبیه برشهای کوچک یک کیک برای مصرف راحتتر مدل است.
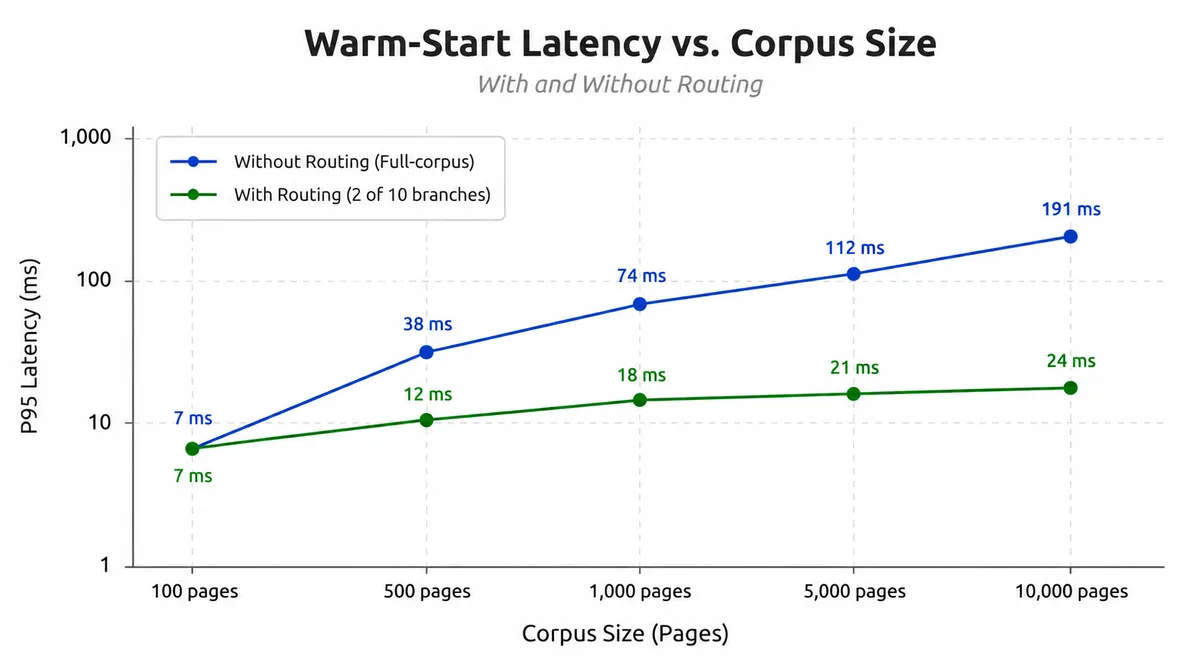
این سیستم همچنین قابلیت «تشخیص نام مستعار» را در متادیتای YAML اضافه کرده است. این یعنی عبارات کوتاه داخلی شما به نامهای استاندارد ویکی تبدیل میشوند. برای توسعهدهندگانی که از تولید بازیابیافزا (RAG) — شبیه دانشآموزی که قبل از جواب دادن، اول کتاب درسی را باز میکند — استفاده میکنند، رسیدن به تأخیر ۲۴ میلیثانیهای یک نقطه عطف در بهرهوری است.
این تغییر، الگوی «پشتبانه دانش» را تثبیت میکند. حالا Synthadoc مدیریت «چه چیزی» (جمعآوری و بازیابی) را بر عهده دارد و مدل زبانی بزرگ (LLM) — مثل کتابخانهداری که میلیاردها صفحه را خوانده و حالا با همان لحن جواب میدهد — مدیریت «چگونه» (استدلال) را بر عهده میگیرد.
گام بعدی شما
- کد این پروژه را از گیتهاب کلون کنید تا دموی مبتنی بر Gemini Flash 2.0 را تست کنید.
- چرخه تشخیص تناقضات (Contradiction Detection) را در دادههای خود بررسی نمایید.
- لایهی مسیریابی را برای کاهش هزینهی توکنها در خط لوله خود پیاده کنید.
اما تأثیر این سرعت بر هزینههای توکن در مقیاس صنعتی حتی شگفتانگیزتر است — به تحلیل ما دربارهی مدلهای زبانی کوچک (SLM) مراجعه کنید.



گفتگو