اگر امروز برای استقرار مدلهای زبانی هزینه میکنید، باید بدانید که لایه سرویسدهی اکنون میتواند هوشمندتر از خودِ مدل باشد. طبق گزارشی که در ۲۹ ژوئن ۲۰۲۶ توسط vllm.ai منتشر شد، vLLM Semantic Router میتواند با استقرار تیمی منضبط از ریز-عاملها پشت یک هویت مدل واحد، عملکرد مدلهای پیشرو (Frontier Models) را به چالش بکشد. این تغییر به طور موثری لایه هوش را از وزنهای مدل به زیرساخت سرویسدهی منتقل میکند.
برای سالها، توسعهدهندگان با API مدلها مانند یک لوله غیرفعال برخورد میکردند؛ شما یک پرامپت را به یک مدل خاص میفرستادید و یک پاسخ دریافت میکردید. اگر رفتار پیچیدهای میخواستید، مجبور بودید در منطق برنامه خود یک گراف عامل (Agent Graph) سفارشی بسازید که اغلب باعث افزایش تأخیر و شکنندگی سیستم میشد.
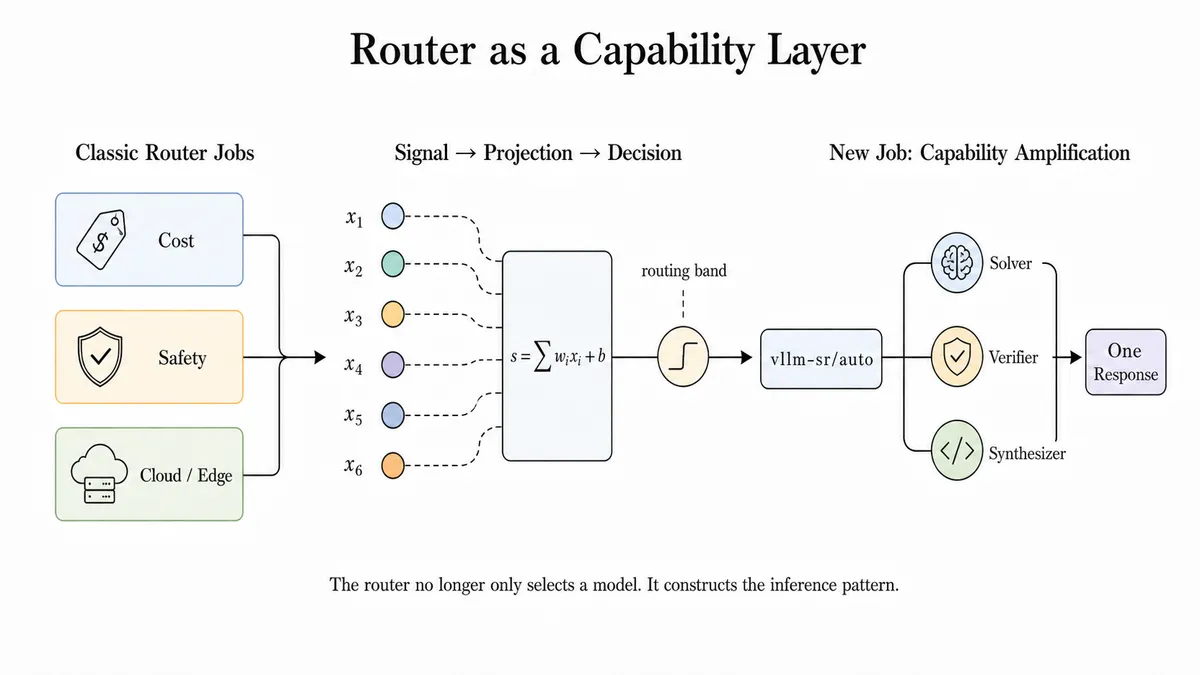
تصور کنید API شما بهجای انتخاب یک مدل، مانند یک مدیر عمل کند. این مدیر درخواست شما را تحلیل میکند، تصمیم میگیرد که آیا این یک سؤال ساده است یا یک تکلیف استدلالی پیچیده، و سپس تیمی از مدلهای مناسب را برای حل آن جمع میکند — تمام اینها پیش از بازگرداندن یک پاسخ واحد و تمیز به کاربر. این یعنی تغییر رویکرد از «انتخاب مدل» به «ساخت قابلیت».
زمینه و ضرورت مسیریابی در هوش مصنوعی
مسیریابها اکنون به صفحه کنترل استنتاج (Inference) — لحظهای که مدل واقعاً جواب تولید میکند، شبیه خودِ آشپزی و نه دورهی آموزش آشپز — تبدیل شدهاند. در ابتدا، نقش آنها کاربردی بود: هدایت درخواست درست به مدل درست. این موضوع حیاتی است زیرا هوش مصنوعی در محیط عملیاتی دیگر دنیای تکمدلی نیست.
مسیریابهای مدرن چندین وظیفه ضروری را ارائه میدهند:
- کاهش هزینه: تصمیمگیری درباره اینکه چه زمانی یک درخواست شایسته مدل پیشرو است و چه زمانی یک مدل بازمتن یا محلی کفایت میکند.
- اجرای ایمنی: ارسال حوزههای حساس به مدلهایی با فیلترهای سختگیرانهتر، مدلهای ایمنتر یا مسیرهای بررسی دقیقتر.
- هماهنگی ابر و لبه: نگه داشتن قصدهای خصوصی یا کمتأخیر در لبه (Edge) و ارجاع کارهای دشوارتر به ابر.
با این حال، تکامل بعدی، بهبود مدل بدون تغییر در وزنهاست. این فلسفه در پروژههایی مثل Sakana Fugu دیده میشود که با یک «مدل» به عنوان سطحی برخورد میکند که تیمی در پشت آن قرار دارد. در حالی که تحقیقاتی مانند گزارش فنی Fugu و مقالات هماهنگی مانند Conductor و Trinity زبان لازم برای ارکستراسیون را فراهم کردند، vLLM Semantic Router این انتزاع را به لایه باز سرویسدهی آورد.
محیط اجرای لوپر (Looper Runtime)
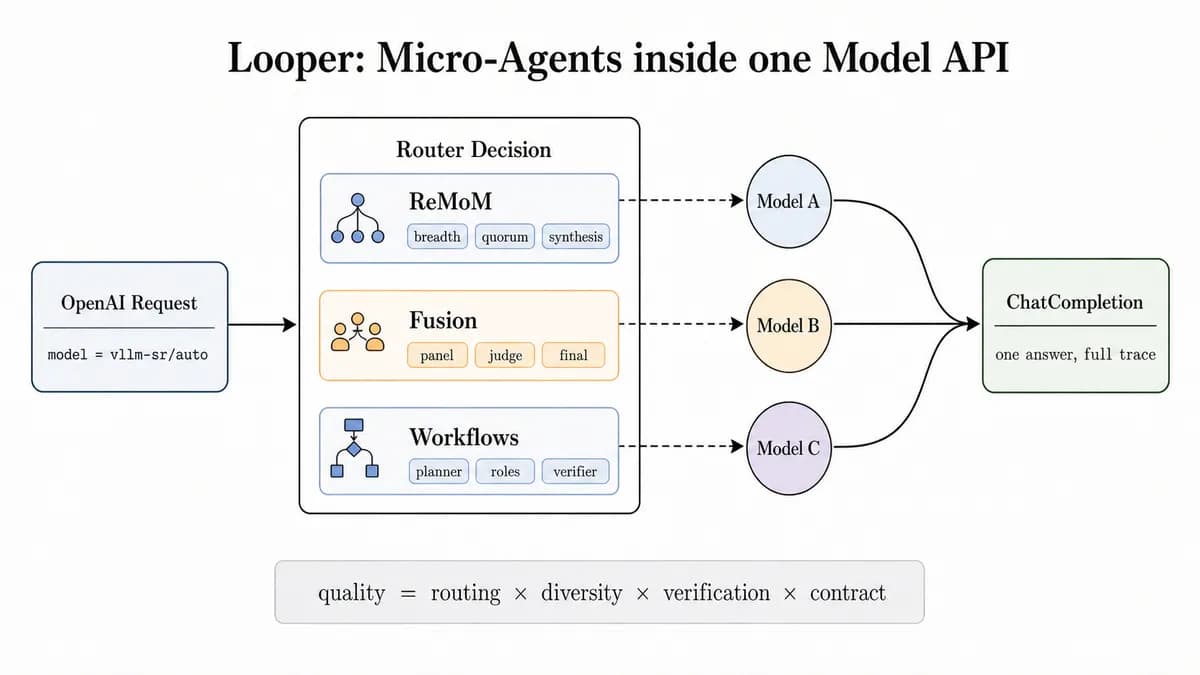
قلب این سیستم «لوپر» است؛ یک محیط اجرا برای ریز-عاملهای محدود. وقتی درخواستی به نقطه اتصال vllm-sr/auto میرسد، مسیریاب آن را به شکلهای تکلیفی (Task-shapes) یا باندهای ریسک تبدیل میکند تا الگوریتم مناسب را انتخاب کند.
پشت این هویت مدل واحد، مسیریاب میتواند یک «دستور پخت» (Recipe) را انتخاب کند، کار را بین چندین کارگر پخش کند، یک حد نصاب (Quorum) جمعآوری کند، اختلافات را تأیید کند، یک پاسخ نهایی را سنتز کند و قرارداد خروجی را اصلاح نماید. هدف این است که همکاری تیمی، برای کاربر شبیه به خروجی یک مدل واحد به نظر برسد و پیچیدگیها به کاربر نمایش داده نشود.
برخلاف عاملهای خودمختار نامحدود، لوپر تحت کنترلهای سختگیرانه زیرساختی عمل میکند. این یک محیط اجرای کوچک با بودجه، توپولوژی، ردپا (Trace) و سیاست شکست تعریفشده است. این امر تضمین میکند که سیستم آماده تولید باشد و توسط زیرساخت مدیریت شود، نه توسط چسبهای برنامهنویسی در لایه اپلیکیشن.
پنج الگوی همکاری اصلی
vLLM پنج الگوی متمایز لوپر را برای مدیریت انواع مختلف بار شناختی پیاده کرده است:
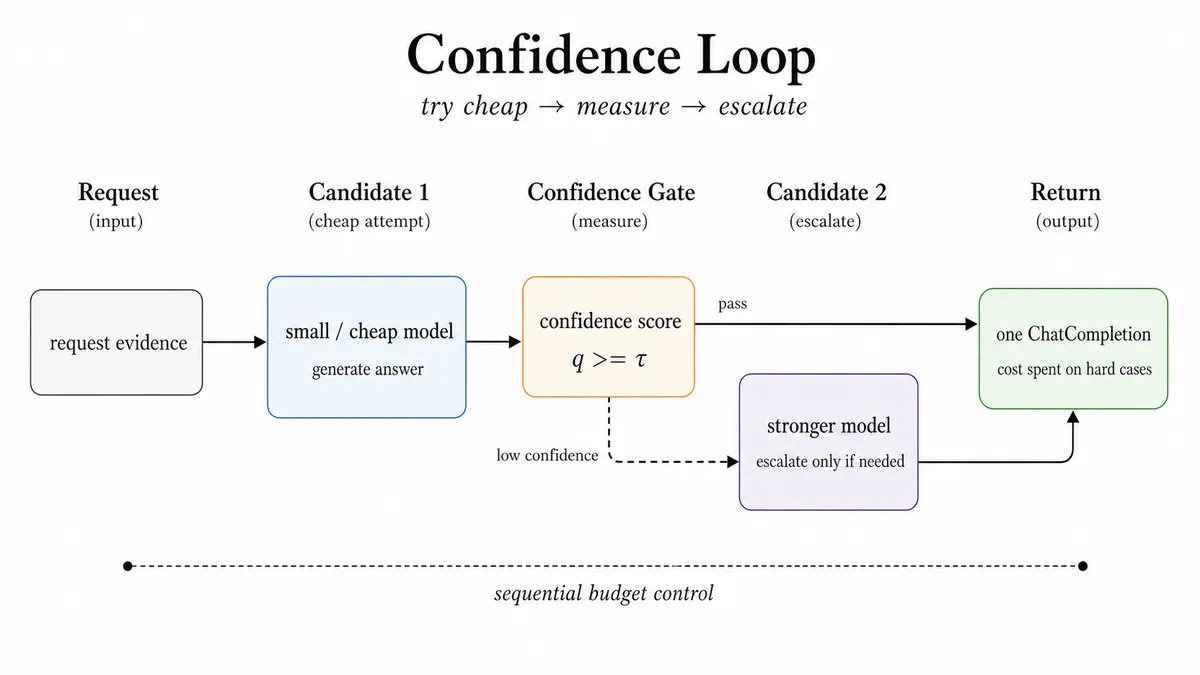
- اعتماد (Confidence): یک حلقه ارتقای متوالی و حساس به هزینه. این حلقه با یک کاندیدای کوچکتر یا ارزانتر شروع میکند و ارزیابی میکند که آیا پاسخ به اندازه کافی مطمئن است تا متوقف شود یا خیر. سیگنالهای اعتماد میتوانند از موارد زیر باشند:
- احتمال لگاریتمی در سطح توکن (Token-level log probability)
- حاشیه Logprob
- امتیازهای ترکیبی (Hybrid scores)
- خود-تأییدسازی (Self-verification)
- تأییدکنندههای استلزامی به سبک AutoMix
اگر امتیاز خیلی پایین باشد، مسیر به کاندیدای بعدی ارتقا مییابد. این کار ارتقا را به یک سیاست توقف اندازهگیری شده با آستانههای قابل تنظیم تبدیل میکند.
- رتبهبندی (Ratings): یک حلقه مجموعهای کنترلشده. این الگو چندین کاندیدا را بهطور موازی اجرا میکند، اما فقط تا یک سقف پیکربندی شده به نام
max_concurrent. این کار از پخش نامحدود جلوگیری میکند در حالی که از دیدگاههای چندین مدل بهره میبرد. مسیریاب از تجمیع آگاه از رتبه استفاده میکند و بهویژه برای ارزیابیهای سبک A/B و استراتژیهای مجموعهای مفید است.
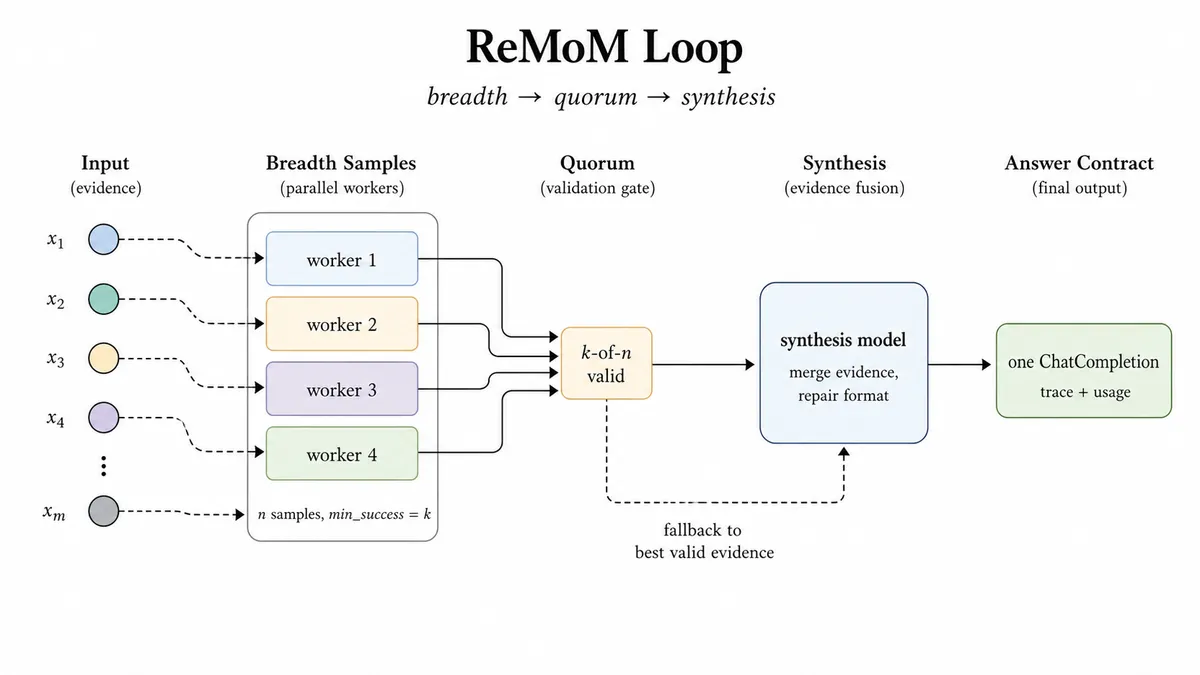
- ReMoM (ترکیب تکرارپذیر مدلها): برای تکالیفی با واریانس استدلالی بالا طراحی شده است که در آن فرمت پاسخ باید در طول همکاری حفظ شود. این الگو چندین تلاش استدلالی را پخش میکند و منتظر رسیدن به یک حد نصاب موفقیت حداقلی میماند. سپس یک مدل سنتز، شواهد را در قرارداد خروجی مورد نیاز ادغام میکند. اگر سنتز شکست بخورد، سیستم بهجای بازگرداندن خطای API، میتواند به بهترین شواهد معتبر بازگردد.
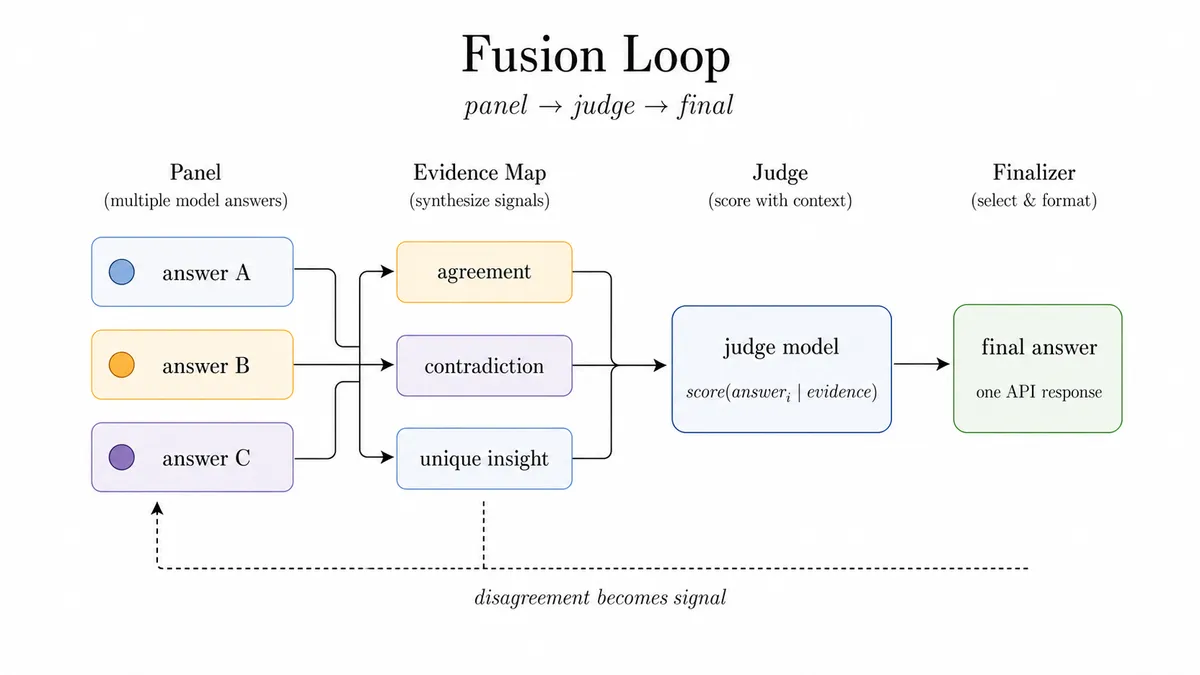
- تلفیق (Fusion): الگویی که با اختلافنظر به عنوان یک سیگنال برخورد میکند. بهجای جستوجوی یک پاسخ میانگین، از پاسخهای مستقل پانل به عنوان شواهد استفاده میکند. یک داور، توافق، تضاد و بینشهای منحصربهفرد را تحلیل میکند و یک نهاییکننده، یک پاسخ را با ردپای متراکم بازمیگرداند. این برای استدلالهای سخت چندگزینهای یا قضاوتهای تخصصی طولانی که پاسخهای تکمدلی در آنها شکننده هستند، ایدهآل است.
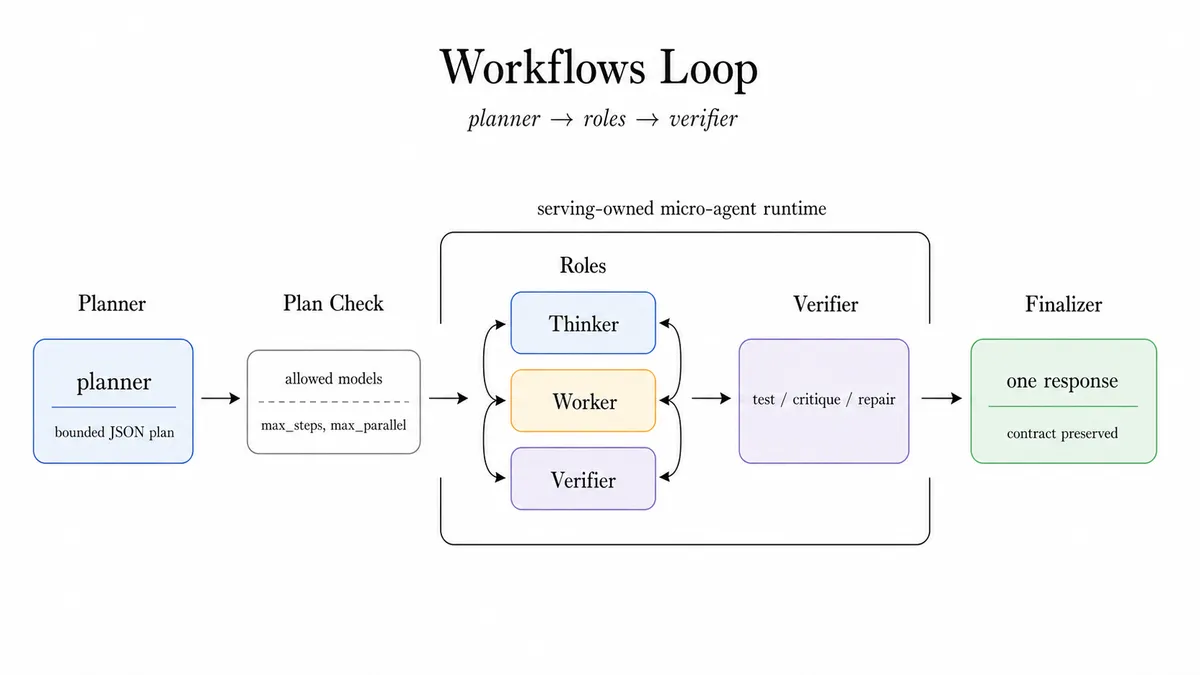
- گردشهای کاری (Workflows): عاملمحورترین الگو است که سختگیرانهترین مرزها را میطلبد. این الگو از یک محیط اجرای گردش کار ریز-عامل با نقشهای استاتیک یا یک برنامهریز پویا پشتیبانی میکند. برای تکالیف سبک SWE (مهندسی نرمافزار)، مسیریاب میتواند یک برنامهریز، اصلاحکننده، تأییدکننده و نهاییکننده را تعریف کند. برای حفظ ایمنی، برنامهریز فقط میتواند مدلهای کارگر مجاز را انتخاب کند و گامها توسط حداکثر تعداد گام، حداکثر موازیسازی، تایم-اوتها و سیاستهای خطا محدود میشوند.
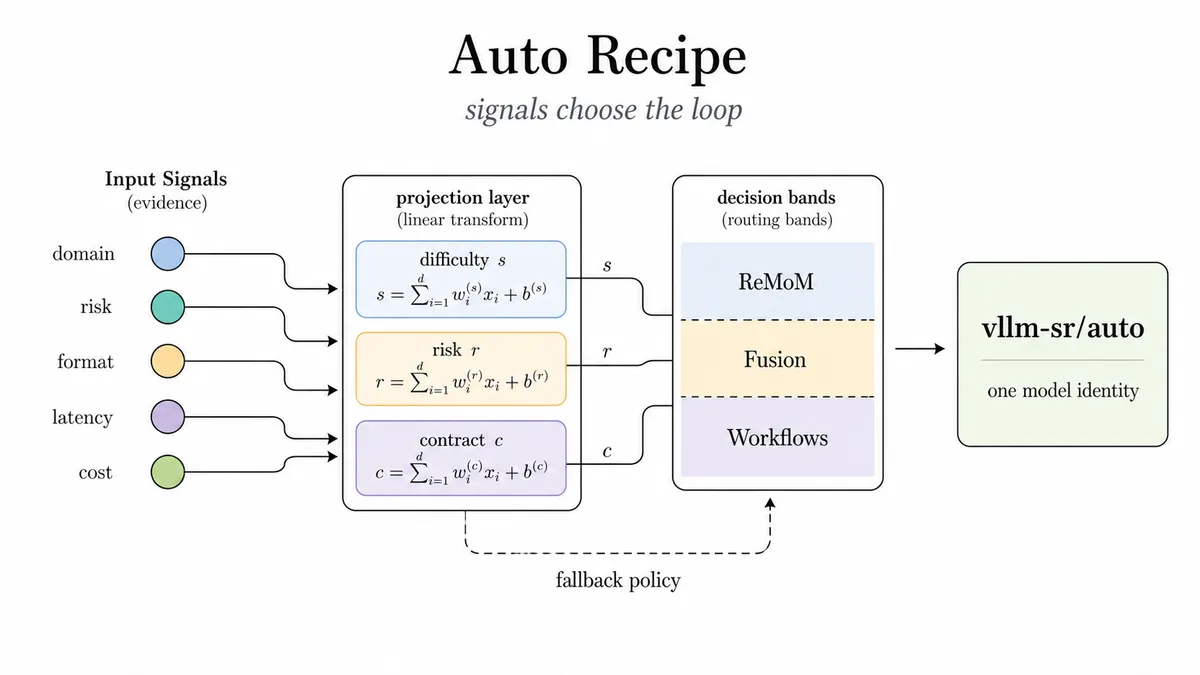
دستورهای پخت متناسب با تکلیف
قدرت سیستم از «دستورهای پخت» (Recipes) میآید؛ پیکربندیهایی که برای بنچمارکهای خاص بهینه شدهاند. مسیریاب فقط بزرگترین حلقه را اجرا نمیکند، بلکه بر اساس واقعیتهای مسیریابی مانند سختی، ریسک، فشار قرارداد، تأخیر و هزینه، دستور پختی را انتخاب میکند که با شکل تکلیف سازگار باشد.
مثالهای خاص از دستورهای پخت عبارتند از:
- GPQA-Diamond: پرامپتهای سخت چندگزینهای علوم را به یک دستور پخت ReMoM با حفظ سختگیرانه فرمت
ANSWER: Xهدایت میکند. - LiveCodeBench: پیش از انتخاب یک حلقه کد-محور، محدودیتها، کد اولیه، ورودی استاندارد، تلورانس اعشاری، ریسک تایم-اوت و ریسک تستهای پنهان را تحلیل میکند.
- Humanity's Last Exam (HLE): استدلالهای صوری، ریسک اختلافنظر، کانتکست طولانی و فشار برای پاسخ دقیق را شناسایی میکند تا بین ReMoM عمیق، Fusion کوچکتر یا یک مسیر جایگزین (Fallback) تصمیم بگیرد.
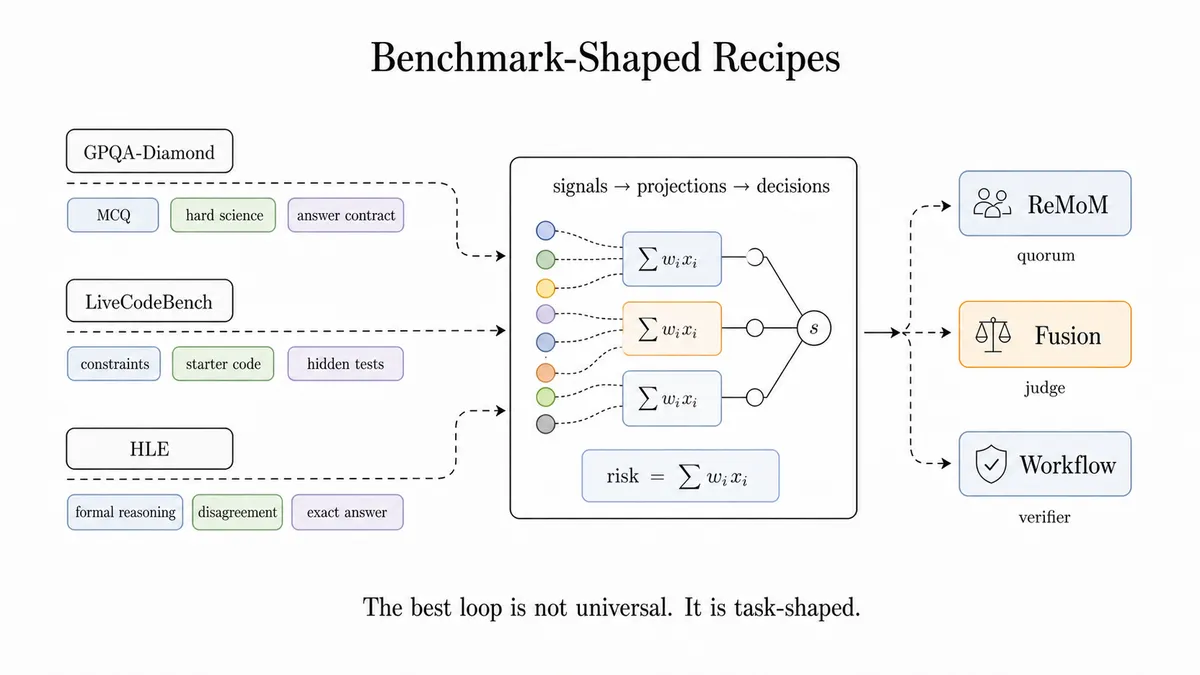
این رویکرد ثابت میکند که بهترین حلقه، حلقهای است که متناسب با شکل تکلیف باشد. دستور پخت، استخر مدلها، نقشها، تلاش استدلالی، همزمانی، حد نصاب، تایم-اوت، مدل سنتز، سیاست جایگزین، قرارداد خروجی و برچسبهای مشاهدهپذیری را تعریف میکند.
تحلیل عملکرد و بنچمارکها
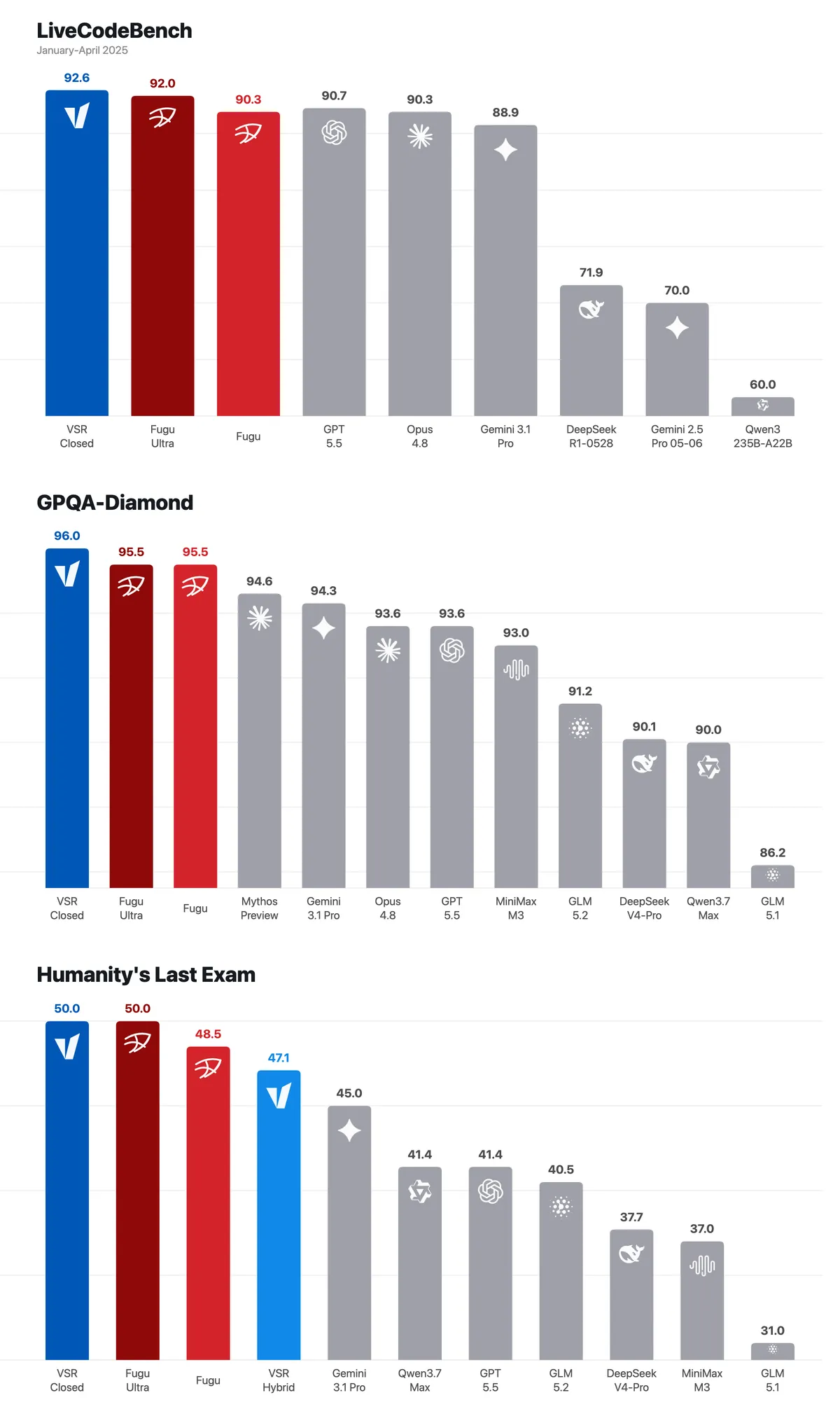
دادههای ارزیابی نشان میدهد که همکاری تحت مالکیت مسیریاب، هویتی قویتر از هر مدل واحدی میسازد. در آزمونهای سه بنچمارک سخت، دستور پخت «VSR Closed» (که فقط از بکاندهای مدلهای بسته استفاده میکند) نتایج قابل توجهی به دست آورد:
- LiveCodeBench (ژانویه-آپریل ۲۰۲۵): امتیاز ۹۲.۶ را کسب کرد و از GPT-5.5 (۹۰.۷)، Fugu Ultra (۹۲.۰)، Fugu (۹۰.۳) و Opus 4.8 (۹۰.۳) پیشی گرفت.
- GPQA-Diamond: امتیاز ۹۶.۰ را به دست آورد و از Fugu Ultra (۹۵.۵)، Fugu (۹۵.۵)، Gemini 3.1 Pro (۹۴.۳) و GPT-5.5 (۹۳.۶) پیشی گرفت.
- Humanity's Last Exam: امتیاز ۵۰.۰ را کسب کرد که با Fugu Ultra (۵۰.۰) برابر بود و از Fugu (۴۸.۵) و Gemini 3.1 Pro (۴۵.۰) بهتر عمل کرد.
مزیت رویکرد ترکیبی (Hybrid)
vLLM همچنین رویکرد «VSR Hybrid» را آزمایش کرد که مدلهای وزنهای باز (Open Weights) را با مدلهای بسته ترکیب میکند. در این ساختار، مدلهای بسته قویتر برای داوریهای پرریسک، اصلاح یا سنتز رزرو میشوند، در حالی که مدلهای باز حجم اصلی کارهای کارگری را انجام میدهند.
در آزمون Humanity's Last Exam، دستور پخت ترکیبی امتیاز ۴۷.۱ را کسب کرد و از GLM-5.2 (۴۰.۵)، Qwen3.7 Max (۴۱.۴) و GPT-5.5 (۴۱.۴) بهتر عمل کرد.
این ثابت میکند که لایه سرویسدهی میتواند ترکیبی از ارائهدهندگان را سازماندهی کند تا با خطوط پایه مدلهای پیشرو برابری کند یا از آنها پیشی بگیرد، در حالی که یک سطح API سازگار با OpenAI را حفظ میکند. سیستم میتواند بدون تغییر در یکپارچگی کلاینت، بهبود یابد.
تغییر پارادایم سرویسدهی
این معماری، پشته سرویسدهی را از حالت غیرفعال به فعال تبدیل میکند. بهجای صرفاً مسیریابی، زیرساخت اکنون میپرسد:
- چه شواهدی درباره این درخواست داریم؟
- این درخواست در کدام باند کیفیت، هزینه، تأخیر و ایمنی قرار میگیرد؟
- آیا یک مدل کافی است یا کدام الگوی همکاری باید اجرا شود؟
- کدام قرارداد پاسخ باید حفظ شود؟
- اگر یک ارائهدهنده کند یا اشتباه بود چه اتفاقی باید بیفتد؟
- چگونه یک پاسخ تمیز ارائه دهیم در حالی که ردپای کامل را حفظ کنیم؟
با انتقال ریز-عاملها به داخل مسیریاب، vLLM از مالکیت فعلی مسیریاب بر نامهای مستعار مدل، سیاست ارائهدهنده، اعتبارنامهها، متادیتای هزینه، سیگنالها، تصمیمات، تلاشهای مجدد، تایم-اوتها، ردپاها و معناشناسی پاسخهای سازگار با OpenAI بهره میبرد. این کار «چسبهای برنامهنویسی» (Application Glue) را که معمولاً برای ساخت سیستمهای عاملمحور لازم است، حذف میکند.
برای توسعهدهنده، این بدان معناست که سیستم میتواند — با بهروزرسانی یک دستور پخت یا افزودن یک مدل جدید به استخر — بدون تغییر حتی یک خط کد یکپارچهسازی در سمت کلاینت، ارتقا یابد.
این تحول نشان میدهد که «مدل پیشرو» بعدی، لزوماً یک چکپوینت بزرگتر از وزنها نیست، بلکه یک مرز سیستمی است. رقابت اکنون به سمت مسیریابهایی میرود که میتوانند یک درخواست واحد را به تیمی منضبط و مقرونبهصرفه تبدیل کنند. این وعده ریز-عاملها در داخل API مدل است.
گام بعدی شما
- اگر از vLLM برای استقرار مدلها استفاده میکنید، نقطه اتصال
vllm-sr/autoرا برای تست الگوهای همکاری فعال کنید. - برای کاهش هزینهها، الگوی Confidence را پیاده کنید تا درخواستهای ساده توسط مدلهای کوچکتر پاسخ داده شوند.
- دستورهای پخت (Recipes) اختصاصی برای دامین کاری خود تعریف کنید تا دقت استدلال را بدون تغییر مدل افزایش دهید.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو