تصور کنید یک تحلیلگر مالی است که برای تحلیل گزارشهای سالانه، هزاران صفحه PDF را به هوش مصنوعی میدهد، اما مدل بهطور مداوم اعداد اشتباهی را گزارش میکند. مشکل از هوش نیست؛ بلکه دادهها در مسیر تبدیل به Markdown بهطور نامحسوس فاسد شدهاند.
به نقل از تحلیل فنی منتشر شده در ۲۹ ژوئن ۲۰۲۶ توسط سازنده pdf2md.dev، این باور که تبدیل PDF به Markdown یک مسئلهی حلشده و ساده است، کاملاً غلط است. در واقع، اسنادی که بیشترین اهمیت را دارند — مانند مقالات پژوهشی، گزارشهای سالانه، صورتحسابها و قراردادهای اسکنشده — توسط تبدیلکنندههای ساده بهطور بنیادین تخریب میشوند.
یک فایل PDF برخلاف HTML یا DOCX، یک سند دیجیتال نیست، بلکه مجموعهای از دستورات ترسیمی است. PDF به نمایشگر میگوید چه نویسهای را در چه مختصاتی قرار دهد یا کجا خط بکشد. چشم انسان ساختار را بازسازی میکند — مثلاً میفهمد متن درشت و ضخیم احتمالاً یک تیتر است — اما یک تبدیلکننده باید این منطق را از روی هندسهی خام و نویسهخوانی نوری (OCR) بازسازی کند. اگر ابزاری فقط متن را استخراج کند، در تستهای ساده موفق میشود اما در مواجهه با گزارشهای حرفهای شکست میخورد.
همانطور که در تحلیلهای قبلی ما دربارهی امنیت و دقت مدلهای زبانی اشاره کردیم، کیفیت خروجی مدل مستقیماً به کیفیت دادههای ورودی وابسته است. در اینجا، مشکل اصلی «تلهی جداول» است. جداول ساده بهراحتی به فرمت Markdown تبدیل میشوند، اما ساختارهای پیچیده چنین شانسی ندارند:
- سلولهای ادغامشده: اینها با ساختار شبکهای استاندارد Markdown سازگار نیستند.
- تیترهای تودرتو: سلسلهمراتبی دارند که Markdown قادر به نمایش آن نیست.
- جداول چرخان: ترتیب خواندن در این جداول بههم میریزد و باید قبل از تشخیص سلولها اصلاح شود.
- جداول بدون خط: سختترین حالت هستند چون شبکه فقط بر اساس تراز بصری شکل گرفته است.
وقتی تبدیلکنندهها در اینجا شکست میخورند، جداولی تولید میکنند که «مرتب» به نظر میرسند اما ستونها جابهجا شده یا اعداد به برچسبهای غلط متصل شدهاند. این وضعیت خطرناکتر از یک خطای آشکار است، زیرا این دادههای فاسد مستقیماً وارد یک تولید بازیابیافزا (RAG) — شبیه دانشآموزی که قبل از جواب دادن، اول کتاب درسی را باز میکند و از آن نقل میآورد — میشوند و هیچ انسانی دوباره منبع را چک نمیکند. این چالشها دقیقاً همان نقاط ضعفی هستند که در بررسی ۱۵ گام حیاتی در پردازش داده برای جلوگیری از شکست سامانههای RAG به آنها پرداخته بودیم.
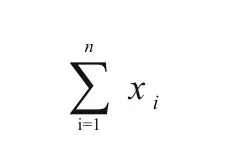
چالش دوم، چیدمان و ترتیب خواندن است. مقالات آکادمیک و دیتاشیتها اغلب از ستونهای دوگانه یا سه گانه استفاده میکنند. یک استخراجکننده ساده که بر اساس مختصات x/y میخواند، خط اول ستون اول را با خط اول ستون دوم ترکیب میکند و متنی بیمعنی میسازد. برای حل این مشکل، تحلیل عمیق چیدمان برای تشخیص مرز ستونها ضروری است. این شکست در موارد زیر نیز تکرار میشود:
- نوارهای کناری و کپشنها
- پاورقیها و شماره صفحات
- تیترهای تکرارشونده در بالای صفحات
در مورد فرمولهای ریاضی، ما با یک مسئلهی بصری روبروییم. فرمول در PDF مجموعهای از نویسههاست که با دقت روی صفحه قرار گرفتهاند (مثل نماد ∑ یا √). تبدیل اینها به متن کاربردی نیازمند بازسازی آنها به رشتههای شبیه LaTeX است. خط لولههایی که فقط از Regex استفاده میکنند، یک معادله پیچیده را به ردیفی از نمادهای شناور تبدیل میکنند و سند فنی را برای مدلهای زبانی بیفایده میسازند.
اسناد اسکنشده کل مسیر را تغییر میدهند چون لایه متنی ندارند و صرفاً تصویری از صفحات هستند. اینجا کیفیت نویسهخوانی نوری (OCR) — فرآیند تبدیل تصویر متن به متن دیجیتال — تعیینکننده است:
- اسکنهای باکیفیت: صفحات ۳۰۰ DPI با کنتراست بالا بهخوبی تبدیل میشوند.
- اسکنهای بیکیفیت: عکسهای کج با موبایل یا فکسهای کمرنگ، تشخیص را مختل میکنند.
- عناصر پیچیده: متون ریز، جداول متراکم و دستخطها بهطور قابلاعتمادی شناسایی نمیشوند.
OCR اغلب «اشتباهات باورپذیر» تولید میکند که شناساییشان سخت است. برای مقابله با این موضوع، pdf2md.dev از یک سیستم پردازش بودجهمحور استفاده میکند. اگر یک اسکن طولانی از حد حافظه یا زمان مجاز فراتر رود، سیستم نتیجهی تولیدشده تا آن لحظه را برمیگرداند و آن را بهعنوان «قطعشده» علامت میزند تا از گم شدن بیصدای دادهها جلوگیری شود.
در مورد تصاویر، یک دکمهی ساده برای «شامل کردن تصاویر» کافی نیست. تصاویر سه نوع کاربرد دارند:
- محتوای ضروری: نمودارها و مهرها که معنای سند را میسازند.
- نویز تزئینی: پسزمینههایی که باید نادیده گرفته شوند.
- تصاویر تمامصفحه: صفحاتی که کاربر بهجای رشتههای base64، متن استخراجشده از آنها را میخواهد.
از نظر عملیاتی، بسیاری از اسکریپتهای ساده در مواجهه با حجم کاری حرفهای شکست میخورند. مشکلاتی مثل توقف نامحدود تبدیل، اتمام حافظه در OCR سنگین یا بسته شدن تب توسط کاربر، نیاز به یک چرخه حیات کامل برای مدیریت شغلها (Job Lifecycle) دارد. این شامل ردیابی هر شغل، محدود کردن تلاشهای مجدد و حذف فوری فایلهای ورودی پس از پردازش برای حفظ حریم خصوصی است.
به دلیل اینکه هیچ موتور واحدی در تمام اسناد برنده نیست، pdf2md.dev از دو موتور مجزا استفاده میکند:
- MinerU: موتور پیشفرض که در فشار حافظه ایمنتر است و در اسناد متراکم، OCR سنگین و متون سیریلیک بهتر عمل میکند.
- Docling: موتوری سریعتر که در PDFهای متنی ساده و خوشساختار نتایج تمیزتری میدهد اما در OCRهای سنگین منعطف نیست.
برای ارزیابی ابزارهای تبدیل، از اسناد نمونهی تمیز استفاده نکنید. ابزار را با یک مجموعهی «بدترین حالت» آزمایش کنید: یک مقاله دو-ستونی با پاورقی، یک جدول پیچیده با تیترهای ادغامشده، یک صورتحساب اسکنشده و یک سند فنی حاوی فرمولهای ریاضی. بررسی کنید که آیا ترتیب خواندن با نسخه اصلی مطابقت دارد و آیا ابزار در مواجهه با دستخطهای ناخوانا، صادقانه اعلام شکست میکند یا کلمات جعلی میسازد.
در نهایت، حریم خصوصی در تبدیل PDF یک ویژگی محصول است، نه یک متن ریز در شرایط استفاده. مدل ایدهآل باید بدون نیاز به حساب کاربری باشد، فایلها را بلافاصله پس از پردازش حذف کند و هرگز از اسناد برای آموزش مدلهای AI استفاده نکند.
گام بعدی شما
- اگر از RAG استفاده میکنید، نمونهای از دادههای تبدیلشده را با نسخه PDF اصلی مقایسه کنید تا نرخ «فساد خاموش» را بسنجید.
- برای اسناد پیچیده، بهجای استخراج متن ساده، از ابزارهایی استفاده کنید که تحلیل چیدمان (Layout Analysis) را پشتیبانی میکنند.
- در خط لوله دادههای خود، مکانیزم «علامتگذاری قطعشدگی» (Truncation Marker) را برای فایلهای حجیم پیادهسازی کنید.
اما تأثیر این فساد دادهها بر توهم مدلها حتی عمیقتر است — به تحلیل ما دربارهی استراتژیهای کاهش توهم در RAG مراجعه کنید.



گفتگو