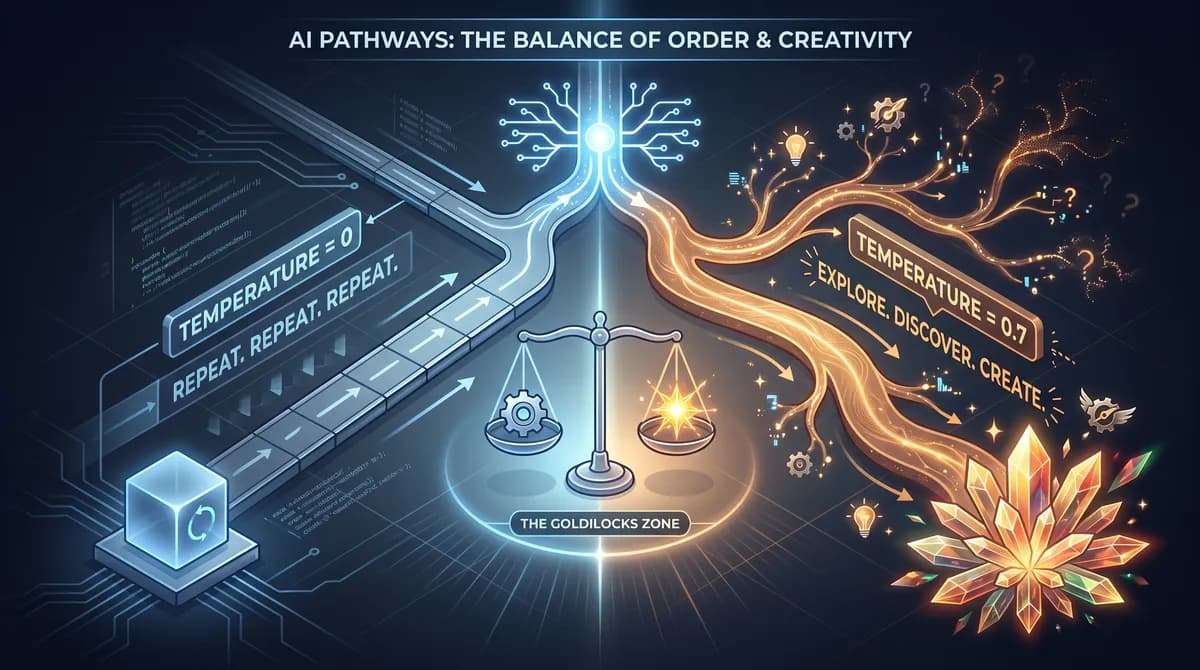
تصور کنید یک برنامهنویس یا نویسنده است که هر بار از هوش مصنوعی میخواهد متنی بنویسد، دقیقاً همان جملات خشک و قابلپیشبینی را دریافت میکند. اگر مدل شما بیش از حد «مطیع» و پیشبینیپذیر باشد، در واقع فرصت رسیدن به بهترین و غیرمنتظرهترین پاسخها را از دست داده است. در حالی که تنظیم دما روی صفر، قابلیت اطمینان را تضمین میکند، اما مدل را به رباتی تبدیل میکند که مکرراً راهکارهای برتر اما غیربدیهی را نادیده میگیرد.
این تنش میان پیشبینیپذیری و آشوب، همان چیزی است که «پارادوکس دما» نامیده میشود. در علوم شناختی و یادگیری تقویتی، این وضعیت به عنوان موازنه میان اکتشاف (Exploration) و بهرهبرداری (Exploitation) شناخته میشود؛ بهرهبرداری یعنی تکیه بر آنچه پیشتر جواب داده است، اما اکتشاف به دنبال احتمالات جدید میگردد.
به نقل از گزارش ۲۹ ژوئن ۲۰۲۶ در وبسایت dev.to، نویزی که از طریق تنظیمات دمای بالاتر ایجاد میشود، یک نقص فنی نیست، بلکه ویژگی بنیادی هوش است. مدلی که هرگز مسیرهای جدید را جستوجو نکند، در یک «بهینه محلی» گیر میکند و هرگز نمیتواند نوآوری کند یا مسیرهای بهتری را کشف نماید. همانطور که در تحلیلهای قبلی ما دربارهی امنیت مدلهای بازمتن دیدیم، توازن در پارامترها تعیینکننده خروجی است. این چالش توازن تنها در پارامترهای دمایی نیست، بلکه در مدیریت حافظه نیز دیده میشود؛ جایی که افزایش حافظهی بلندمدت در مدلهای زبانی میتواند منجر به رفتارهایی نظیر چاپلوسی و کاهش دقت شود.
فلسفه تصادفیبودن
هوش واقعی نیازمند توانایی دوگانه در شناسایی الگوها و تولید الگوهای جدید است. وقتی یک مدل کاملاً قطعی (Deterministic) باشد، در «تله قطعی بودن» میافتد؛ یعنی همیشه محتملترین مسیر را انتخاب میکند و جایگزینها را نادیده میگیرد.
در مقابل، «مزیت آشوب» به مدلی که کمی تصادفی است اجازه میدهد گهگاه مسیرهای کماحتمالتر را طی کند. این تصادفیبودن صرفاً یک خطا نیست؛ بلکه در علوم شناختی، اکتشاف برای یادگیری ضروری است. این فرآیند درست مثل کودکی است که با امتحان کردن چیزهای اشتباه یاد میگیرد، یا دانشمندی که با آزمایش فرضیات شکستخورده به حقیقت میرسد؛ در واقع انحرافات تصادفی به عنوان موتور کشف عمل میکنند.
مکانیک تنظیم دما
پارامتر دما (Temperature) به عنوان پارامتری عمل میکند که انتخاب توکنها را در حین تولید متن کنترل میکند. توکنها — که شبیه برشهای کوچک از یک کیک طولانی هستند و مدل آنها را تکهتکه میخورد — بر اساس این تنظیمات انتخاب میشوند:
- دما = ۰ (حریص/Greedy): مدل همیشه محتملترین توکن بعدی را میبرد. خروجی قطعی، ایمن، تکراری و اغلب کسالتبار است.
- دما = ۱ (متعادل): مدل از توزیع احتمالات نمونهبرداری میکند. گاهی توکنهای کماحتمالتر را انتخاب میکند که باعث میشود خروجی متنوع، خلاقانه و گاهی غافلگیرکننده شود.
- دما > ۱ (آشفته): مدل توزیع احتمالات را تخت میکند. در این حالت توکنها تقریباً به صورت تصادفی انتخاب میشوند و نتیجهای با خلاقیت بسیار بالا اما اغلب بیمعنی و نامفهوم میسازد.
بهینهسازی بر اساس هدف
هیچ دمای «بهترین» و جهانی برای همه کارها وجود ندارد و تنظیمات بهینه کاملاً به هدف شما بستگی دارد:
- پرسش و پاسخهای واقعگرایانه: برای سوالاتی مثل «پایتخت فرانسه کجاست؟»، دمای پایین (حدود ۰.۱) لازم است. در اینجا شما به دنبال محتملترین و درستترین پاسخ هستید.
- کارهای خلاقانه: برای پرامپتهایی مثل «شعری درباره گربه بنویس»، دمای بالا (حدود ۰.۹) کاربرد دارد تا ترکیبهای غافلگیرکننده و ظرافتهای شاعرانه ایجاد شود.
بر اساس بررسی منابع متعدد، برخی مدلهای پیشرفته اکنون از «دمای پویا» استفاده میکنند. این مدلها سطح تصادفیبودن خود را بر اساس بستر (Context) خاص هر پرامپت تغییر میدهند تا توازنی میان نوآوری و انسجام برقرار کنند. در دنیای توسعه نرمافزار، این توازن میان دقت و خلاقیت بر کیفیت کد اثر میگذارد و میتواند منجر به ایجاد هزینههای پنهانی تحت عنوان شاخص PDR در محیطهای عملیاتی شود.
موازنه اکتشاف و بهرهبرداری
این معمای کلاسیک در یادگیری تقویتی، فراتر از یک مسئله فنی و در واقع فلسفی است. بهرهبرداری نتایج قابلاعتمادی میدهد اما خطر رکود را به همراه دارد. اکتشاف ریسک شکست دارد اما میتواند نتایج برتر را کشف کند. این وضعیت بازتابی از خودِ زندگی است؛ اینکه انسان ترجیح دهد در شغل فعلی خود بماند یا برای دستیابی به چیزی جدید، ریسک تغییر را بپذیرد.
هزینه خلاقیت
برای درک بهتر، مثال یک موتور شطرنج را در نظر بگیرید. یک موتور قطعی با یک تابع ارزیابی ثابت، قوی است اما پیشبینیپذیر است. در مقابل، موتوری با کمی تصادفیبودن ممکن است برخی بازیهای تکبهتک را با انتخاب حرکات غیربهینه ببازد، اما میتواند استراتژیهای کاملاً جدیدی را کشف کند که یک سیستم قطعی هرگز به آنها فکر نمیکرد.
این موضوع نشان میدهد که خلاقیت نیازمند یک تمایل سیستماتیک به «اشتباه کردن» است. مدل قطعی هرگز اشتباه نمیکند، اما هرگز درخشان هم نیست. در واقع، تمایل به اشتباه کردن، بهای پرداخت شده برای خلاقیت است. این «منطقه طلایی» (Goldilocks Zone) از تصادفیبودن اجازه میدهد مدل غافلگیرکننده باشد اما همچنان انسجام خود را حفظ کند.
اگر مقدار تصادفیبودن خیلی کم باشد، مدل خستهکننده شده و جملات خود را تکرار میکند. اگر خیلی زیاد باشد، مدل آشفته و غیرقابلاعتماد میگردد. برای کاربر، این یعنی دمای بهینه بیشتر یک ترجیح شخصی است تا یک ثابت فنی.
آزمایش با این مقادیر به کاربران اجازه میدهد تا هوش مصنوعی را از یک ماشینحساب سخت و صلب به یک همکار خلاق تبدیل کنند. با جابهجا کردن این لغزنده (Slider)، شما کنترل میکنید که آیا AI از الگوهای شناختهشده بهرهبرداری کند یا در ناشناختهها به اکتشاف برود. وقتی میپرسید «معنای زندگی چیست؟»، توکن نهایی انتخاب شده تصادفی نیست، بلکه نقطه culminating یا اوج این مسیرهای احتمالی است.
گام بعدی شما
- در ابزارهای توسعه مدل، مقدار دما را بین ۰.۲ (برای تحلیل داده) و ۰.۸ (برای ایدهپردازی) جابهجا کنید تا تفاوت خروجی را حس کنید.
- اگر از APIها استفاده میکنید، پارامتر Temperature را بر اساس نوع تسک (دقیق در برابر خلاق) در هر درخواست تغییر دهید.
- بررسی کنید آیا مدل مورد استفاده شما قابلیت تنظیم دمای پویا یا نمونهگیری هستهای (Top-p) را دارد یا خیر.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو