
تصور کنید یک برنامه نویس ارشد، روزانه ۱۰۰۰ دلار هزینه توکن پرداخت میکند تا کدهایش را بنویسد؛ این رقم دیگر یک ادعای تبلیغاتی یا هایپ ساده نیست، بلکه به یک ضرورت استراتژیک تبدیل شده است. در حالی که موج اول «توکن-بیشوری» (Tokenmaxxing) بر این تمرکز داشت که کارکنان را به هر قیمتی مجبور به پذیرش ابزارها کنند، رژیم جدیدی به نام «صحت ترکیبی» (Compounding Correctness) ظهور کرده است. در این وضعیت، میزان هزینه خالص محاسباتی، مستقیماً کیفیت خروجی نهایی را دیکته میکند. اگر امروز از مدلهای زبانی برای کارهای جدی استفاده میکنید، باید بدانید که کیفیت خروجی حالا مستقیماً به میزان سرمایهگذاری شما روی محاسبات گره خورده است.
به طور کلی، وقتی ده هزار دلار هزینه میکنید، منتظر بازگشت سرمایه هستید. مصرفکنندگان عادی ممکن است هزاران دلار در اپلیکیشنهای شرطبندی هزینه کنند — مثلاً ۱۰۰ دلار شرط ببندند که «ومبی» در حالی که وارونه ایستاده و سرود ملی فرانسه را میخواند، یک پرتاب ۳ امتیازی موفق داشته باشد — یا برای هیجان، در سیستمهای گاشا بازی Genshin Impact پول بریزند. اما مدیران کسبوکار معمولاً پول خود را صرفاً برای اینکه «احساس خوبی داشته باشند»، نمیسوزانند. حتی کسی با قدرت رایدهی مارک زاکربرگ هم اعلام نمیکند که متا قرار است برای تفریح بودجه را آتش بزند. در شرکتهای بزرگ و حیاتی، هیچ اقدامی صرفاً برای خودِ آن اقدام صورت نمیگیرد، مگر در یک مورد استثنایی.
این تغییر در حالی رخ میدهد که عاملهای هوش مصنوعی (AI Agents) — شبیه دستیاران اداری که میتوانند بهتنهایی کارهای پیچیده را پیش ببرند — از رابطهای سادهٔ چت به «کارخانههای نرمافزاری» خودکار تبدیل میشوند. این تحول در ساختار عملیاتی، در واقع همان عاملی است که مدلهای اشتراکی ثابت را به خطر انداخته و مدلهای پرداخت توکنمحور را جایگزین کرده است. برای ماهها، صنعت هزینهٔ بالای توکن را یک اتلاف بودجه میدید؛ محصولی جانبی از تصمیمات مدیران در شرکتهایی مثل Meta که ارزیابی عملکرد کارکنان را به میزان مصرف توکن گره زده بودند. این سیاست منجر به رفتارهای مضحکی شد؛ مثلاً کارمندانی که دو عامل را میساختند تا تمام روز با هم حرف بزنند و فقط سهمیه توکن خود را پر کنند تا در ارزیابی سالانه پذیرفته شوند. به نظر بسیاری از ناظران، این یعنی رهبران کسبوکار صرفاً احمق بودهاند و آنها را تشویق کردهاند که بدون هیچ انتظار بازگشتی، پول را روی توکنها بریزند.
استراتژی زور خالص
با این حال، یک دیدگاه مخالف پیشنهاد میکند که این اتفاق هرگز تصادفی نبود. موضوع این نبود که مدیران به طور اتفاقی کارکنان را به سوزاندن توکنها در کارهای بیهوده تشویق کردند؛ بلکه آنها عامدانه این کار را کردند. این یک تاکتیک روانشناختی در سطح سازمانی بود.
چند ماه پیش، بسیاری از افراد ارشد با اعتبار بالا در سازمانها، مقاومت شدیدی در برابر استفاده از ابزارهای هوش مصنوعی داشتند. وقتی هم که از آنها استفاده میکردند، اغلب به گونهای — چه تصادفی و چه عمدی — عمل میکردند که منجر به نتایج بد میشد و این بدبینی را تقویت میکرد. آنها ابزارهای جدید را به عنوان تهدیدی برای جایگاهشان یا صرفاً بازیچههای بیفایده میدیدند.
سیاستهای تحمیلی توکن-بیشوری از بالا به پایین، یک تکنیک «زور خالص» برای شکستن آن دیوار مقاومت بود. هرچند این روش خشن بود، اما گاهی برای ایجاد یک گشایش و تحول، به نیروی بروت (Brute Force) نیاز دارید. این روش جواب داد. امروز تقریباً همه برای کدنویسی، دستکم به مقدار کمی از AI استفاده میکنند و اکثر تیمها از Cursor در نوار کناری استفاده میکنند تا سرعت توسعه خود را افزایش دهند.
پایان یارانههای نامحدود
این دوران اولیه از توکن-بیشوری در حال به پایان رسیدن است. با حرکت OpenAI و Anthropic به سمت عرضه سهام در بورس (IPO)، آنها «سوخت» اشتراکهای خود را محدود کرده و قیمتهای API را افزایش دادند تا مدلهای درآمدی خود را بهینه کنند. با ناپدید شدن یارانههای توکن، شرکتها در حال لغو سیاستهای هزینه نامحدود هستند. اما در حالی که انگیزههای اولیه از بین رفت، یک انگیزه قدرتمندتر جایگزین شد.
ما از دوران «خطای ترکیبی» — جایی که عاملهای طولانیمدت لزوماً دچار توهم (Hallucination) میشدند و پروژهها را نابود میکردند — به وضعیتی رسیدهایم که در آن تکرارهای بیشتر منجر به نتایج بهتر میشود. در رژیم قدیمی، هر خطای کوچک مدل، مثل گلوله برفی رشد میکرد و غیرقابل بازگشت در پروژه تثبیت میشد. اگر هزینه بیشتر برای توکنها منجر به کار بدتر میشد، هیچ دلیلی نداشت که عاملها را ۲۴ ساعته اجرا کنیم. به عبارت دیگر، چه فایدهای دارد که یک شیطان کوچک در کامپیوترتان تمام شب کار کند اگر قرار است فقط تمام زحمات شما را پارهپاره کند؟
اکنون ما «صحت ترکیبی» داریم: هرچه توکنهای بیشتری صرف کنید تا یک وظیفه درست انجام شود، احتمال رسیدن به نتیجه خوب بیشتر است. هرچه توکنهای بیشتری خرج کنید، نتیجه بهتر خواهد بود. در واقع، هزینه محاسباتی اکنون به جای ایجاد خطا، به عنوان ابزاری برای پالایش و اصلاح نتایج عمل میکند.
اقتصاد «صحت ترکیبی»
این منطق جدید در حوزههای حساس مثل امنیت سایبری به شدت دیده میشود. هفته گذشته، گزارشهایی درباره مدل Mythos ساخت شرکت Anthropic منتشر شد؛ مدلی که چنان در وظایف امنیتی توانمند است که انتشار عمومی آن محدود شد تا از سوءاستفادههای احتمالی جلوگیری شود. مؤسسه ایمنی هوش مصنوعی (AISI) این مدل را با بودجه ۱۰۰ میلیون توکن برای هر بار تلاش آزمایش کرد تا مرزهای توانایی آن را بسنجد.
هزینههای این اجراها قابل توجه بود:
- هر تلاش با مدل Mythos تقریباً ۱۲,۵۰۰ دلار هزینه داشت.
- مجموع ده اجرای مدل، ۱۲۵,۰۰۰ دلار هزینه برد.
- نکته کلیدی این است که AISI هیچ نشانی از «بازده نزولی» (Diminishing Returns) ندید؛ یعنی مدلها با افزایش بودجه توکن، همچنان به پیشرفت و بهبود نتایج ادامه دادند و هر توکن اضافی، احتمال کشف حفرههای امنیتی جدید را بالا میبرد.

این وضعیت، یک «اقتصاد اثباتِ کار» (Proof of Work) در امنیت ایجاد میکند. برای ایمنسازی یک سیستم، مدافع باید توکنهای بیشتری برای کشف آسیبپذیریها هزینه کند تا آنچه مهاجم برای اکسپلویت کردن آنها صرف میکند. در اینجا باهوش بودن امتیاز نمیآورد؛ برنده کسی است که بیشتر پرداخت میکند و منابع محاسباتی بیشتری میسوزاند. موفقیت به حجم محاسبات خام گره خورده است، دقیقاً شبیه سیستم اثبات کار در ارزهای دیجیتال. این یک «لاتاری با دمای پایین» است: توکنها را بخرید، امیدوار باشید که اکسپلویت را پیدا کنید و امیدوار باشید که مدت زمان تلاش شما طولانیتر از مهاجمان باشد.
ظهور «حلقهها» و کارخانه نرمافزاری
این تغییر, دلیل وسواس اخیر صنعت روی «حلقهها» (Loops) است. این رویکرد که توسط Boris Cherny، خالق Claude Code، رواج یافت، شامل اجرای مداوم یک عامل تا پایان نوبتش و سپس شروع مجدد همان پرامپت است. با کمی هوشمندی، یک عامل میتواند یک مشخصات فنی سنگین را بگیرد و آن را بهطور خودکار به بخشهای کوچکتر تقسیم کند تا در طول زمان و بدون نظارت انسانی حل شود. در این مدل، هوش مصنوعی خودش را تصحیح کرده و در هر دور از حلقه، به پاسخ دقیقتری نزدیک میشود.
در حالی که این مفهوم از جولای گذشته (با نام حلقه رالف ویگام) وجود داشت، اما اکنون به دلیل «صحت ترکیبی» کاربردی شده است. شما میتوانید هر طور که بخواهید دستور بدهید و مدل بهطور کلی با هر بار تکرار حلقه، عملکرد بهتری خواهد داشت. صنعت حالا به بلوغ رسیده و نام «رالف ویگام» را کنار گذاشته است چون این روش دیگر یک شوخی یا تلاش بیهوده نیست، بلکه یک متد مهندسی است.

این روند منجر به ایجاد «کارخانه تاریک» (Dark Factory) میشود؛ یک پایگاه کد که بهطور خودکار کد تولید میکند، آن را بازبینی میکند، باگها را میگیرد و تست مینویسد، بدون اینکه انسانی نظارت کند. انسان فقط یک مشخصات (Spec) را وارد میکند و در نهایت یک اپلیکیشن تحویل میگیرد. در حالی که برخی شرکتها مثل StrongDM استدلال میکنند مهندسان باید روزانه ۱۰۰۰ دلار هزینه توکن کنند تا حداکثر بهرهوری را داشته باشند، پیادهسازیهای واقعی متفاوت است. برخی کارخانههای نرمافزاری فعلی حدود ۶۰۰ دلار در ماه هزینه میکنند. هرچند عدد ۱۰۰۰ دلار در روز ممکن است برای ایجاد جنجال و هایپ باشد، اما حاوی یک حقیقت است: انگیزه برای هزینههای نجومی توکن درونی شده و منتظر انتشار است تا به محض اینکه مدلها ارزانتر شوند یا توانمندتر، گسترش یابد.
آرربیتاژ مدلهای باز
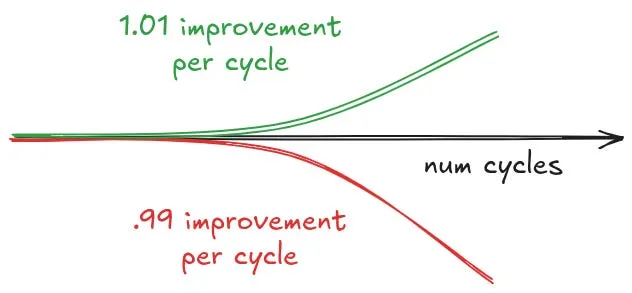
هزینههای بالا باعث چرخش به سمت مدلهای وزنهای باز (Open Weights) شده است. آزمایشگاههای پیشرو برای توجیه هزینههای نجوم توکن در برابر مدیران مالی (CFO) به مشکل میخورند. اگر یک مدل پیشرو در هر تکرار ۱.۱ برابر بهبود ایجاد کند، اما یک مدل باز مثل GLM 5.2 با کسری از آن هزینه، بهبود ۱.۰۵ برابری داشته باشد، مدل باز برنده است؛ چون میتوان حلقه را دفعات بسیار بیشتری اجرا کرد تا به نتیجه برتر رسید. این یک بازی ریاضی است: تعداد تکرار بیشتر با مدل ارزانتر، بر کیفیت بالاتر در تکرار کمتر با مدل گرانقیمت غلبه میکند.
مقایسه قیمتها در ژوئن ۲۰۲۶:
- GLM 5.2: حدود ۱.۴ دلار برای هر میلیون توکن ورودی / ۴ دلار برای خروجی.
- Anthropic Opus 4.X: ۵ دلار برای ورودی / ۲۵ دلار برای خروجی.
- Haiku 4.5: ۱ دلار برای ورودی / ۵ دلار برای خروجی.
مدل GLM 5.2 در برخی بنچمارکها حتی از GPT 5.5 قویتر است و Haiku را بهراحتی شکست میدهد. کسانی که نمیخواهند به یک ارائهدهنده خاص وابسته شوند (Provider Lock-in) و میخواهند کنترل کاملی بر هزینهها داشته باشند، ابزارهایی را میپذیرند که میتوانند روی تمامی بازیکنان اصلی بازار قرار گیرند و بر اساس هزینه و کیفیت، مدل را سوییچ کنند.
شکستهای خط لوله و اتلاف عاملمحور
البته هر هزینهای بهرهور نیست. بسیاری از اتلافها ناشی از درک نادرست از نحوه ساخت ابزارهاست. پیش از ظهور ابزارهای بهتری مثل Claude Code، بسیاری عاملهای سفارشی را با فریمورکهای «AI-native» مثل Pydantic یا Langchain میساختند که در مواجهه با پیچیدگیهای واقعی شکست میخوردند.
مدیران به اشتباه تصور میکردند اینها شبیه «گردشکارهای Zapier» هستند و برای کارهای یکباره (مثل برچسبگذاری دادهها) به جای استفاده از کدهای قطعی (Deterministic) و ساده، خطوط لوله پردازش داده عاملمحور را خواستند. این عاملها هم گرانتر بودند و هم دقت کمتری داشتند زیرا برای کارهایی طراحی نشده بودند که نیاز به دقت ۱۰۰٪ دارد. برای حل این مشکل، شرکتها عاملهای «کنترل کیفیت» ساختند تا عاملهای اول را نظارت کنند و بدین ترتیب هزینه توکن سه برابر شد بدون اینکه مشکل دقت حل شود. به همین دلیل بسیاری از این خطوط لوله که توسط مشاورانی با میلیاردها دلار هزینه ساخته شده بودند، هرگز درست کار نکردند و در نهایت به زباله دیجیتال تبدیل شدند. این تضاد بین کاهش قیمت واحد توکن و افزایش کل هزینههای عملیاتی، دقیقاً همان چیزی است که در تحلیل ما درباره پارادوکس جِونز و دلیل افزایش هزینههای هوش مصنوعی سازمانی بررسی شده است.
اکنون دو نوع «توکن-بیشوری» (Tokenmaxxing) متمایز داریم:
- توکن-بیشوری توسعهدهنده: استفاده از ابزارهایی مثل Claude Code و حلقهها برای افزایش بهرهوری مهندسان. این مورد عموماً بازگشت سرمایه (ROI) خوبی دارد چون زمان توسعه را به شدت کاهش میدهد.
- توکن-بیشوری خط تولید: استفاده از عاملهای شکننده و غیرقطعی برای کارهای خاص. این مورد فقط در صورتی مفید است که خط لوله واقعاً کار کند، که غالباً نمیکنند. این مورد اغلب نتیجهی مشاورانی است که ۲ میلیون دلار میگیرند تا یک فایل مهارت ساده برای یک عامل generalist بنویسند و نام آن را «عامل سفارشی» میگذارند تا مبلغ بیشتری دریافت کنند.
ژئوپلیتیک و تغییرات سختافزاری
به موازات این تغییرات فنی، مقررات دولتی سختتر میشود. در ۲۸ ژوئن ۲۰۲۶، OpenAI پیشنمایش محدودی از سری GPT-5.6 را آغاز کرد:
- Sol: مدل پرچمدار برای پیچیدهترین تحلیلها.
- Terra: مدل متوازن برای کارهای روزمره (۲ برابر ارزانتر از GPT-5.5).
- Luna: مدل سریع و ارزان با کمترین هزینه برای عملیاتهای حجیم.
به درخواست دولت آمریکا، این مدلها فقط برای «شرکرهای مورد اعتماد» در دسترس هستند تا چارچوب فرمان اجرایی سایبری توسعه یابد. واشینگتن پست گزارش داد که دولت ترامپ برخلاف شعارهای laissez-faire (عدم مداخله)، نظارت را افزایش داده و بهطور غیرشفاف، برنده و بازنده صنعت هوش مصنوعی را انتخاب میکند تا تسلط ایالات متحده حفظ شود.
به همین ترتیب، دولت آمریکا اخیراً محدودیت دسترسی به مدل Mythos شرکت Anthropic را پس از مذاکرات روزانه شدید و کنترلهای صادراتی لغو کرد و به بیش از ۱۰۰ مؤسسه و سازمان اجازه دسترسی داد تا از تواناییهای امنیتی آن در برابر تهدیدات خارجی استفاده کنند. در حالی که Mythos بازگشته است، وضعیت مدل Fable 5 — که زمانی قدرتمندترین مدل در دسترس مصرفکنندگان بود — نامشخص است، هرچند گزارشها از احتمال انتشار قریبالوقوع آن حکایت دارد.
زیرساختها نیز برای حمایت از این آینده توکنمحور تکامل مییابند. OpenAI بهتازگی Jalapeño را معرفی کرد؛ یک پردازنده استنتاج سفارشی که با همکاری Broadcom ساخته شده و نکته جالب این است که خود مدلهای OpenAI در طراحی و توسعه این تراشه نقش داشتهاند. همچنین ابزارهای جدید روی ماشینهای Cerebras که اجازه تولید حدود ۷۵۰ توکن در ثانیه را میدهند، هوش مصنوعی را از کارهای «آفلاین» و غیرهمزمان به عملیات همزمان و در لحظه برمیگردانند، همانطور که در دموهایی مثل chatjimmy.ai دیده شد. این سرعت بالا به کاربران اجازه میدهد بدون وقفه با مدلهای عظیم تعامل داشته باشند.

این یعنی «توکن-بیشوری» که به عنوان یک اشتباه شرکتی شروع شد، حالا به یک استراتژی معماری مشروع (Legit) تبدیل شده است. برندگان کسانی خواهند بود که بتوانند هزینه توکن را به شکل بهینه مقیاسبندی کنند و در عین حال، خود را به یک ارائهدهنده خاص وابسته نکنند. تحلیلها نشان میدهد ما به عصر «زور خالص» در هوش مصنوعی میرویم. وقتی هوش را میتوان از طریق حلقههای تکرار خرید، مزیت رقابتی از «کیست که پرامپت بهتری مینویسد» به «کیست که خط لوله بهینهتر و بودجه محاسباتی بیشتری دارد» تغییر میکند.
گام بعدی شما
- اگر از عاملهای هوش مصنوعی استفاده میکنید، بهجای تکیه بر یک پاسخ واحد، مکانیسم «حلقه» (Loop) را برای تکرار و اصلاح خروجی پیاده کنید تا به صحت ترکیبی برسید.
- هزینههای استنتاج خود را با مدلهای وزنهای باز مقایسه کنید تا ببینید آیا افزایش تعداد تکرارها با مدل ارزانتر، نتیجه بهتری نسبت به یک بار اجرای مدل گرانقیمت میدهد.
- برای کارهای تکراری و ساختاری، از کدهای قطعی (Deterministic) استفاده کنید و از سپردن آنها به عاملهای غیرقطعی (Non-deterministic) بپرهیزید تا از اتلاف بودجه جلوگیری کنید.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو