
آیا یک تغییر جزئی در محاسبات logprob میتواند کل یک فرآیند آموزشی RL را به فنا دهد؟ برای تیمهایی که در حال مهاجرت به vLLM V1 هستند، پاسخ یک «بله» قاطع است.
در ۶ مئی ۲۰۲۶، به نقل از گزارش فنی وبسایت huggingface.co، تلاشی برای رفع «عدم تطابق آموزش-استنتاج» (train-inference mismatch) در هنگام انتقال از نسخه ۰.۸.۵ (V0) به نسخه ۰.۱۸.۱ (V1) صورت گرفت. طبق گزارش این تیم، هرگونه اختلاف در نحوه محاسبه لگپراپ (logprob) بهطور بنیادی دینامیکهای آموزشی را تغییر داده و منجر به منحنیهای پاداش واگرا و بیثباتی در آنتروپی میشود.
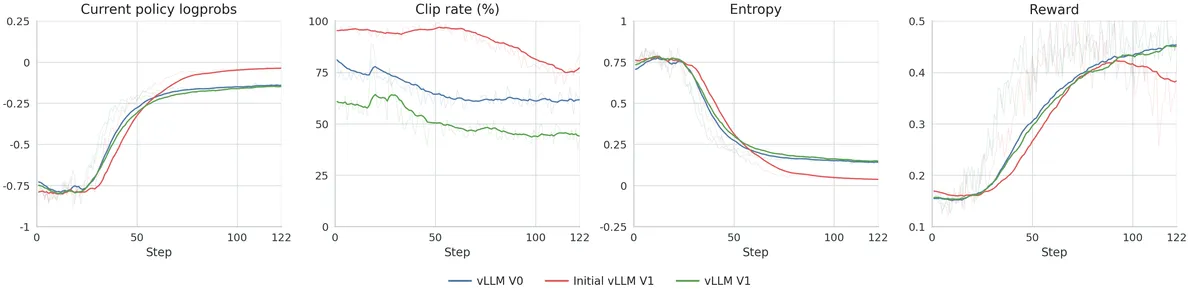
بر اساس این مستندات، تلاشهای اولیه برای مهاجرت به V1 شکست خورد؛ زیرا لگپراپها و پاداشهای سمت آموزشدهنده در مراحل ابتدایی، از مرجع V0 فاصله گرفتند. این شکاف بهویژه در نرخ کلیپ (clip rate) — که فاصله پالیسی بین rollout و آموزشدهنده را ردیابی میکند — مشهود بود.
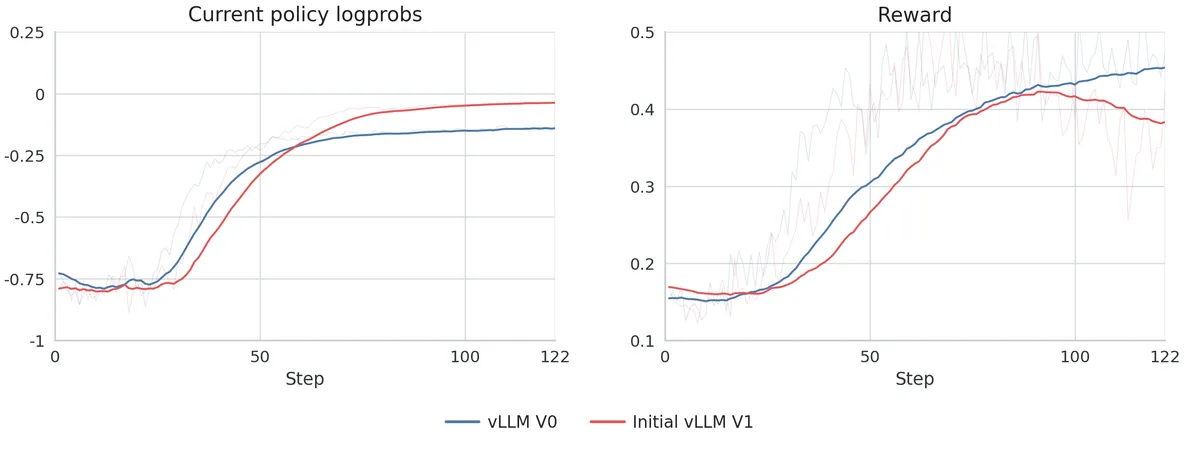
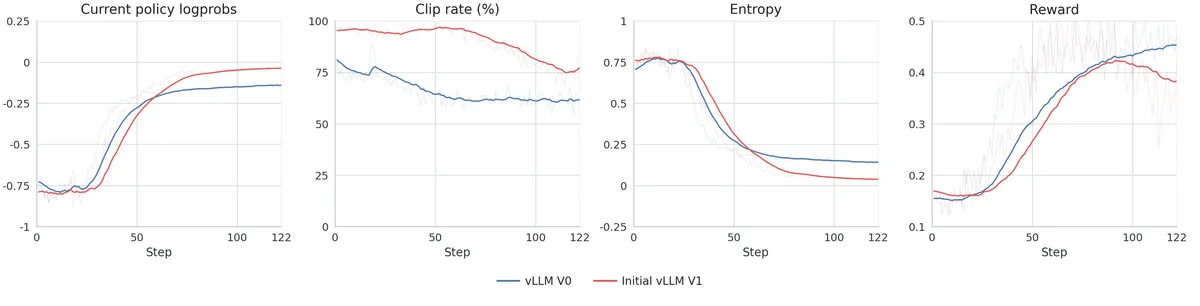
برای حل این بحران، تیم مذکور چهار نقطه شکست حیاتی را شناسایی و اصلاح کرد:
- معناشناسی لگپراپ (Logprob Semantics): نسخه V1 بهطور پیشفرض از خروجیهای خام مدل استفاده میکند. برای تطبیق با توزیع مورد انتظار آموزشدهنده، تغییر به حالت
logprobs-mode=processed_logprobsضروری بود. - پیشفرضهای زمان اجرا (Runtime Defaults): قابلیتهایی مانند کش پیشوندی (prefix caching) و زمانبندی نامتقارن (async scheduling) تفاوتهایی در طول عمر کش ایجاد میکردند که برای رسیدن به تطابق کامل، باید غیرفعال میشدند.
- بهروزرسانی وزنها (Weight Updates): پیادهسازی توالی خاصی با استفاده از
pause_generation(mode="keep", clear_cache=False)برای شبیهسازی رفتار V0 در بازگشت به حالت قبلی بدون ابطال کش. - دقت عددی (Numerical Precision): در نهایت، استفاده از یک سر پیشبینی fp32 (fp32 lm_head) برای آخرین تصویرسازی (projection) لازم بود تا از تأثیر تغییرات کوچک لوجیت بر نسبتهای پالیسی جلوگیری شود.
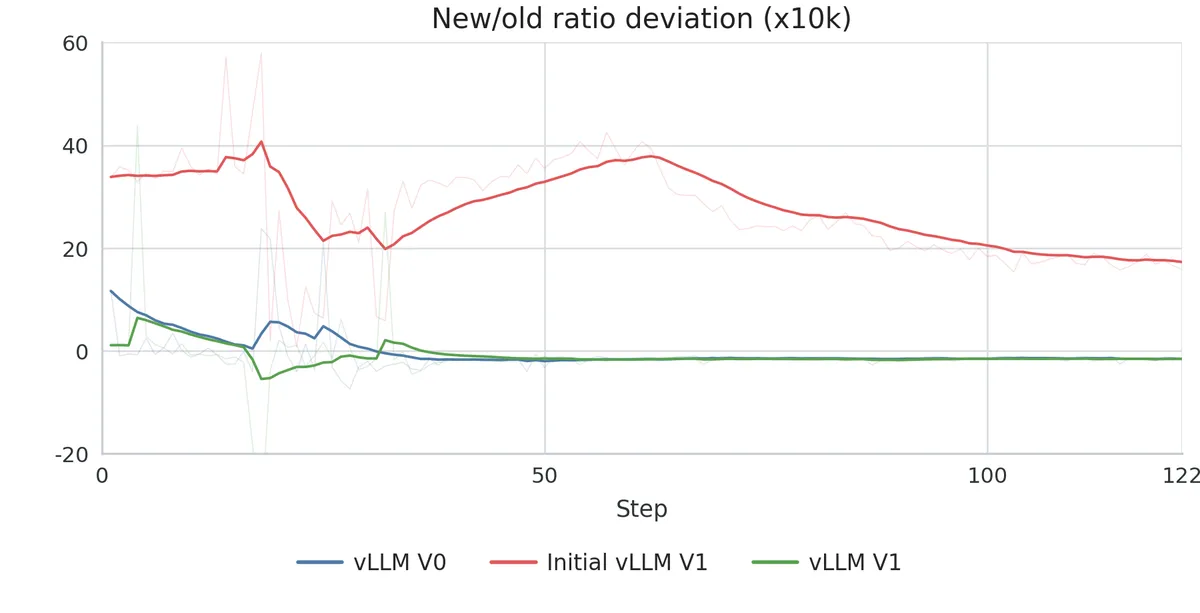
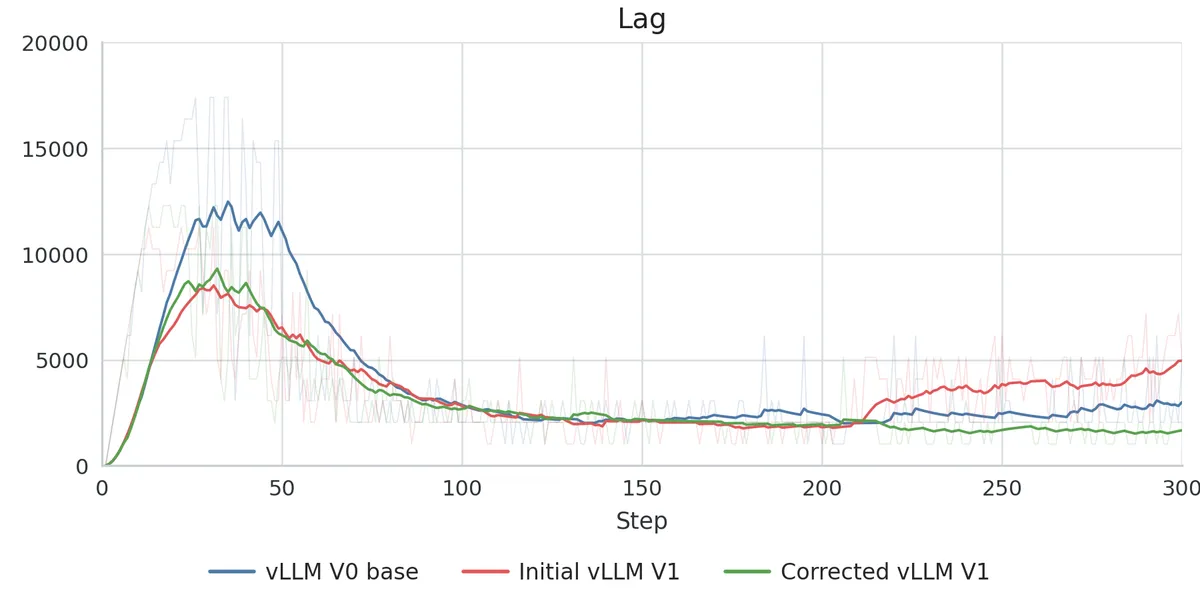
همانطور که در تحلیل قبلی ما دربارهی کتابخانههای عاملمحور (agentic) مبتنی بر C اشاره کردیم، پایداری زیرساخت، سنگبنای رفتارهای پیچیده در هوش مصنوعی است. بدون تطابق کامل در لایهی بکاند، اصلاحات در سمت هدف (objective-side) مانند وزندهی مجدد نسبت اهمیت، تنها باعث پوشاندن رفتارهای معیوب استنتاج (inference) میشود.
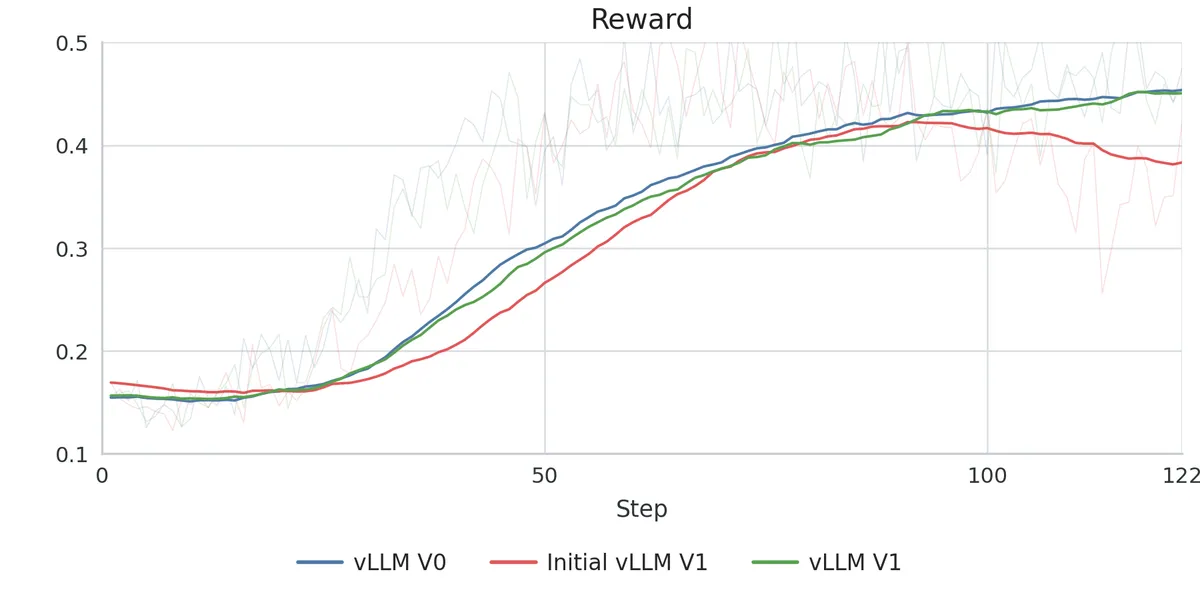
با مقیاسپذیری سیستمهای RL، احتمالاً صنعت بهسوی «دستورالعملهای تطبیق» استاندارد حرکت خواهد کرد تا از این شکستهای خاموش و فاجعهبار در هنگام ارتقای موتورها جلوگیری شود. اما این تنها بخشی از چالش است؛ تأثیر این تغییرات بر مدلهای استدلالی در گزارش بعدی ما بررسی خواهد شد.
گام بعدی شما
- اگر در حال مهاجرت به vLLM V1 هستید، ابتدا حالت
processed_logprobsرا فعال کنید. - در محیطهای حساس RL، تمامی بهینهسازیهای کش پیشوندی را برای تست تطبیق غیرفعال کنید.
- برای جلوگیری از واگرایی پالیسی، از دقت fp32 در لایهی lm_head استفاده کنید.



گفتگو