
اگر استنتاج مدلهای زبانی را در مقیاس بالا اجرا میکنید، احتمالاً متوجه شدهاید که خروجیهای «قطعی» شما در دمای صفر، بسته به تعداد کاربرانی که از یک GPU استفاده میکنند، تغییر میکنند. در ۲۸ می ۲۰۲۶، یک مقاله پژوهشی مکانیزم MarginGate (arXiv 2605.30218) را معرفی کرد؛ مکانیزمی که برای متوقف کردن تغییرات خاموش توکنها (Silent Token Flips) طراحی شده است. این اتفاقات در حین رمزگشایی BF16 در محیطهای دستهبندی مداوم (Continuous Batching) رخ میدهند.
بسیاری از توسعهدهندگان تصور میکنند تنظیم دما روی صفر، خروجی یکسانی را برای یک پرامپت در هر بار اجرا تضمین میکند. اما در واقعیت، محاسبات ریاضی BF16 (bfloat16) — که مثل یک ترازو با دقت پایین است و برخی ارقام کوچک را رند میکند — کاملاً شرکتپذیر (Associative) نیست. این یعنی ترتیب جمع کردن اعداد در GPU میتواند نتیجه نهایی را تغییر دهد. چون هستههای GPU ترتیب این کاهش (Reduction) را بر اساس اندازه دسته تغییر میدهند، یک درخواست ممکن است وقتی تنها پردازش میشود یک توکن تولید کند و وقتی با درخواستهای دیگر گروه میشود، توکنی متفاوت ارائه دهد.
زمینه: شکاف در قطعیت (The Determinism Gap)
همانطور که در تحلیلهای قبلی ما دربارهی بهینهسازیهای لایهی استنتاج اشاره کردیم، این عدم تغییرناپذیری نسبت به اندازه دسته (Batch-Invariance)، یک شکست بحرانی برای تیمهایی است که به ارزیابیهای تکرارپذیر، کشینگ و حسابرسی تکیه میکنند. تکرارپذیری برای این فرآیندها یک رکن حیاتی است؛ اگر خروجی یک پرامپت بهطور خاموش بر اساس بار فعلی سرور تغییر کند، عیبیابی سیستم عملاً غیرممکن میشود.
ریشه این مشکل در تضاد بین BF16 و FP32 است. BF16 فرمتی ۱۶ بیتی برای استنتاج سریع است. این فرمت محدوده توان (Exponent) مربوط به FP32 را حفظ میکند اما بیتهای مانتیسا (Mantissa) را حذف میکند. این موضوع باعث میشود خطاهای رند کردن بزرگتر شوند؛ آنقدر بزرگ که ترتیب یک جمع میتواند نتیجه را تغییر دهد. در مقابل، FP32 (اعشاری ۳۲ بیتی) کندتر است اما دقت بسیار بالایی دارد و به عنوان مرجع مورد اعتماد برای صحت محاسبات عمل میکند.
در محیطهای دستهبندی مداوم — جایی که درخواستها در هر گام به دسته اضافه شده یا از آن خارج میشوند — اندازه دسته یک درخواست از هر اجرا به اجرای دیگر متفاوت است. این یعنی ترتیب کاهش اعداد شناور جابهجا شده و نتایج (Logits) نیز همراه با آن تغییر میکنند. اجرای کامل تمام مراحل در FP32 قطعیت را برمیگرداند، اما برای محیط تولید بسیار کند است. MarginGate راه میانی را پیشنهاد میدهد؛ شبیه به خط بازرسی فرودگاه که فقط مسافران مشکوک را به بازرسی دقیق میفرستد.
مکانیزم Margin-Gating
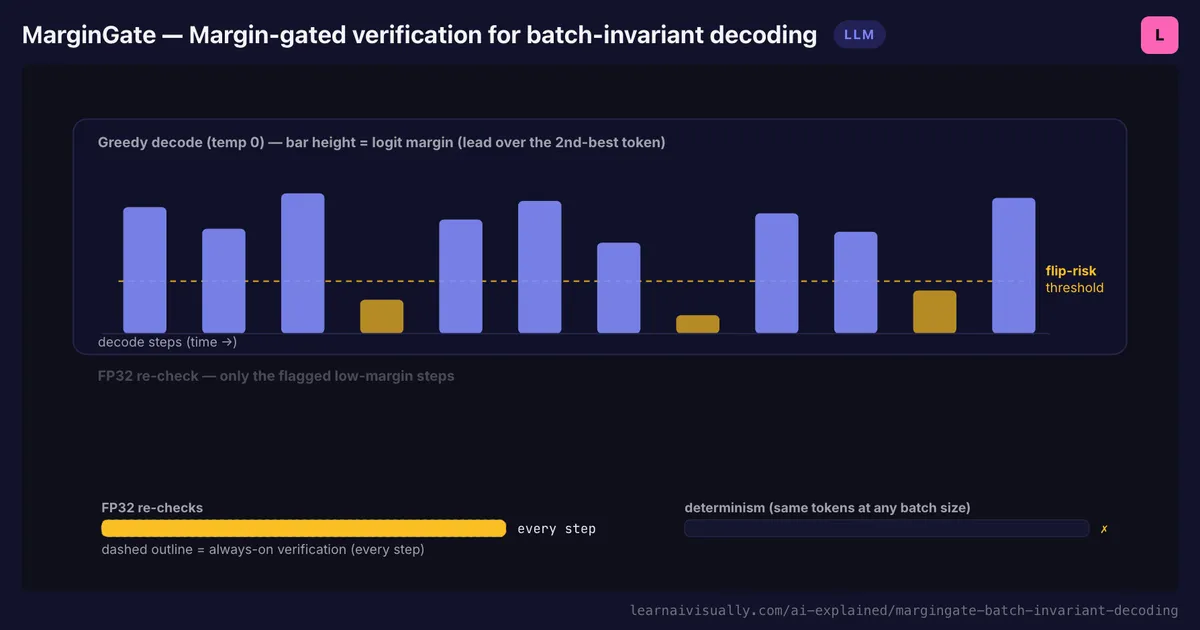
طبق اعلام نویسندگان مقاله، MarginGate روی «حاشیه لوجیت» (Logit Margin) تمرکز میکند؛ یعنی فاصله بین امتیاز اولین و دومین توکن در هر گام رمزگشایی. وقتی این حاشیه زیاد است، برنده قطعی و بدون ابهام است و نوسانات عددی BF16 تأثیری در نتیجه نهایی نخواهد داشت. این گامها از یک «لاین سریع» با استفاده از همان BF16 استاندارد عبور داده میشوند.
اما وقتی حاشیه بسیار کوچک است — یعنی دو توکن تقریباً امتیاز برابری دارند و در وضعیت تساوی نزدیک هستند — گام مورد نظر برای «بازرسی ثانویه» علامتگذاری میشود. تنها این گامهای پراکنده و پرریسک در فرمت دقیق FP32 بازمحاسبه میشوند تا تضمین شود توکن درست انتخاب شده است. این ساختار «تأیید و سپس اصلاح» دقیقاً مشابه روش مورد استفاده در رمزگشایی گمانهزن (Speculative Decoding) است.
جزئیات: پیادهسازی فنی
جزئیات پیادهسازی فنی به شرح زیر است:
- لاین سریع (BF16): گامهای با حاشیه بالا را مدیریت میکند. سیستم فرض میکند نتیجه BF16 درست است چون فاصله با توکن دوم آنقدر زیاد است که خطای رند کردن نمیتواند برنده را تغییر دهد.
- بازرسی ثانویه (FP32): گامهای با حاشیه پایین را مدیریت میکند. سیستم گام را در FP32 بازمحاسبه میکند تا برنده واقعی را بیابد.
- بازگرداندن تغییرناپذیری دسته: با استفاده از FP32 به عنوان حقیقت مطلق (Ground Truth) برای موارد مرزی، درخواست تولید توکنهای یکسانی میکند، فارغ از اینکه چه تعداد درخواست دیگر در دسته GPU آن حضور دارند.
- ترمیم ستونهای حافظه K/V: اگر بازبینی مورد اعتماد FP32 تشخیص دهد که BF16 توکن غلطی انتخاب کرده است، MarginGate فقط توکن را عوض نمیکند، بلکه وضعیت را ترمیم میکند. این سیستم ستون مربوط به حافظه K/V (کلیدها و مقادیر کششده از توکنهای قبلی) را جایگزین میکند تا تمام توکنهای بعدی در توالی با مسیر اصلاحشده سازگار و سازگار باقی بمانند.
دادههای عملکرد و دقت
بر اساس مستندات مقاله، نرخ واقعی تغییر توکنها (Token Flips) بسیار پایین است و بین ۰.۳٪ تا ۱.۳٪ از کل گامها اندازهگیری شده است. برای مثال، در مدل Llama-3.1-8B با استفاده از مجموعه داده MATH500، نرخ تغییر تنها ۰.۴۸٪ بود. این یعنی در یک توالی معمولی، تنها چند توکن واقعاً تغییر میکردند.
با وجود نادر بودن این تغییرات، MarginGate معمولاً ۱۵٪ تا ۱۸٪ از گامها را برای بازبینی علامتگذاری میکند. در یک تکمیل ۱۰۰۰ توکنی به عنوان مثال، حدود ۱۸۰ گام در FP32 بازبینی میشوند و ۸۲۰ گام در لاین سریع BF16 میمانند. از این ۱۸۰ گام علامتگذاری شده، تنها ۳ تا ۱۳ توکن (بر اساس نرخ تغییر ۰.۳ تا ۱.۳ درصدی) واقعاً اصلاح میشوند.
این رویکرد انتخابی منجر به بهرهوری بسیار بالا نسبت به بازبینی «همیشگی» FP32 میشود. پژوهشگران گزارش دادهاند که MarginGate سربار بازبینی را تقریباً ۲ برابر کاهش میدهد — به طور دقیقتر ۲.۲۳ برابر و ۱.۹۹ برابر در تستهای آنها — در حالی که قطعیت ۱۰۰ درصدی توالی را در مدلهایی مثل Llama-3.1-8B و Qwen2.5-14B حفظ میکند.
مقایسه استراتژیهای رمزگشایی
| استراتژی | گامهای بازبینی شده | قطعیت (Determinism) | سربار نسبی |
|---|---|---|---|
| اعتماد به BF16 | هیچ | ✗ (بسته به دسته) | ۱× (پایه) |
| FP32 همیشگی | هر گام | ✓ ۱۰۰٪ | ~۲ برابر گیت (مقاله) |
| MarginGate | ~۱۵–۱۸٪ | ✓ ۱۰۰٪ | ~۲ برابر کمتر از FP32 همیشگی (۲.۲۳× / ۱.۹۹×) |
این تغییر ثابت میکند که دمای صفر صرفاً یک قانون نمونهبرداری است، نه تضمینی برای دقت محاسباتی. این روش قانون نمونهبرداری را اصلاح میکند، اما مشکل محاسبات زیربنایی را حل نمیکرد. با گیتگذاری روی حاشیه، سیستم از بیاعتمادی به تمام توکنها اجتناب کرده و تنها زمانی دخالت میکند که توکن واقعاً «در وضعیت تردید» باشد.
برای مهندسان، این بدان معناست که تضاد بین سرعت (BF16) و صحت (FP32) دیگر یک انتخاب صفر و یک نیست. اکنون میتوانید دقت اعشاری ۳۲ بیتی را در جاهایی که واقعاً اهمیت دارد داشته باشید، بدون اینکه نرخ پردازش (Throughput) استنتاج ۱۶ بیتی را فدا کنید.
اگر برای سرویسدهی با نرخ پردازش بالا بهینهسازی میکنید، باید حاشیههای لوجیت (Logit Margins) ورکلود خود را رصد کنید تا ببینید چه تعداد از درخواستهای شما در این وضعیتهای مرزی قرار میگیرند. گام بعدی، رصد ادغام بازبینی MarginGate در فریمورکهای محبوب استنتاج مانند vLLM یا TensorRT-LLM است.
گام بعدی شما
- اگر از سرویسهای استنتاج با نرخ بالا استفاده میکنید، حاشیههای لوجیت (Logit Margins) ورکلود خود را رصد کنید تا ببینید چه تعداد از درخواستهای شما در وضعیت مرزی قرار میگیرند.
- منتظر ادغام مکانیزم بازبینی MarginGate در فریمورکهای محبوب استنتاج مانند vLLM یا TensorRT-LLM باشید.
- در ارزیابیهای مدل (Evals)، تفاوت خروجیها را در اندازههای مختلف دسته تست کنید تا میزان اثرپذیری مدل خود از نوسانات BF16 را بسنجید.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو