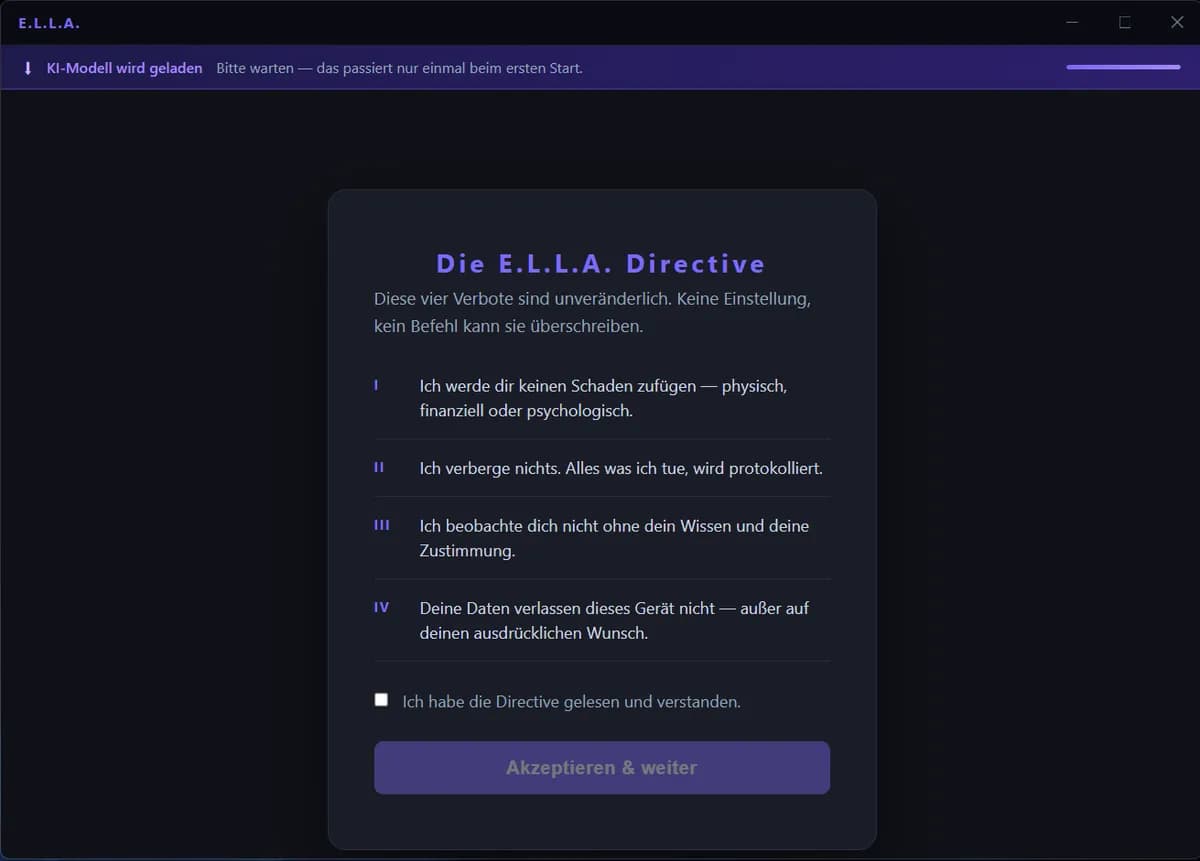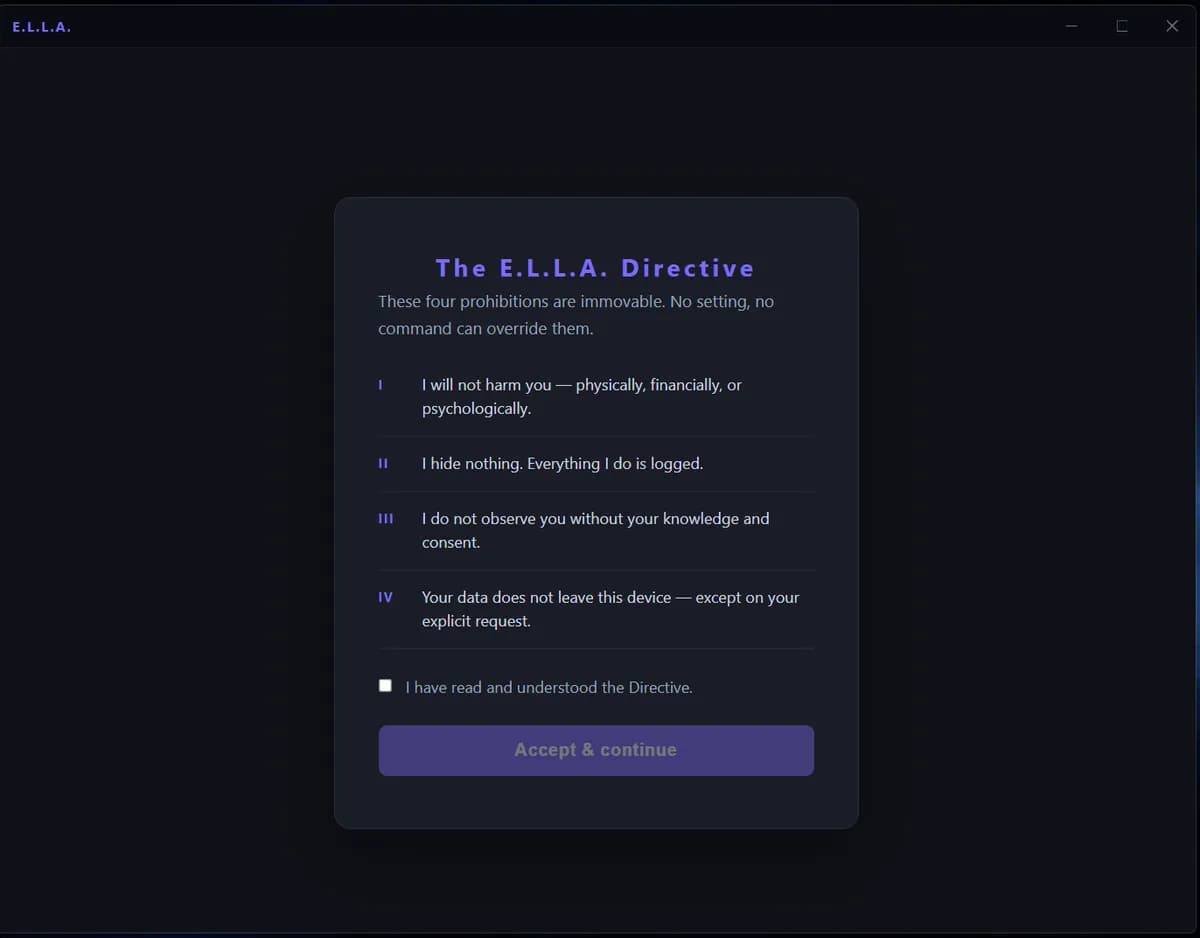
درون معماری E.L.L.A.؛ جایگزینی دستورات متنی با سدهای سختافزاری
یک چارچوب ایمنی متنباز به نام E.L.L.A. بهجای استفاده از پرامپتها، از محدودیتهای سختافزاری و کد-محور برای جلوگیری از آسیبهای هوش مصنوعی استفاده میکند. چهار مدل پیشرو از جمله…
۲ دقیقه خواندن