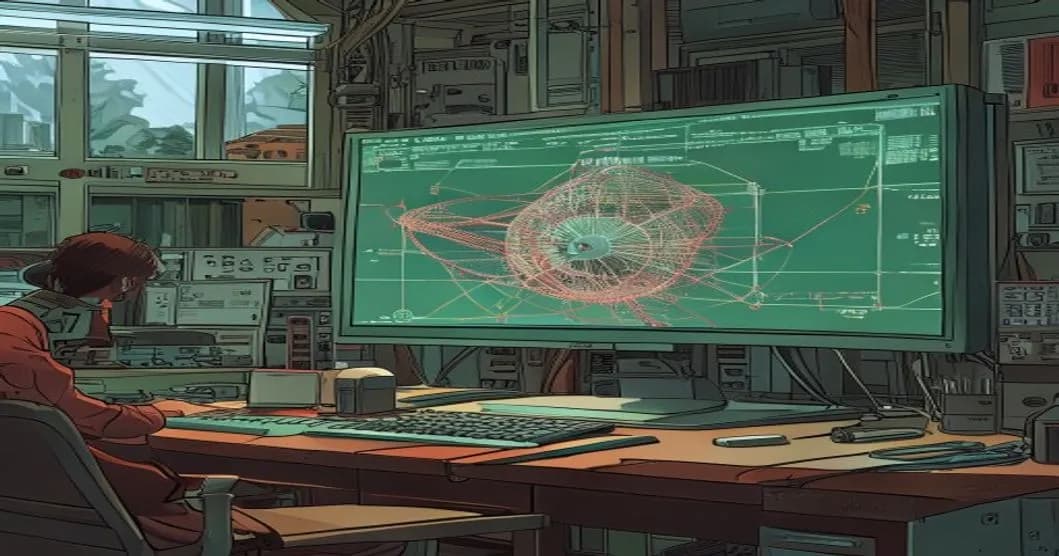
کاهش خطای طراحی مولکولی به ۰.۰۰۰۳ الکترون-ولت با بازخورد استدلالی LLM
پژوهشگران چارچوبی برای مدلهای زبانی ابداع کردهاند که به جای امتیازدهی ساده، از منطق فیزیکوشیمیایی برای طراحی مولکولها استفاده میکند. این روش در وظایف متوسط به موفقیت ۱۰۰ درصدی…
۱ دقیقه خواندن