
اگر در حال حاضر با توهمات مدل در پاسخ به اسناد طولانی دستوپنجه نرم میکنید، احتمالاً مشکل از مدل نیست، بلکه از نحوه خرد کردن دادههای شماست. وقتی یک سیستم بازیابی، تکههایی از متن را برمیگرداند که ایدههای اصلی در آنها قطع شده است، مدل زبانی مجبور میشود برای پر کردن شکافها، اطلاعات جعلی بسازد.
این چالش دقیقاً همان نقطهای است که تفاوتهای میان جستوجوی زنده و حافظه ایستا در سیستمهای RAG نمایان میشود تا توهمات مدل به حداقل برسد.
طبق گزارشی که ۲۵ ژوئن ۲۰۲۶ در وبسایت dev.to منتشر شد، راهکار جدید عبور از تقسیمبندیهای ایستا به سمت تکهبندی عاملمحور (Agentic Chunking) است.

bسیاری از توسعهدهندگان از تقسیمبندی با اندازه ثابت یا مرزهای معنایی ساده استفاده میکنند. این روشها مثل قیچی عمل میکنند و اغلب ایدهها را از وسط میبرند یا مفاهیمی بیربط را با هم ترکیب میکنند. تصور کنید پایگاه دانشی دارید که حقایقی درباره «ذرت تازه»، «تورتلا ذرت» و «شربت ذرت» دارد؛ یک تکهبند سنتی اینها را با هم مخلوط میکند و پاسخی درباره «میانوعدههای سالم» را با دادههای مربوط به شربت ذرت مسموم میکند.
همانطور که در تحلیلهای پیشین ما درباره امنیت و دقت مدلهای بازیابی اشاره کردیم، کیفیت ورودی تعیینکننده کیفیت خروجی است. تکهبندی عاملمحور مانند یک ویراستار حرفهای عمل میکند و از یک حلقه عملیاتی مبتنی بر مقاله Dense X Retrieval استفاده میکند. این روش بهجای جملات کامل، ابتدا «گزارههای اتمیک» — یعنی کوچکترین واحدهای یک ادعای واقعی — را استخراج میکند.
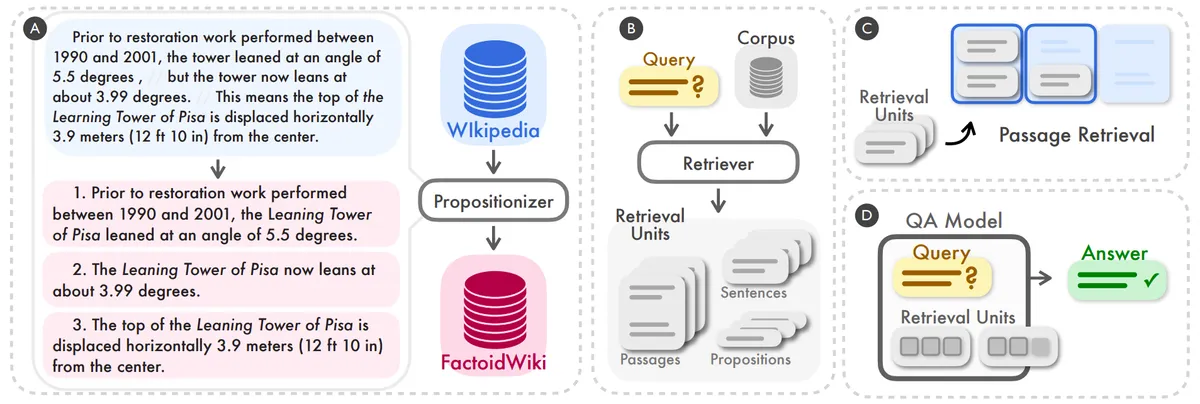
این فرآیند بر اساس مستندات فنی شامل سه گام کلیدی است:
- استخراج گزاره: مدلهای زبانی اسناد را به واقعیتهای بسیار ریز تبدیل میکنند.
- تخصیص پویا: یک عامل (Agent) — شبکهای از دستورالعملها که مثل یک تصمیمگیرنده عمل میکند — تشخیص میدهد که آیا یک گزاره به تکه موجود تعلق دارد یا باید گروه جدیدی ایجاد شود.
- تکامل متاداده: عنوانها و خلاصهها بهصورت خودکار بهروزرسانی میشوند تا رتبهبندی نتایج بهبود یابد.
برای پیادهسازی، پرامپتهای جامعه توسعهدهندگان اکنون از طریق kumja/proposal-indexing در LangSmith Hub در دسترس است. توسعهدهندگان میتوانند برای تخصیص تکهها از مدلهای کوچکتر مثل Claude 3 Haiku یا GPT-4o-mini استفاده کنند و مدلهای بزرگتر را برای تولید خلاصههای باکیفیت رزرو نمایند.
این تغییر، پیشفرضهای پیشپردازش در تولید بازیابیافزا (RAG) — شبیه دانشآموزی که قبل از جواب دادن، اول کتاب را باز میکند تا دقیقاً نقلقول بگیرد — را تغییر میدهد. با اولویت دادن به معنا بهجای تعداد توکن (Token) — تکههای کوچکی از متن شبیه برشهای کیک — این روش دقت را بهشدت افزایش میدهد.
بهترین مسیر برای پردازش لحظهای این است که ابتدا برای سرعت از تکهبندی معنایی استفاده کنید و سپس تکهبندی عاملمحور را بهصورت نامتقارن در پسزمینه اجرا کنید. این کار باعث میشود کیفیت بازیابی بالا برود بدون اینکه تأخیر (Latency) در لحظه بارگذاری فایل ایجاد شود.
اگر یادداشتهای پژوهشی طولانی یا موضوعات متداخل را مدیریت میکنید که اشتباه در آنها پیامدهای جدی دارد، هزینه استنتاج اضافی برای ایندکسگذاری، سرمایهگذاری لازم برای رسیدن به استانداردهای صنعتی است.
گام بعدی شما
- بررسی مخزن kumja/proposal-indexing برای استقرار سریع این متد.
- تست مدلهای کوچک (Small Language Models) برای کاهش هزینه تخصیص تکهها.
- پیادهسازی لایه پردازش نامتقارن (Asynchronous) برای حفظ سرعت تجربه کاربری.
اما تأثیر این متد بر مدیریت حافظه بلندمدت عاملها حتی پیچیدهتر است؛ در تحلیل ما درباره پروتکل MCP این موضوع را بررسی کنید.



گفتگو